Elastic Stack - 在一个集中位置发送存储和分析你的日志
Posted 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elastic Stack - 在一个集中位置发送存储和分析你的日志相关的知识,希望对你有一定的参考价值。
在生产中运行的应用程序是一头难以驯服的野兽。大多数有经验的开发人员——那些花了足够多的深夜或周六早上试图打破一个令人讨厌的生产错误的人 — 会在编写代码时尝试为他们以后的自己创造尽可能清晰的画面,以便他们能够理解实际发生的事情 事件期间的系统。
为了让生活更轻松,开发人员可以结合使用强大的可观察性堆栈来收集、转换和查看应用程序范围内的日志,搭配实时可观测性平台,无需推送新代码、重新部署或甚至重新启动服务。 这就是 Elastic Stack 为我们运维带来的好处。
日志记录是一个难题
虽然写日志相对容易,但使用它们是一个完全不同的球类游戏:
- 日志格式不一致 - 大多数现代软件都是许多不同开源项目、第三方依赖项和内部包的错综复杂的集成。所有这些部分都根据不同的方法以略有不同的格式记录。
- 记录的信息不一致 - 由于这些组件中的大多数是由不同的开发人员根据不同的日志记录样式(或根本没有)编写的,因此可以从日志中得出的实际值差异很大。
- 日志文件分布在每个特定的主机上 - 日志通常不容易从单个文件中获得,而是分布在文件系统中不同位置的多个文件中。日志拆分和轮换 - 将日志分块成随着时间的推移被覆盖的小文件的做法 - 在尝试定位一段时间前捕获的特定日志行时也会导致沮丧。
- 日志分布在多个主机上 - 我们的应用程序不是单一的——它们分布在多个实例中,在 Kubernetes 集群中编排并打包到容器中。弄清楚特定信息在应用程序拓扑中的位置也可能很棘手。
- 存储日志的成本很高 - 随着时间的推移,将日志保存在磁盘上,尤其是随着部署越来越多的软件变得越来越容易,这意味着仅用于存储日志文件的目的就会消耗大量空间——这可能会变得昂贵、快速。
- 分析日志的成本很高 - 解析大量信息是一项耗时且耗费资源的任务。
当然,这并不能阻止开发人员进行日志记录;相反 - 现代软件中复杂性的增加只会鼓励我们记录更多日志,因此我们可以绝对确定我们将获得稍后需要的确切信息。
让我们看一个现实生活中的例子,了解 Elastic 如何提供帮助。
Elastic Stack - 集中收集,存储及分析日志
Spring 生态系统有一个非常有名的示例应用程序,称为 Spring PetClinic。 这是围绕流行的 Spring Boot 构建的相对简单的 Web 应用程序的一个很好的例子 - 一个宠物诊所管理系统,它使兽医能够跟踪他们治疗的宠物,记录有关其主人的信息并管理预约。让我们看看如何使用 Elastic 更好地查看应用程序的日志。 我们将首先下载并运行应用程序 - 打开一个终端窗口并克隆存储库:
git clone https://github.com/spring-projects/spring-petclinic.git
cd spring-petclinic使用文件夹中的 Maven Wrapper 打包运行应用:
./mvnw package
java -jar target/*.jar
一旦 JVM 启动,你将能够看到应用程序日志流入你的终端窗口。在上面,我们可以看到应用输出的日志。
回想一下,为了在生产设置中查看这些日志,你需要连接到远程生产机器并连续跟踪日志文件,或者将应用程序的进程保留在终端的前台。
应用程序预先填充了许多日志行 - 来自 Spring 本身、ORM 层、应用程序逻辑等的日志行。 自然地,随着我们向应用程序添加越来越多的功能,我们预计日志量会进一步增长,并且通过终端过滤日志文件可能会变得非常繁琐。
为了让每个参与者都更轻松(并防止开发人员随机连接到生产机器来获取日志数据),我们将我们的应用程序与 Elastic 集成。
将 Java 应用程序与 Elastic 集成非常简单:
1)按照文档 “Elastic:菜鸟上手指南” 搭建自己的 Elasticsearch 及 Kibana。
2)把下面的依赖添加到你的 pom.xml 文件中(我们正在添加 Logback,一种流行的 Java 日志记录框架,以及适当的 ECS - Elastic Common Schema - Logback 编码器)
pom.xml
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>co.elastic.logging</groupId>
<artifactId>logback-ecs-encoder</artifactId>
<version>1.0.1</version>
</dependency>3)将我们的 logger 添加到应用程序中:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class PetClinicApplication {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(PetClinicApplication.class);
SpringApplication.run(PetClinicApplication.class, args);
logger.info("PetClinic has started");
}
}4)配置应用程序以使用 logback,添加以下几行到:
<pet_clinic_dir>/src/main/resources/application.properties
logging.config=classpath:logback-spring.xml
spring.application.name=lightrun-application
