Elasticsearch:Analyzer 在 Python 中的运用
Posted 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:Analyzer 在 Python 中的运用相关的知识,希望对你有一定的参考价值。
在今天的文章中,我来介绍如何在 Python 中使用 Analyzer。有关 Analyzer 的文章,请参考 “Elastic:菜鸟上手指南” 中的 “中文分词器介绍” 部分介绍。
安装
我们首先来安装 Elasticsearch 及 Kibana。你可以参考 “Elastic:菜鸟上手指南” 中的文章来安装 Elasticsearch 及 Kibana。你可以参考文章 “Elasticsearch:IK 中文分词器” 来安装 IK 中文分词器。千万要记得安装分词器后,要重新启动 Elasticsearch。
我们可以参考文章 “Elasticsearch:使用 Jupyter Notebook 创建 Python 应用导入 CSV 文件” 来设置自己的 Python 及 Jupyter 环境。
展示
我们首先创建一个叫做 analyzer 的 notebook。我们输入如下的代码:
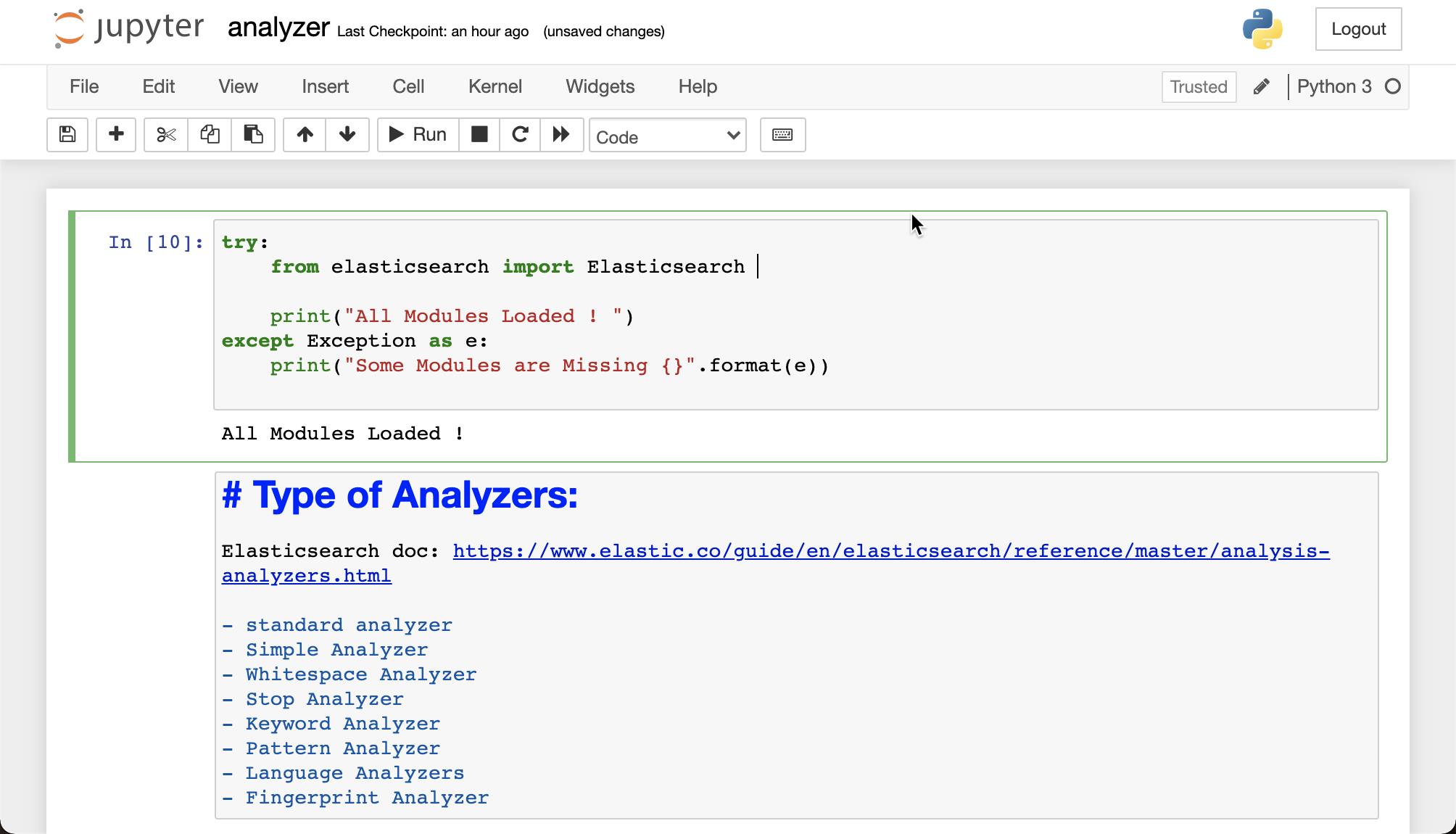
try:
from elasticsearch import Elasticsearch
print("All Modules Loaded ! ")
except Exception as e:
print("Some Modules are Missing {}".format(e))关于 Elasticsearch 自带的 analyzer 的描述可以在官方文档 Built-in analyzer reference | Elasticsearch Guide [master] | Elastic
我们接下来创建和 Elasticsearch 的连接:
def connect_elasticsearch():
es = None
es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
if es.ping():
print('Yupiee Connected ')
else:
print('Awww it could not connect!')
