torch_geometric笔记:数据集 ENZYMES &Minibatches
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了torch_geometric笔记:数据集 ENZYMES &Minibatches相关的知识,希望对你有一定的参考价值。
Pytorch Geometric中包含大量的常见基准数据集。在初始化数据集的时候,框架会自动下载数据集的原始文件,并将其处理为Data对象。例如要下载ENZYMES数据集(由600个graph划分为6个类别)
1 下载数据集
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='', name='ENZYMES')
dataset
#ENZYMES(600)
type(dataset)
#torch_geometric.datasets.tu_dataset.TUDataset
len(dataset)
#600
#说明600张图
dataset.num_classes
#6
#图一共有6各不同的类
dataset.num_node_features
#3 每一个节点有三个特征
data = dataset[0]
data
#Data(edge_index=[2, 168], x=[37, 3], y=[1])
#第一张图有168条有向边,37个节点,每个节点3个特征,整张图有一个类别
data.is_undirected()
#True2 Mini-batches
神经网络通常以batch的方式进行训练,geometric在mini-batch实现了并行化,这种组合允许在一个batch中使用不同数量的边和节点。
在torch_geometric.data.DataLoader中,已经包含了此过程。
这种mini-batch的操作本质上来说是将一个batch的graph看成是一个大的graph,由此,无论batch size是多少,其将所有的操作都统一在一个大图上进行操作。
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoader
dataset = TUDataset(root='', name='ENZYMES', use_node_attr=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for batch in loader:
print(batch,batch.num_graphs)
'''
Batch(edge_index=[2, 3890], x=[1075, 21], y=[32], batch=[1075], ptr=[33]) 32
Batch(edge_index=[2, 4284], x=[1157, 21], y=[32], batch=[1157], ptr=[33]) 32
Batch(edge_index=[2, 4098], x=[1086, 21], y=[32], batch=[1086], ptr=[33]) 32
Batch(edge_index=[2, 3668], x=[916, 21], y=[32], batch=[916], ptr=[33]) 32
Batch(edge_index=[2, 4062], x=[1074, 21], y=[32], batch=[1074], ptr=[33]) 32
Batch(edge_index=[2, 4086], x=[1096, 21], y=[32], batch=[1096], ptr=[33]) 32
Batch(edge_index=[2, 3954], x=[1005, 21], y=[32], batch=[1005], ptr=[33]) 32
Batch(edge_index=[2, 4170], x=[1064, 21], y=[32], batch=[1064], ptr=[33]) 32
Batch(edge_index=[2, 4258], x=[1149, 21], y=[32], batch=[1149], ptr=[33]) 32
Batch(edge_index=[2, 3836], x=[997, 21], y=[32], batch=[997], ptr=[33]) 32
Batch(edge_index=[2, 3886], x=[1016, 21], y=[32], batch=[1016], ptr=[33]) 32
Batch(edge_index=[2, 4066], x=[1042, 21], y=[32], batch=[1042], ptr=[33]) 32
Batch(edge_index=[2, 3946], x=[1046, 21], y=[32], batch=[1046], ptr=[33]) 32
Batch(edge_index=[2, 3656], x=[927, 21], y=[32], batch=[927], ptr=[33]) 32
Batch(edge_index=[2, 4110], x=[1034, 21], y=[32], batch=[1034], ptr=[33]) 32
Batch(edge_index=[2, 3824], x=[1002, 21], y=[32], batch=[1002], ptr=[33]) 32
Batch(edge_index=[2, 4178], x=[1116, 21], y=[32], batch=[1116], ptr=[33]) 32
Batch(edge_index=[2, 3736], x=[974, 21], y=[32], batch=[974], ptr=[33]) 32
Batch(edge_index=[2, 2856], x=[804, 21], y=[24], batch=[804], ptr=[25]) 24
'''以 Batch(edge_index=[2, 3890], x=[1075, 21], y=[32], batch=[1075], ptr=[33]) 为例:
- edge_index=[2, 3890]——这个batch一共3890条边
- x=[1075, 21]——整个batch的节点特征矩阵,这个batch一共2075个点,至于这个21,我不太明白,是因为不同的图有不同的特征,所以拼起来一共21个不同的特征吗?欢迎大家在评论区指正!
- y=[32]——32个图,32维特征
- batch=[1075]——batch是一个列向量,它将每个节点映射到该batch中的对应的graph:
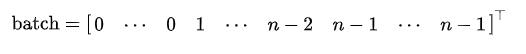
2.1 自己的图列表 &DataLoader
不难发现,这种下载的数据集,可以看成是图的集合
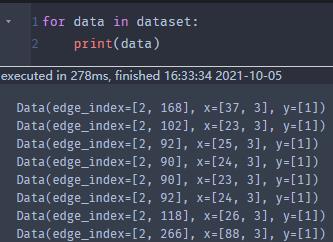
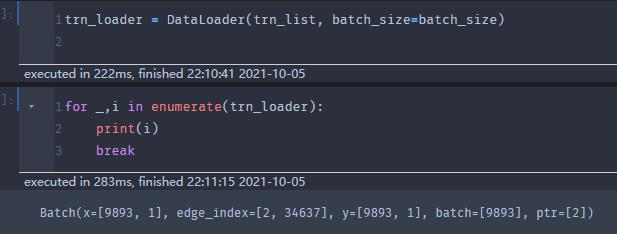
那么如果我门自己设计了一些图,集合成一个列表,我们可以直接用这个列表构造DataLoader(注:这里的DataLoader是torch_geometric.loader的DataLoader)
以上是关于torch_geometric笔记:数据集 ENZYMES &Minibatches的主要内容,如果未能解决你的问题,请参考以下文章