logging.file.name=<pet_clinic_dir>/my-application.log5)我们还需要一个小的配置文件来将 Logback 与 Spring 集成。 在 ‘<pet_clinic_dir>/src/main/resources/’ 文件夹下新建一个名为 ‘logback-spring.xml’ 的文件,粘贴以下内容
<pet_clinic_dir>/src/main/resources/logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_FILE" value="${LOG_FILE:-${LOG_PATH:-${LOG_TEMP:-${java.io.tmpdir:-/tmp}}}/spring.log}"/>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<include resource="org/springframework/boot/logging/logback/console-appender.xml" />
<include resource="org/springframework/boot/logging/logback/file-appender.xml" />
<include resource="co/elastic/logging/logback/boot/ecs-file-appender.xml" />
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="ECS_JSON_FILE"/>
<appender-ref ref="FILE"/>
</root>
</configuration>我们重新编译 Java 应用,并运行它:
./mvnw package
java -jar target/*.jar我们会发现在 <pet_clinic_dir> 目录下,会发现一个叫做 my-application.log 的日志文件 及 my-application.log.json 文件:
$ pwd
/Users/liuxg/java/spring-petclinic
$ ls
docker-compose.yml my-application.log.json spring-petclinic.iml
mvnw pom.xml src
mvnw.cmd push-to-pws target
my-application.log readme.mdmy-application.log 的内容如下:
2021-08-18 13:28:45.701 INFO 84135 --- [main] o.s.s.petclinic.vet.VetControllerTests : Starting VetControllerTests on liuxg with PID 84135 (started by liuxg in /Users/liuxg/java/spring-petclinic)
2021-08-18 13:28:45.705 INFO 84135 --- [main] o.s.s.petclinic.vet.VetControllerTests : No active profile set, falling back to default profiles: default
2021-08-18 13:28:47.281 INFO 84135 --- [main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor'
2021-08-18 13:28:48.014 INFO 84135 --- [main] o.s.b.t.m.w.SpringBootMockServletContext : Initializing Spring TestDispatcherServlet ''
2021-08-18 13:28:48.015 INFO 84135 --- [main] o.s.t.web.servlet.TestDispatcherServlet : Initializing Servlet ''
2021-08-18 13:28:48.025 INFO 84135 --- [main] o.s.t.web.servlet.TestDispatcherServlet : Completed initialization in 10 ms
2021-08-18 13:28:48.054 INFO 84135 --- [main] o.s.s.petclinic.vet.VetControllerTests : Started VetControllerTests in 2.823 seconds (JVM running for 4.103)
2021-08-18 13:28:48.822 INFO 84135 --- [main] .b.t.a.w.s.WebMvcTestContextBootstrapper : Neither @ContextConfiguration nor @ContextHierarchy found for test class [org.springframework.samples.petclinic.owner.OwnerControllerTests], using SpringBootContextLoader
2021-08-18 13:28:48.822 INFO 84135 --- [main] o.s.t.c.support.AbstractContextLoader : Could not detect default resource locations for test class [org.springframework.samples.petclinic.owner.OwnerControllerTests]: no resource found for suffixes {-context.xml, Context.groovy}.
