Elasticsearch:Ingest Pipeline 实践
Posted 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:Ingest Pipeline 实践相关的知识,希望对你有一定的参考价值。
相比较 Logstash 而言,由于其丰富的 processors 而受到越来越多人的喜欢。最重要的一个优点就是它基于 Elasticsearch 极具可拓展性和维护性而受到开发者的喜欢。我在之前创建了很多关于 Ingest Pipeline 的文章。你可以参阅文章 “Elastic:菜鸟上手指南” 中的 Ingest pipeline 章节。
在今天的文章中,我想同一个一个例子来展示两种创建 Ingest Pipeline 的方法尽管在我之前的文章中都有介绍:
- 通过 API 的方法来创建
- 通过 Kibana 的界面来进行创建
通过 API 的方法来创建
通过 API 的方法来创建其实也是非常容易和直接的。在今天的练习中,我将使用一个简单的文档来说明:
PUT demo/_doc/1
{
"@timestamp": "2021-06-18T18:50:53",
"message": "950020004L-1,1,Rue du Clos Saint-Martin,95450,Ableiges,OSM,49.06789,1.969323"
}在上面的文档中,我们可以看到 message 字段是一个非结构化的数据。这个数据用结构化的语句可以表述为:
_id
address.number
address.street_name
address.zipcode
address.city
source
location.lat
location.lon为了能够使得数据在 Kibana 中得到更好的搜索及展示,我们需要把上面的数据进行结构化。我们使用 API 的方法有几种。我们首先能够想到的就是这个数据的每一项是由一个逗号分开,所以我们想到使用 split 处理器。我们可以通过如下的方式来测试我们的 Pipeline:
POST _ingest/pipeline/_simulate
{
"description": "interpret a message",
"pipeline": {
"processors": [
{
"split": {
"field": "message",
"separator": ","
}
},
{
"set": {
"field": "_id",
"value": "{{message.0}}"
}
},
{
"set": {
"field": "address.number",
"value": "{{message.1}}"
}
},
{
"set": {
"field": "address.street_name",
"value": "{{message.2}}"
}
},
{
"set": {
"field": "address.zipcode",
"value": "{{message.3}}"
}
},
{
"set": {
"field": "address.city",
"value": "{{message.4}}"
}
},
{
"set": {
"field": "source",
"value": "{{message.5}}"
}
},
{
"set": {
"field": "location.lat",
"value": "{{message.6}}"
}
},
{
"set": {
"field": "location.lon",
"value": "{{message.7}}"
}
},
{
"remove": {
"field": "message"
}
}
]
},
"docs": [
{
"_source": {
"message": "950020004L-1,1,Rue du Clos Saint-Martin,95450,Ableiges,OSM,49.06789,1.969323"
}
}
]
}我们在 Kibana 的 console 中运行,我们可以看到如下的输出:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "950020004L-1",
"_source" : {
"location" : {
"lon" : "1.969323",
"lat" : "49.06789"
},
"address" : {
"zipcode" : "95450",
"number" : "1",
"city" : "Ableiges",
"street_name" : "Rue du Clos Saint-Martin"
},
"source" : "OSM"
},
"_ingest" : {
"timestamp" : "2021-06-22T07:21:30.694064Z"
}
}
}
]
}从输出中,我们可以看到之前的 message 字段完全变成了结构化的字段。基于上面的测试,我们可以定义如下的 Pipeline:
PUT _ingest/pipeline/decode
{
"processors": [
{
