学习笔记Hadoop—— Hadoop集群的安装与部署—— 配置Hadoop集群
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Hadoop—— Hadoop集群的安装与部署—— 配置Hadoop集群相关的知识,希望对你有一定的参考价值。
四、配置Hadoop集群
Hadoop集群总体规划
Hadoop集群安装采用下面步骤:
- 在Master节点:上传并解压Hadoop安装包 。
- 在Master节点:配置Hadoop所需configuration配置文件。
- 在Master节点:拷贝配置好的Hadoop安装包到其他节点。
- 在所有节点:创建数据存储目录 。
- 在Master节点:执行HDFS格式化操作。
4.1、上传并解压Hadoop安装包
(这里我已经用Xshell连接到Master结点了)
Hadoop安装包链接:https://pan.baidu.com/s/1teHwnBH2Qm6F7iWZ3q-hSQ
提取码:cgnb
上传
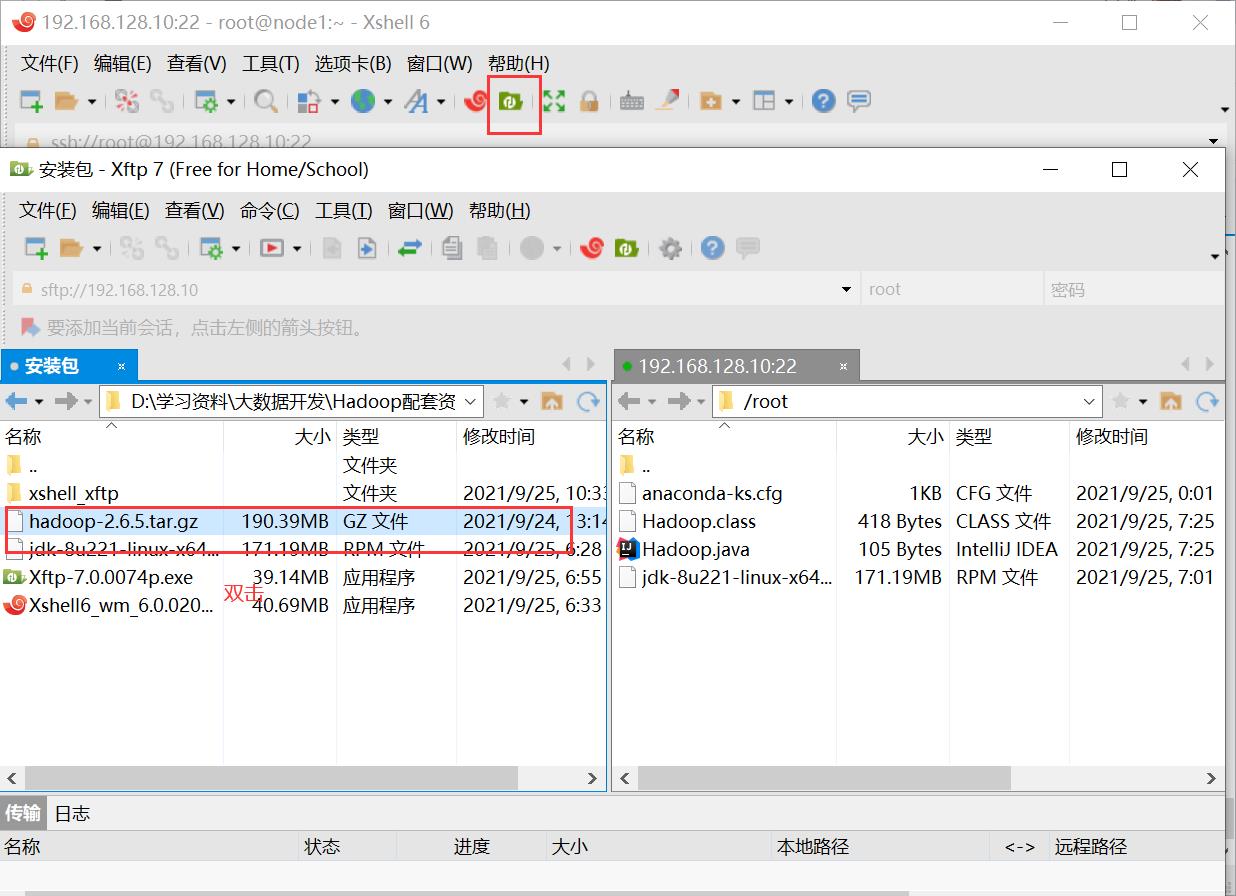
完成后用 ls 指令查看
在这里插入图片描述
解压
tar -zxf hadoop-2.6.5.tar.gz -C /opt/

4.2、修改配置文件:hadoop-env.sh
首先进入/opt/hadoop-2.6.5/etc/hadoop/目录
cd /opt/hadoop-3.1.4/etc/hadoop/
配置hadoop-env.sh
vi hadoop-env.sh

4.3、修改配置文件:core-site.xml & hdfs-site.xml
首先进入/opt/hadoop-2.6.5/etc/hadoop/目录
cd /opt/hadoop-3.1.4/etc/hadoop/
配置core-site.xml
vi core-site.xml
在<configuration> </configuration>间添加如下
<!--hdfs临时路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<!--hdfs 的默认地址、端口 访问地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
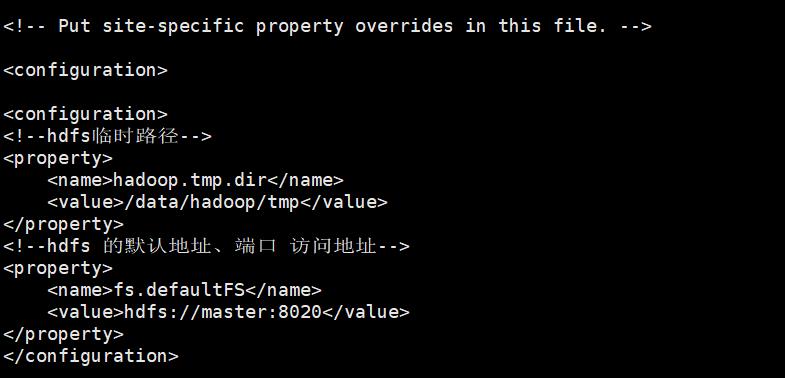
配置hdfs-site.xml
vi hdfs-site.xml
在<configuration> </configuration>间添加如下
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 是否启用hdfs权限检查 false 关闭 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 块大小,默认字节, 可使用 k m g t p e-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/namenode</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/data/hadoop/datanode</value>
</property>