return es
es = connect_elasticsearch()
es.ping() 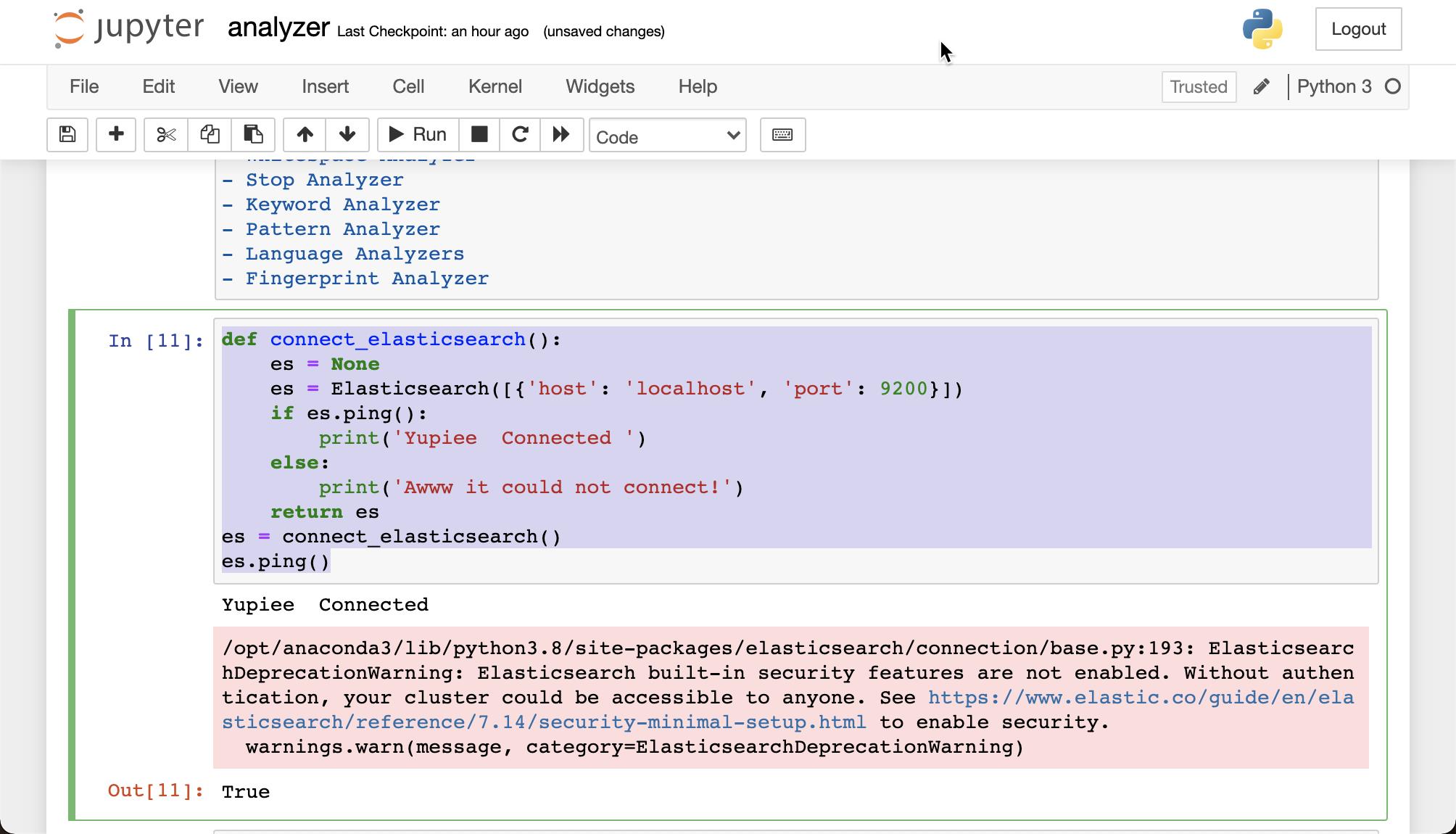
我们尝试各种 built-in 的 analyzer:
analyzers = {"standard", "simple", "whitespace", "stop", "keyword", "pattern", "fingerprint"}
for analyzer in analyzers:
res = es.indices.analyze(body={
"analyzer": analyzer,
"text": "This is exactly what I want"
})
print("======", analyzer, "=======")
for i in res['tokens']:
print(i['token'])
print("\\n")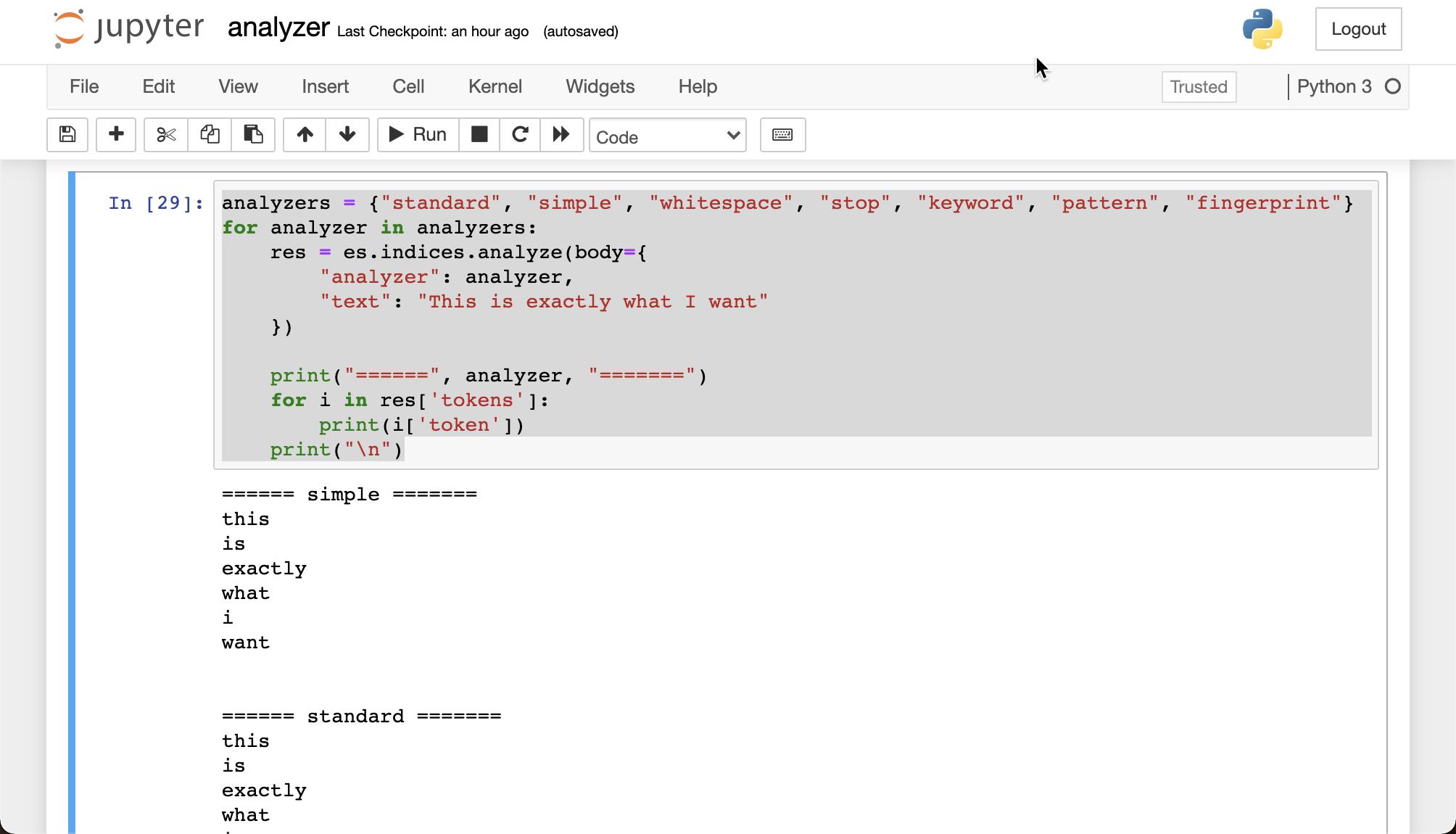
