[Pytorch系列-26]:神经网络基础 - 多个带激活函数的神经元实现非线性回归
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Pytorch系列-26]:神经网络基础 - 多个带激活函数的神经元实现非线性回归相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120600621
目录
前言 深度学习模型框架
 https://blog.csdn.net/HiWangWenBing/article/details/120462734
https://blog.csdn.net/HiWangWenBing/article/details/120462734第1章 业务领域分析
1.1 步骤1-1:业务领域分析
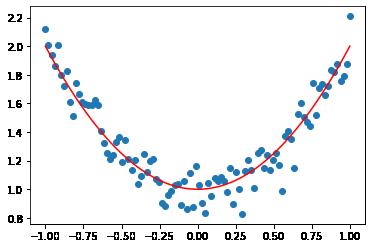
非线性回归,样本是带噪声的数据。
从样本数据可以看出,内在的规律可能是一个抛物线,但肯定一元一次的函数(直线)
因此,这是非线性回归问题。
1.2 步骤1-2:业务建模

单个神经元是都输入和单个输出。
可以构建两层的神经网络:
(1)隐藏层1:
- 一维的输入属性X
- 多个并行的神经元,这里初步选10个神经元
- 每个神经元有一个激活函数relu
(2)输出层:
- 由于是单输入,因此输出层只需要一个神经元即可。
1.3 代码实例前置条件
#环境准备
import numpy as np # numpy数组库
import math # 数学运算库
import matplotlib.pyplot as plt # 画图库
import torch # torch基础库
import torch.nn as nn # torch神经网络库
import torch.nn.functional as F # torch神经网络库
print("Hello World")
print(torch.__version__)
print(torch.cuda.is_available())Hello World 1.8.0 False
第2章 前向运算模型定义
2.1 步骤2-1:数据集选择
这里不需要采用已有的开源数据集,只需要自己构建数据集即可。
#2-1 准备数据集
#x_sample = torch.linspace(-1, 1, 100).reshape(-1, 1) 或者
x_sample = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
#噪声服从正态分布
noise = torch.randn(x_sample.size())
y_sample = x_sample.pow(2) + 1 + 0.1 * noise
y_line = x_sample.pow(2) + 1
#可视化数据
print(x_sample.shape)
print(y_sample.shape)
print(y_line.shape)
plt.scatter(x_sample.data.numpy(), y_sample.data.numpy())
plt.plot(x_sample, y_line,'green')torch.Size([100, 1]) torch.Size([100, 1]) torch.Size([100, 1])
Out[51]:
[<matplotlib.lines.Line2D at 0x279b8d43130>]