"split": {
"field": "message",
"separator": ","
}
},
{
"set": {
"field": "_id",
"value": "{{message.0}}"
}
},
{
"set": {
"field": "address.number",
"value": "{{message.1}}"
}
},
{
"set": {
"field": "address.street_name",
"value": "{{message.2}}"
}
},
{
"set": {
"field": "address.zipcode",
"value": "{{message.3}}"
}
},
{
"set": {
"field": "address.city",
"value": "{{message.4}}"
}
},
{
"set": {
"field": "source",
"value": "{{message.5}}"
}
},
{
"set": {
"field": "location.lat",
"value": "{{message.6}}"
}
},
{
"set": {
"field": "location.lon",
"value": "{{message.7}}"
}
},
{
"remove": {
"field": "message"
}
}
]
}当我们导入数据时,我们可以使用如下的方式来进行调用:
PUT demo/_doc/1?pipeline=decode
{
"@timestamp": "2021-06-18T18:50:53",
"message": "950020004L-1,1,Rue du Clos Saint-Martin,95450,Ableiges,OSM,49.06789,1.969323"
}这样我们的文档就变成了:
GET demo/_doc/950020004L-1请注意在之前的 processor 中,我们重新设置了_id。它被设置为 message 的第一个字段值。
{
"_index" : "demo",
"_type" : "_doc",
"_id" : "950020004L-1",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"@timestamp" : "2021-06-18T18:50:53",
"address" : {
"zipcode" : "95450",
"number" : "1",
"city" : "Ableiges",
"street_name" : "Rue du Clos Saint-Martin"
},
"location" : {
"lon" : "1.969323",
"lat" : "49.06789"
},
"source" : "OSM"
}
}上面显示它正是我们需要的结果。
在上面,可能有的人觉得里面用的 processor 确实太大,有没有更好的办法呢?我们可以参考我之前的文章 “Elastic可观测性 - 运用 pipeline 使数据结构化”。我们可以使用 dissect 处理器来完成。
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"dissect": {
"field": "message",
"pattern": "%{_id},%{address.number},%{address.street_name},%{address.zipcode},%{address.city},%{source},%{location.lat},%{location.lon}"
}
},
{
"remove": {
"field": "message"
}
}
]
},
"docs": [
{
"_source": {
"message": "950020004L-1,1,Rue du Clos Saint-Martin,95450,Ableiges,OSM,49.06789,1.969323"
}
}
]
}在上面,我们只使用了两个 processor,但是它同样达到了解析 message 字段的目的。上面的命令运行的结果是:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "950020004L-1",
"_source" : {
"location" : {
"lon" : "1.969323",
"lat" : "49.06789"
},
"address" : {
"zipcode" : "95450",
"number" : "1",
"city" : "Ableiges",
"street_name" : "Rue du Clos Saint-Martin"
},
"source" : "OSM"
},
"_ingest" : {
"timestamp" : "2021-06-22T07:36:19.674056Z"
}
}
}
]
}通过 Kibana 界面来完成 Pipeline
在 Kibana 中,它有一个设计非常好的界面让我们快速地设计并测试 Ingest Pipeline:



我们取名 Ingest Pipeline 为 interpret。点击上面的 Add a processor。在这次的练习中,我将使用 CSV 处理器:

我们按照上面的顺序填入 Target fields。点击 Add 按钮:

我们点击 Add documents:

在上面,我们可以看到需要测试的文档的格式。我们把如下的文件拷贝进去:
{
"_index" : "demo_csv",
"_id" : "Vb4IIHoBgxQVs4WbvcxH",
"_source" : {
"@timestamp" : "2021-06-18T18:50:58",
"message" : "950140640A-6,6,Rue des Prés,95580,Andilly,C+O,48.999518,2.299499"
}
}这样就变成了:
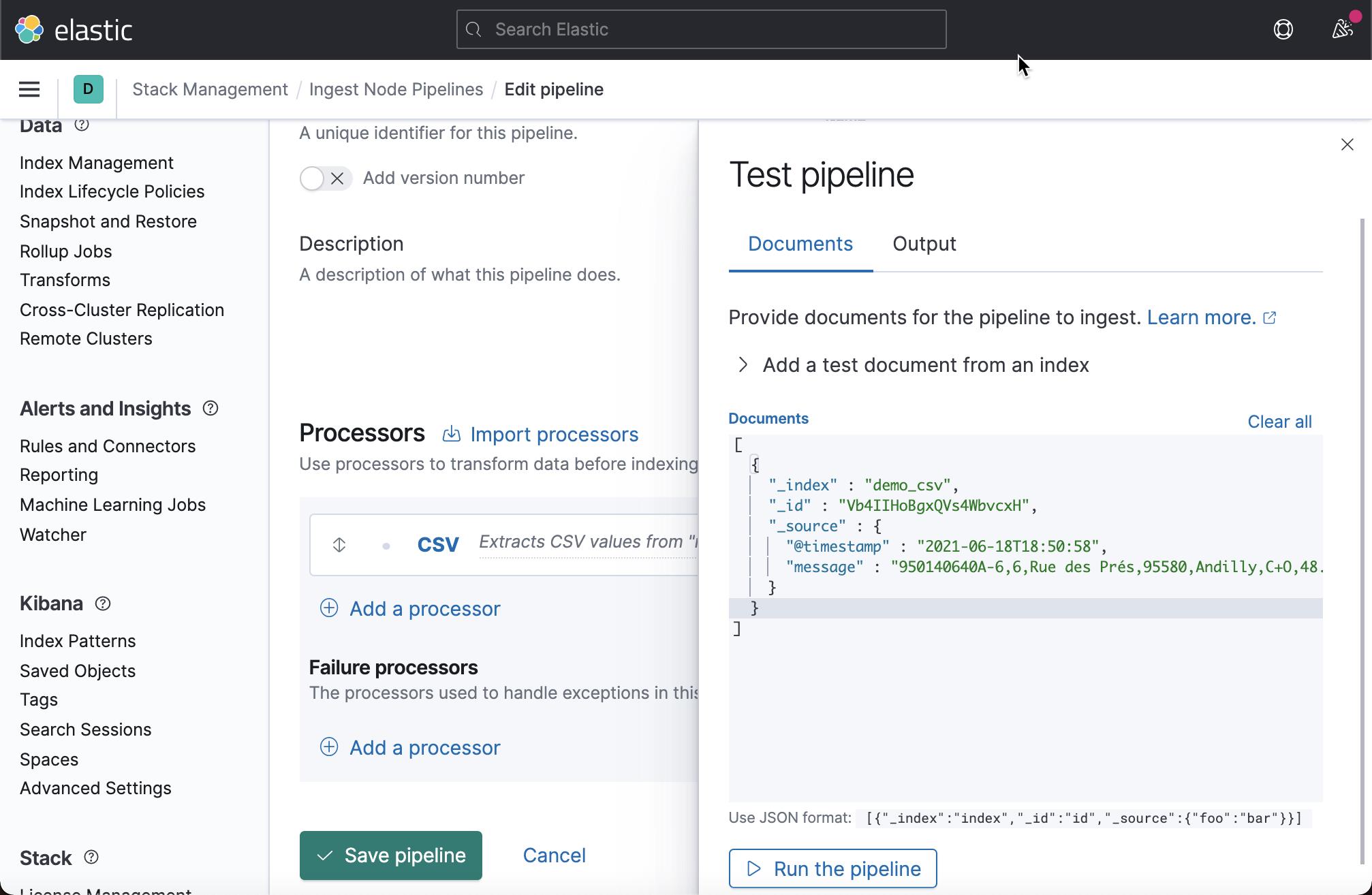


从上面的结果中,我们可以看出来是我们想要的结果。仔细查看,我们发现 location.lon 及 location.lat 是字符串。我们需要把它们进行转为为浮点数,这样才能表示经纬度。我们接着添加 convert 处理器:


同样地,我们针对 location.lat 也做一个转换。当我添加完毕后,我们直接点击 View output:

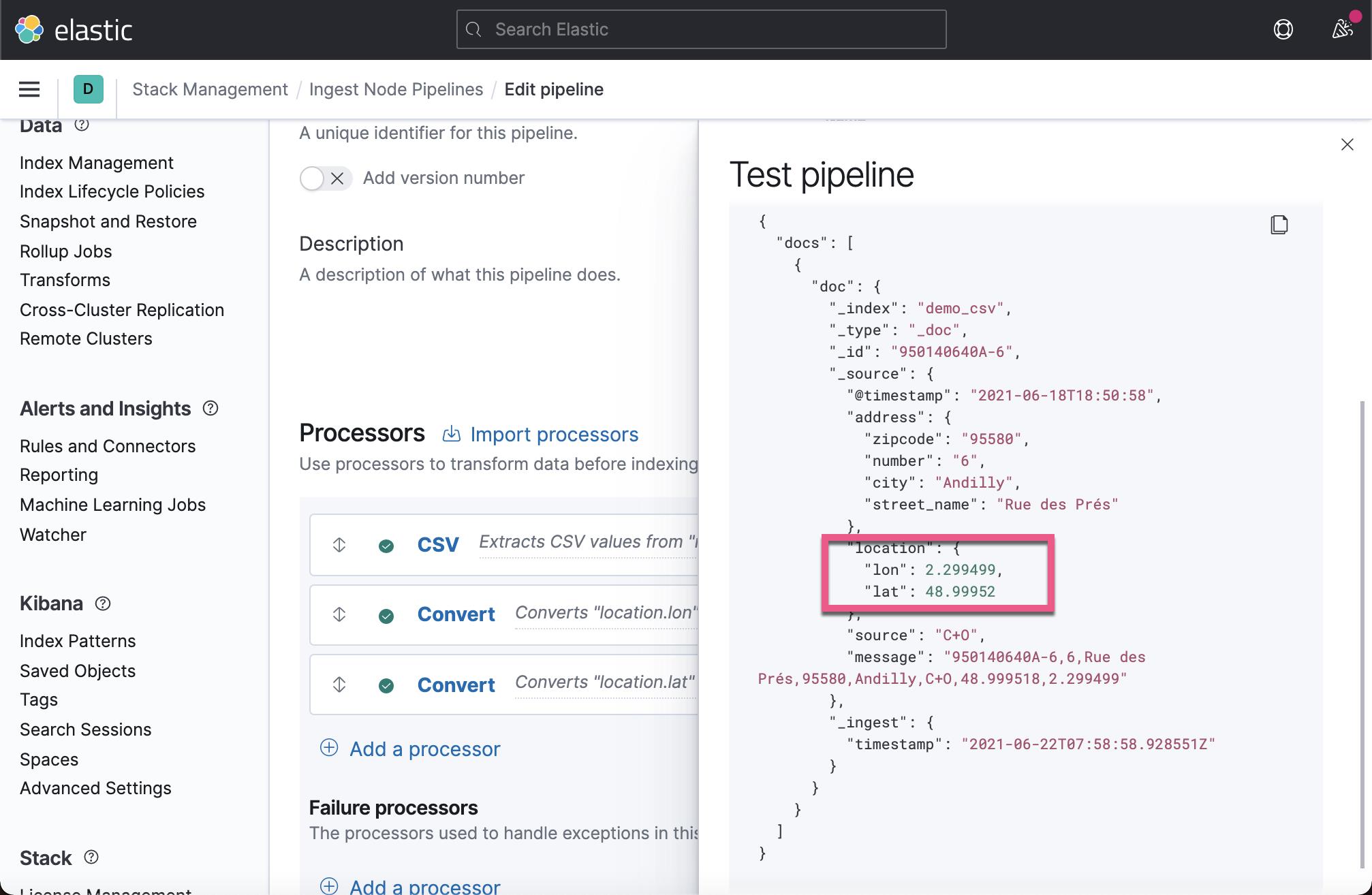
这次,我们看到 location.lon 及 location.lat 都变成了 float 类型的数据了。在上面,我们可以看到 message 字段还在,我们希望删除这个字段。我们接着添加一个 remove 处理器:

我们再次点击 View output:

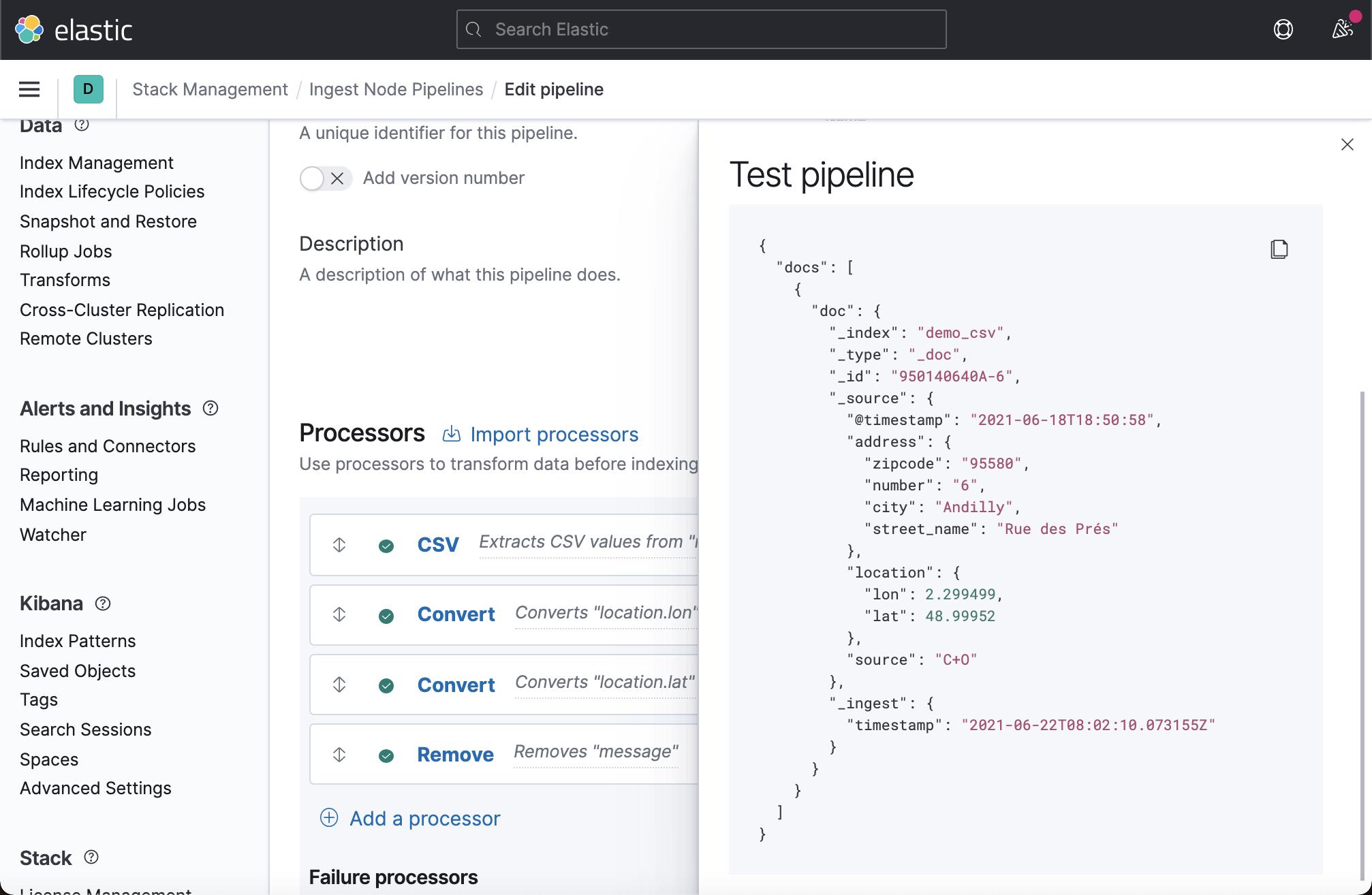
这次,我们看到没有 message 字段在输出中了。
在上面,我们看到所有的处理器都是按照我们规定的动作在处理。在实际的使用中,可能有时我们的数据并不是那么完美,这其中包括格式,或者数据类型。那么这些处理器可能会发生这样或者那样的错误。那么,我们该如何处理这些错误呢?
比如,当我们的测试文档是这样的一个格式:
{
"_index" : "demo_csv",
"_id" : "Vb4IIHoBgxQVs4WbvcxH",
"_source" : {
"@timestamp" : "2021-06-18T18:50:58",