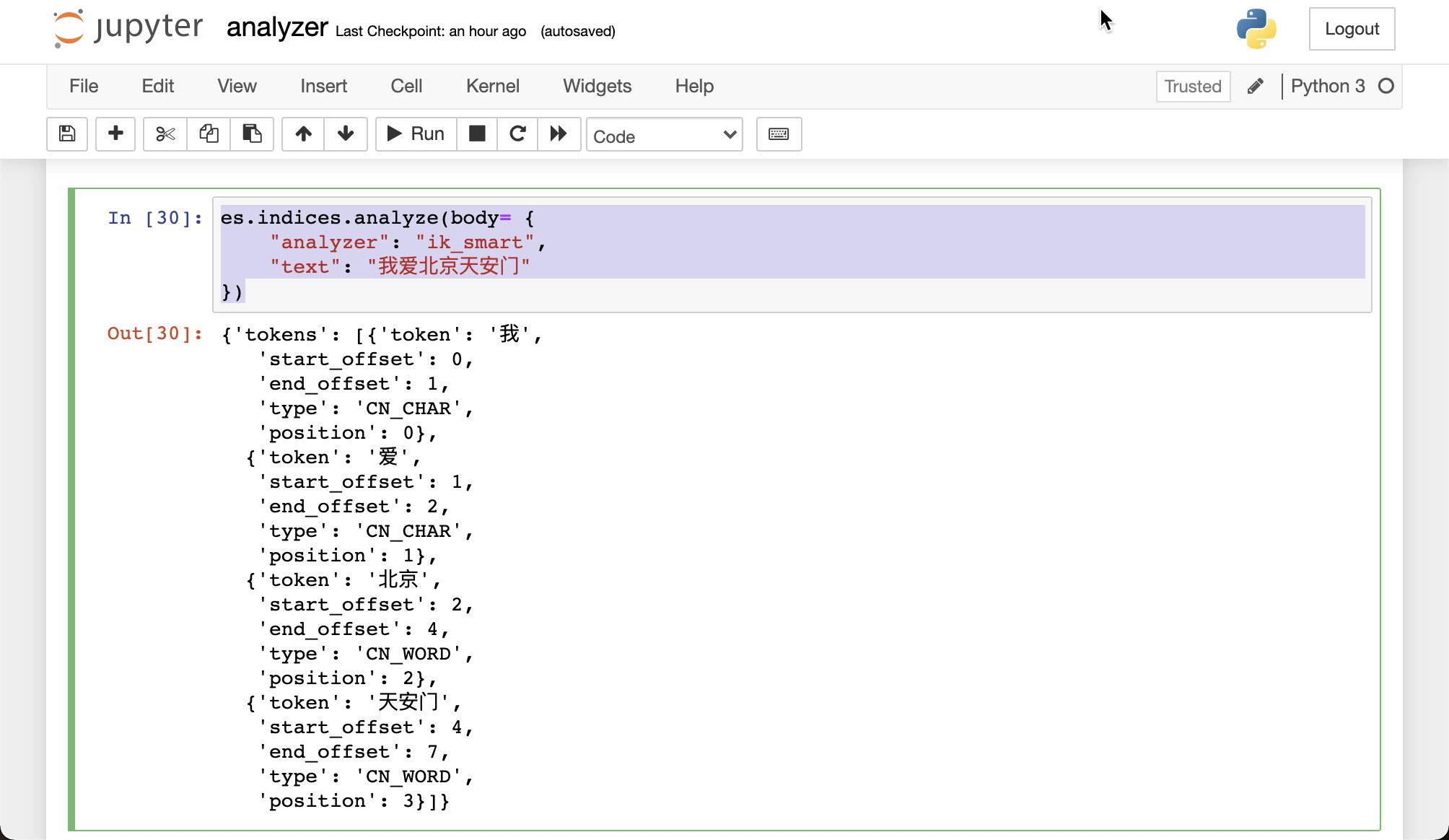
我们来试一下中文的分词器:
es.indices.analyze(body= {
"analyzer": "ik_smart",
"text": "我爱北京天安门"
})
试一下 standard 分词器:
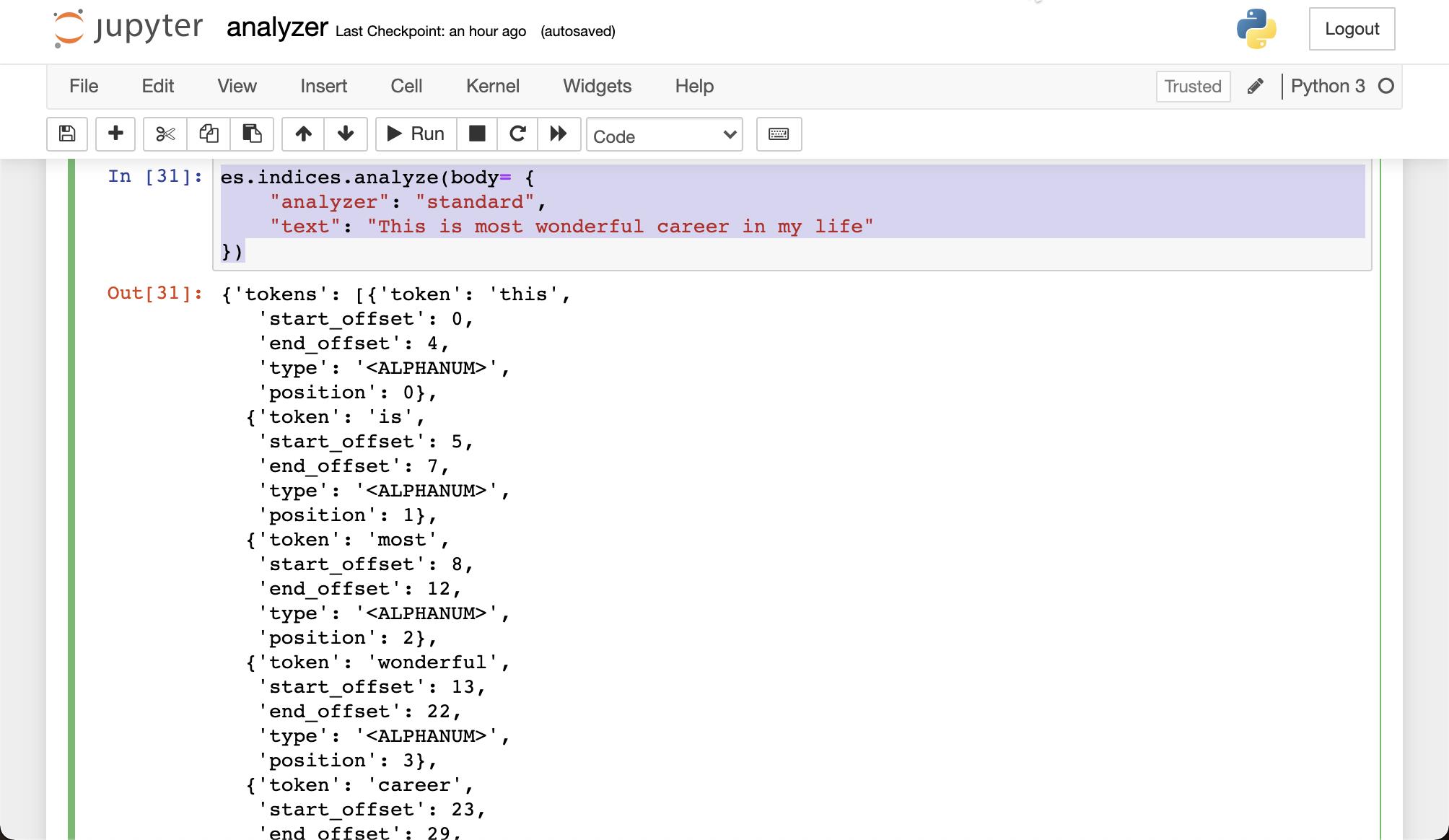
es.indices.analyze(body= {
"analyzer": "standard",