2.2 步骤2-2:数据预处理
# 2-2 对数据预处理
x_train = x_sample
y_train = y_sample2.3 步骤2-3:神经网络建模
# 2-3 定义网络模型
class Net(torch.nn.Module):
# 定义神经网络
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
#定义隐藏层L1
# n_feature:输入属性的维度
# n_hidden: 神经元的个数 = 输出属性的个数
self.hidden = torch.nn.Linear(n_feature, n_hidden)
#定义输出层:
# n_hidden:输入属性的维度
# n_output: 神经元的个数 = 输出属性的个数
self.predict = torch.nn.Linear(n_hidden, n_output)
#定义前向运算
def forward(self, x):
h1 = self.hidden(x)
s1 = F.relu(h1)
out = self.predict(s1)
return out
model = Net(1,10,1)
print(model)
print(model.parameters)
print(model.parameters())Net( (hidden): Linear(in_features=1, out_features=10, bias=True) (predict): Linear(in_features=10, out_features=1, bias=True) ) <bound method Module.parameters of Net( (hidden): Linear(in_features=1, out_features=10, bias=True) (predict): Linear(in_features=10, out_features=1, bias=True) )> <generator object Module.parameters at 0x00000279B78BC820>
2.4 步骤2-4:神经网络输出
# 2-4 定义网络预测输出
y_pred = model.forward(x_train)
print(y_pred.shape)torch.Size([100, 1])
第3章 后向运算模型定义
3.1 步骤3-1:定义loss函数
这里采用的MSE loss函数
# 3-1 定义loss函数:
# loss_fn= MSE loss
loss_fn = nn.MSELoss()
print(loss_fn)MSELoss()
3.2 步骤3-2:定义优化器
# 3-2 定义优化器
Learning_rate = 0.01 #学习率
# optimizer = SGD: 基本梯度下降法
# parameters:指明要优化的参数列表
# lr:指明学习率
optimizer = torch.optim.SGD(model.parameters(), lr = Learning_rate)
print(optimizer)SGD (
Parameter Group 0
dampening: 0
lr: 0.01
momentum: 0
nesterov: False
weight_decay: 0
)
3.3 步骤3-3:模型训练
# 3-3 模型训练
# 定义迭代次数
epochs = 5000
loss_history = [] #训练过程中的loss数据
y_pred_history =[] #中间的预测结果
for i in range(0, epochs):
#(1) 前向计算
y_pred = model(x_train)
#(2) 计算loss
loss = loss_fn(y_pred, y_train)
#(3) 反向求导
loss.backward()
#(4) 反向迭代
optimizer.step()
#(5) 复位优化器的梯度
optimizer.zero_grad()
# 记录训练数据
loss_history.append(loss.item())
y_pred_history.append(y_pred.data)
if(i % 1000 == 0):
print('epoch {} loss {:.4f}'.format(i, loss.item()))
print("\\n迭代完成")
print("final loss =", loss.item())
print(len(loss_history))
print(len(y_pred_history))epoch 0 loss 0.5406 epoch 1000 loss 0.0303 epoch 2000 loss 0.0159 epoch 3000 loss 0.0148 epoch 4000 loss 0.0141 迭代完成 final loss = 0.013485318049788475 5000 5000
3.4 步骤3-4:模型验证
NA
3.5 步骤3-5:模型可视化
(1)前向数据
# 3-4 可视化模型数据
#model返回的是总tensor,包含grad_fn,用data提取出的tensor是纯tensor
y_pred = model.forward(x_train).data.numpy().squeeze()
print(x_train.shape)
print(y_pred.shape)
print(y_line.shape)
plt.scatter(x_train, y_train, label='SampleLabel')
plt.plot(x_train, y_pred, color ="red", label='Predicted')
plt.plot(x_train, y_line, color ="green", label ='Line')
plt.legend()
plt.show()torch.Size([100, 1]) (100,) torch.Size([100, 1])

备注:
从如上的几何图形可以看出:
- 人工神经网络模型的拟合图形与抛物线接近,但并不平滑。
(2)后向loss值迭代过程
#显示loss的历史数据
plt.plot(loss_history, "r+")
plt.title("loss value")
(3)前向预测函数的迭代过程
for i in range(0, len(y_pred_history)):
if(i % 100 == 0):
plt.scatter(x_train, y_train, color ="black", label='SampleLabel')
plt.plot(x_train, y_pred_history[i], label ='Line')
plt.plot(x_train, y_line, color ="green", label ='Line', linewidth=4)
plt.plot(x_train, y_pred, color ="red", label='Predicted', linewidth=4)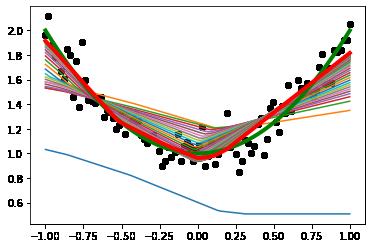
从上图,可以清晰的看出,前向预测函数,如何一步步收敛到最终的图形的。
其中:
红色图形:迭代后的图形
绿色图形:解析函数的图形
其他图形:中间迭代的图形
第4章 模型部署
4.1 步骤4-1:模型部署
NA
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120600621
以上是关于[Pytorch系列-26]:神经网络基础 - 多个带激活函数的神经元实现非线性回归的主要内容,如果未能解决你的问题,请参考以下文章