"message" : "950140640A-6,6,Rue des Prés,95580,Andilly,C+O,NOT_NUM,NOT_NUM"
}
}
在上面,我们的经纬度不再是数值,而是一个不可以转换为数值的文字,那么我们该如何处理这个错误呢?我们重新运行 Pipeline:
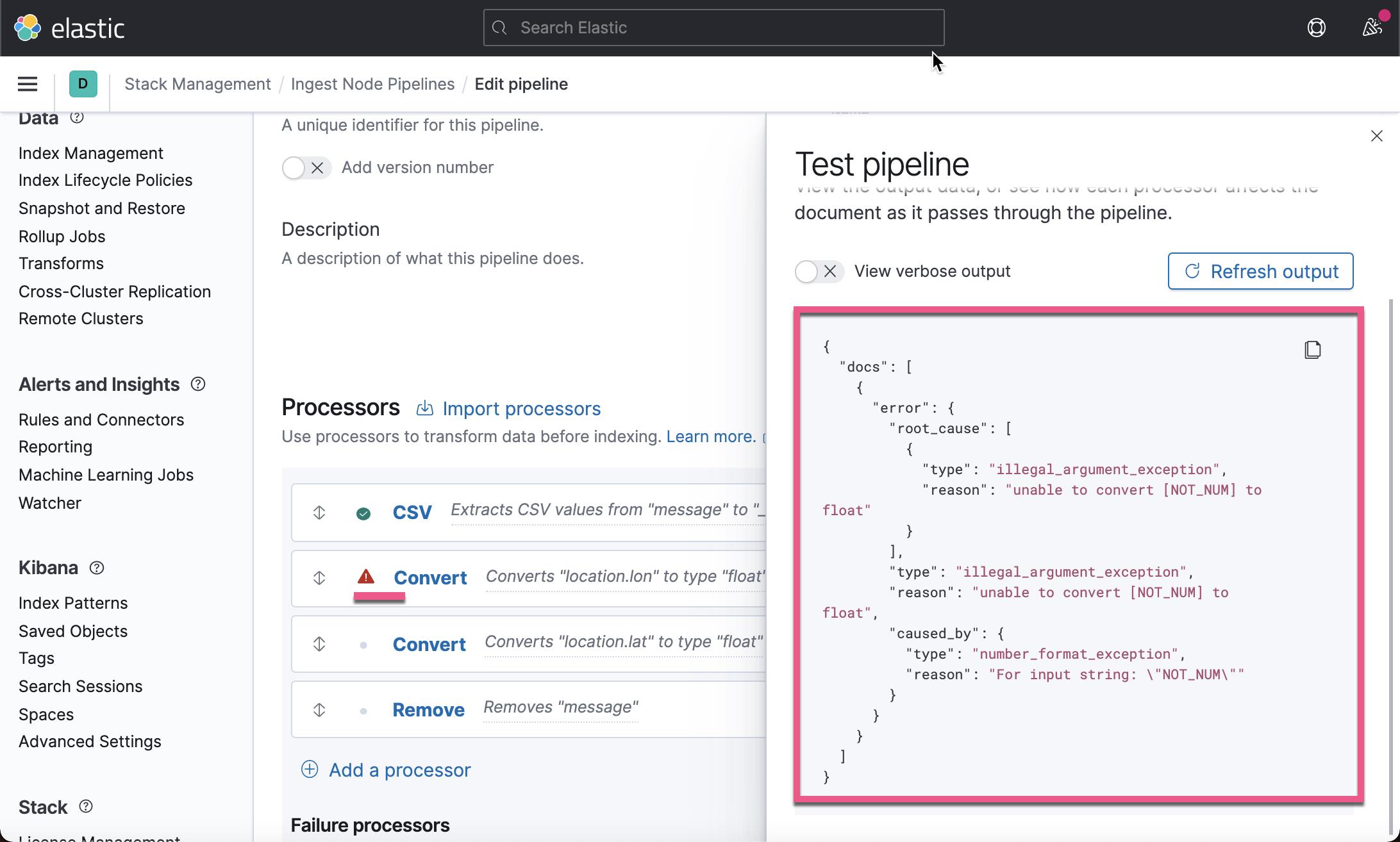
处理这种错误,可以在两个级别来进行处理。一种是在 processor 的基本,另外是在整个 pipeline 的级别来处理。比如在上面的 convert 中,我们可以针对这个 processor 来进行异常处理。我们可以选择 ignore_failure:


在上面,我们可以看到错误信息被忽视,但是在最终的结果中,它并不是我们想要的。我们还是取消之前的启动 ignore_failure。我们有两种途径处理这种错误。一种方法是针对这个 processor 完成一个 failure handler 来处理这种错误:

另外一种途径是针对整个 pipeline 来做错误处理:


在上面,我们添加了一个 Set 处理器。它设置了一个 error 字段,并把它的内容设置为 "document is not correctly parsed"。点击上面的 Add 按钮:

重新点击 View output:

这一次,我们没有看到像上次的那种错误了,但是 location 里的内容还是不正确。一种解决办法就是删除这个 location 字段。在上面的 Failure processors 中,我们再添加一个 remove 处理器:

我们再次点击 View output:


从上面的输出中我们可以看到 location 字段被删除了,同时我们还可以看到 message 字段还在,它表明在遇到错误时,位于 Convert 后面的 remove 处理器没有被运行,所以 message 字段没有被删除。
我们可以点击 Show request 来查看如何使用 API 来生成这个 Ingest Pipeline:
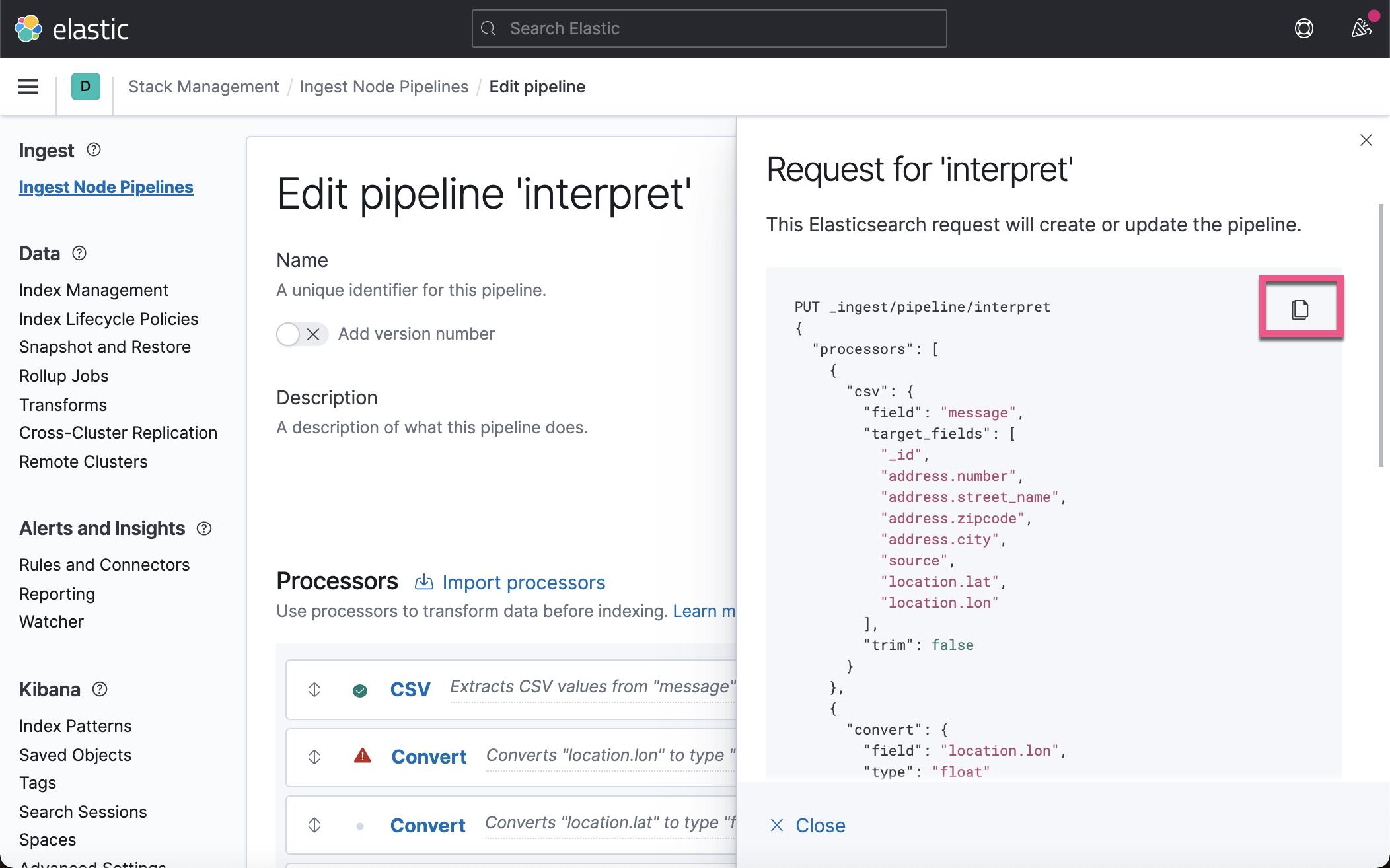
你可以甚至拷贝到 Dev Tools 中去运行。我们接下来需要点击 Save Pipeline 来保存这个 Ingest Pipeline。
到目前为止,我们已经通过 Kibana 的界面生成了我们想要的 Ingest Pipeline。我们可以在 Dev Tools 通过如下的方法来使用:
PUT demo/_doc/1?pipeline=interpret
{
"@timestamp": "2021-06-18T18:50:53",
"message": "950020004L-1,1,Rue du Clos Saint-Martin,95450,Ableiges,OSM,49.06789,1.969323"
}我们通过如下的方法来查询已经导入的文档:
GET demo/_doc/950020004L-1上面的命令显示的结果为:
{
"_index" : "demo",
"_type" : "_doc",
"_id" : "950020004L-1",
"_version" : 3,
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true,
"_source" : {
"@timestamp" : "2021-06-18T18:50:53",
"address" : {
"zipcode" : "95450",
"number" : "1",
"city" : "Ableiges",
"street_name" : "Rue du Clos Saint-Martin"
},
"location" : {
"lon" : 1.969323,
"lat" : 49.06789
},
"source" : "OSM"
}
}从上面,我们可以看出来 location.lon 及 location.lat 都已经是浮点数了。我们的 Ingest Pipeline 确实是在工作了。
为时序数据添加 timestamp
对于时序数据来说,timestamp 是非常重要的。假如有一种情况,我们的数据里缺少这个 timestamp,那么我改怎么办呢?一种简单的办法就是添加 ingest pipeline 运行的时间为事件的时间。我们可以采用如下的 ingest pipeline:
PUT _ingest/pipeline/test
{
"processors": [
{
"set": {
"field": "hello",
"value": "world"
}
},
{
"set": {
"if": "!ctx.containsKey('@timestamp')",
"field": "@timestamp",
"value": "{{_ingest.timestamp}}"
}
}
]
}在上面,我们检查 @timestamp 字段是否存在。如果不存在的话,我们使用 _ingest.timestamp 作为事件的时间。
以上是关于Elasticsearch:Ingest Pipeline 实践的主要内容,如果未能解决你的问题,请参考以下文章