"text": "This is most wonderful career in my life"
})
body = {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"text": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "whitespace"
}
}
}
}
}
}
# create index
es.indices.create(index="my_index", ignore=400, body=body)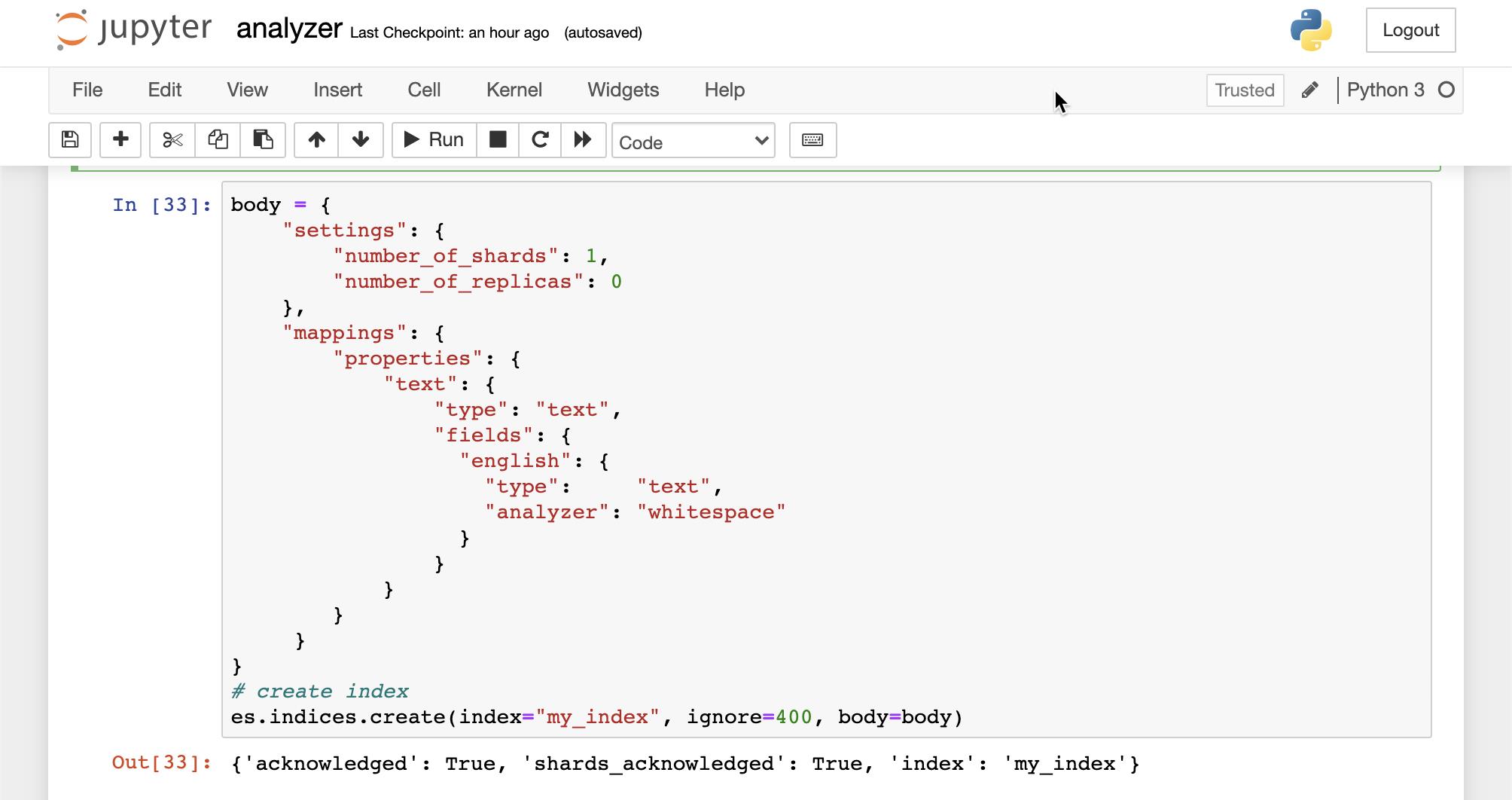
在上面,我们创建一个索引。我们接下来使用索引中的 analyzer:
res = es.indices.analyze(index="my_index", body = {
"field": "text.whitespace",
"text": "The quick Brown Foxes ."