4.4、修改配置文件:mapred-site.xml & yarn-site.xml & workers
首先进入/opt/hadoop-2.6.5/etc/hadoop/目录
cd /opt/hadoop-3.1.4/etc/hadoop/
配置mapred-site.xml
vi mapred-site.xml
在<configuration> </configuration>间添加如下
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.1.4</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/hadoop-3.1.4/share/hadoop/mapreduce/*:/opt/hadoop-3.1.4/share/hadoop/mapreduce/lib/*</value>
</property>
配置yarn-site.xml
vi yarn-site.xml
在<configuration> </configuration>间添加如下
<!--集群master-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- NodeManager上运行的附属服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 关闭内存检测-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
配置workers
vi workers
把里面内容改为
node1
node2
node3
4.5、拷贝Hadoop安装包
进入/opt目录,通过指令(依次执行)拷贝到node1、node2、node3目录
(可以多建立几个会话,速度会快些)
scp -r hadoop-3.1.4/ node1:/opt/
scp -r hadoop-3.1.4/ node2:/opt/
scp -r hadoop-3.1.4/ node3:/opt/
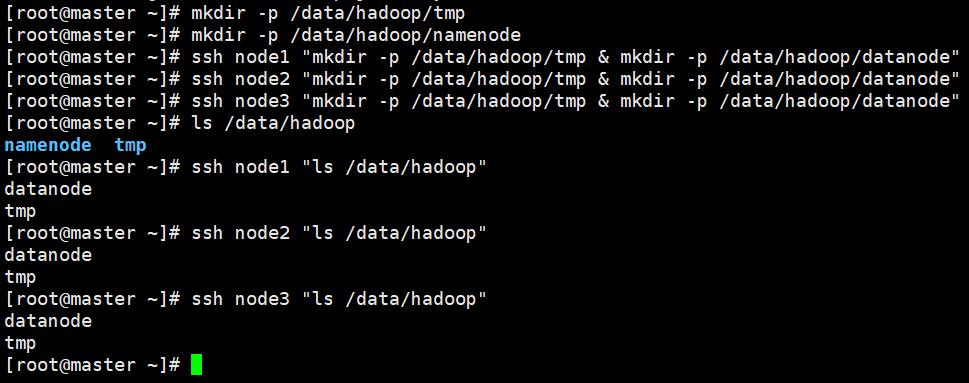
4.6、创建数据目录
(依次执行下面语句)
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/namenode
ssh node1 "mkdir -p /data/hadoop/tmp & mkdir -p /data/hadoop/datanode"
ssh node2 "mkdir -p /data/hadoop/tmp & mkdir -p /data/hadoop/datanode"
ssh node3 "mkdir -p /data/hadoop/tmp & mkdir -p /data/hadoop/datanode"
4.7、格式化HDFS
进入hadoop安装下的bin目录
cd /opt/hadoop-3.1.4/bin/
执行
./hdfs namenode -format demo
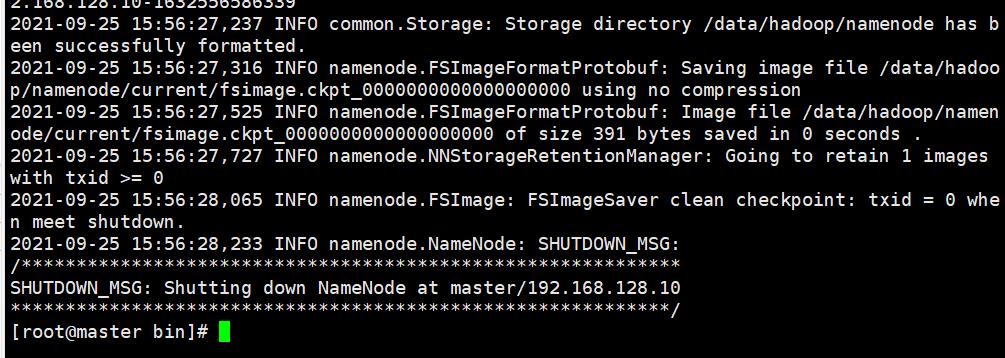
格式化完成,集群配置完成
以上是关于学习笔记Hadoop—— Hadoop集群的安装与部署—— 配置Hadoop集群的主要内容,如果未能解决你的问题,请参考以下文章