"my-application.log" 152L, 92356B
...在本次的练习中,我们将使用 my-application.log.json 文件进行导入。
6)该应用程序几乎已完全配置! 现在剩下要做的就是收集日志并将它们发送到 Elastic。Filebeat 是日志传送器,也是 Elastic Stack 的重要组成部分。 它负责处理您的应用程序发出的日志并将它们通过网络传输到 Elastic。 要为您的应用程序配置 Filebeat,你可以:
- 按照此处的说明安装 Filebeat(注意它是在你的机器上运行的本地服务,与应用程序无关)
- 安装 Filebeat 后,将以下部分添加到其配置文件中(可以在 /etc/filebeat/filebeat.yml 中找到)。 这将确保 Filebeat 知道应用程序,收集它输出的日志并将它们发送到 Elasticsearch:
filebeat.yml
filebeat.inputs:
- type: log
paths: /Users/liuxg/java/spring-petclinic/my-application.log.json
json.keys_under_root: true
json.overwrite_keys: true
json.add_error_key: true
json.expand_keys: true
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]- 启动 Filebeat
./filebeat -e到现在我们已经成功地开始导入日志信息! 日志将直接流向 Elastic Observability 的日志分析窗格
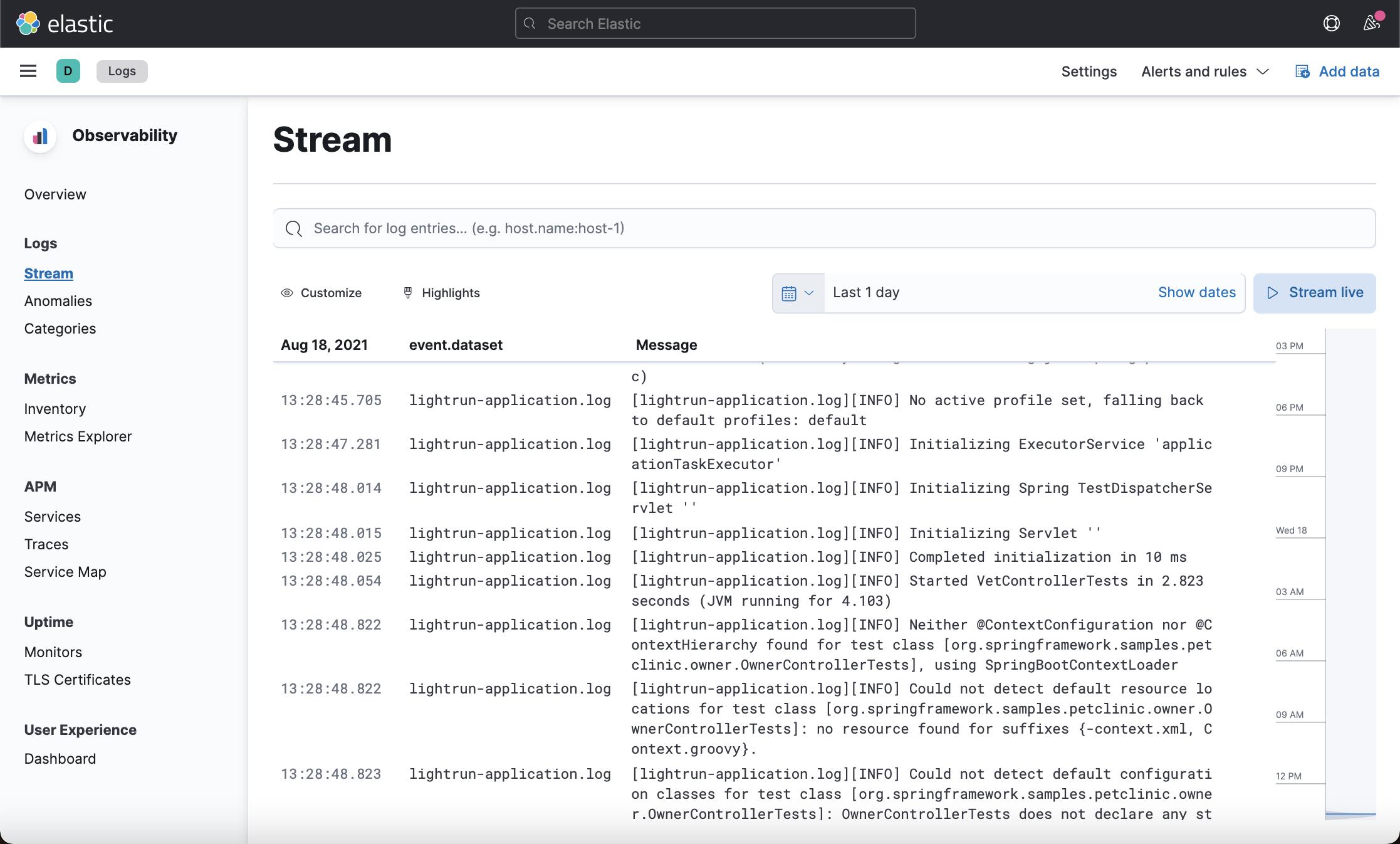
在本次练习中,我们并没有把日志的内容进行结构化。我们可以使用两种方法来对日志做进一步的处理:
- 使用 Logstash 来对日志进行结构化,你可以参考我之前的文章:Logstash:Logstash 入门教程 (一)
- 使用 Elasticsearch 的 ingest node 来对日志文件进行结构化。请参阅我之前的文章 Elasticsearch:Elastic可观测性 - 运用 pipeline 使数据结构化
参考:
【1】 https://www.elastic.co/blog/full-cycle-observability-with-the-elastic-stack-and-lightrun
以上是关于Elastic Stack - 在一个集中位置发送存储和分析你的日志的主要内容,如果未能解决你的问题,请参考以下文章
ES 集中式日志分析平台 Elastic Stack(介绍)