})
for i in res['tokens']:
print(i['token'])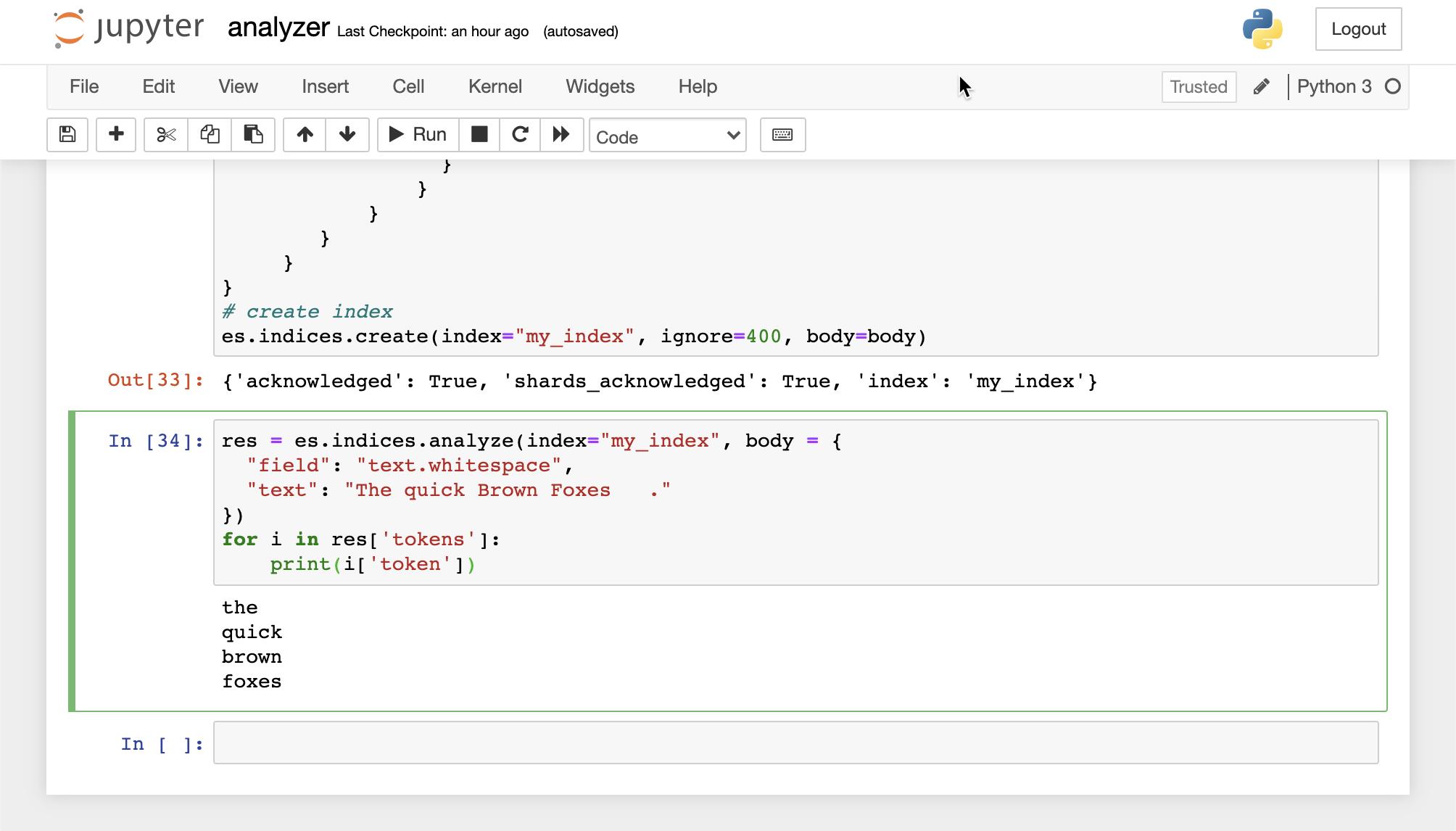
以上是关于Elasticsearch:Analyzer 在 Python 中的运用的主要内容,如果未能解决你的问题,请参考以下文章