开山篇自然语言处理(PyTorch版)
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开山篇自然语言处理(PyTorch版)相关的知识,希望对你有一定的参考价值。
自然语言处理(PyTorch版)
PyTorch 自然语言处理

自然语言处理-基础介绍
本文标题:Natural-Language-Processing-with-PyTorch(一)
文章作者:Yif Du
发布时间:2018 年 12 月 17 日 - 09:12
最后更新:2019 年 02 月 16 日 - 21:02
原始链接:http://yifdu.github.io/2018/12/17/Natural-Language-Processing-with-PyTorch(一)/
许可协议:署名-非商业性使用-禁止演绎 4.0 国际 转载请保留原文链接及作者。
像 Echo (Alexa)、Siri 和谷歌翻译这样的家喻户晓的产品名称至少有一个共同点。它们都是自然语言处理(NLP)应用的产物,NLP 是本书的两个主要主题之一。
NLP 是一套运用统计方法的技术,无论是否有语言学的洞见,为了解决现实世界的任务而理解文本。这种对文本的“理解”主要是通过将文本转换为可用的计算表示,这些计算表示是离散或连续的组合结构,如向量或张量、图形和树。
从数据(本例中为文本)中学习适合于任务的表示形式是机器学习的主题。应用机器学习的文本数据有超过三十年的历史,但最近(2008 年至 2010 年开始) [1] 一组机器学习技术,被称为深度学习,继续发展和证明非常有效的各种人工智能(AI)在 NLP 中的任务,演讲,和计算机视觉。深度学习是我们要讲的另一个主题;因此,本书是关于 NLP 和深度学习的研究。
简单地说,深度学习使人们能够使用一种称为计算图和数字优化技术的抽象概念有效地从数据中学习表示。这就是深度学习和计算图的成功之处,像谷歌、Facebook 和 Amazon 这样的大型技术公司已经发布了基于它们的计算图形框架和库的实现,以捕捉研究人员和工程师的思维。
在本书中,我们考虑 PyTorch,一个越来越流行的基于 python 的计算图框架库来实现深度学习算法。在本章中,我们将解释什么是计算图,以及我们选择使用 PyTorch 作为框架。
机器学习和深度学习的领域是广阔的。在这一章,在本书的大部分时间里,我们主要考虑的是所谓的监督学习;也就是说,使用标记的训练示例进行学习。我们解释了监督学习范式,这将成为本书的基础。如果到目前为止您还不熟悉其中的许多术语,那么您是对的。
这一章,以及未来的章节,不仅澄清了这一点,而且深入研究了它们。如果您已经熟悉这里提到的一些术语和概念,我们仍然鼓励您遵循以下两个原因:为本书其余部分建立一个共享的词汇表,以及填补理解未来章节所需的任何空白。
本章的目标是:
- 发展对监督学习范式的清晰理解,理解术语,并发展一个概念框架来处理未来章节的学习任务
- 学习如何为学习任务的输入编码
- 理解什么是计算图
- 掌握 PyTorch 的基本知识
让我们开始吧!
监督学习范式
机器学习中的监督,或者简单的监督学习,是指将目标(被预测的内容)的真实情况用于观察(输入)的情况。
例如,在文档分类中,目标是一个分类标签,**观察(输入)**是一个文档。
例如,在机器翻译中,观察(输入)是一种语言的句子,目标是另一种语言的句子。通过对输入数据的理解,我们在图 1-1 中演示了监督学习范式。
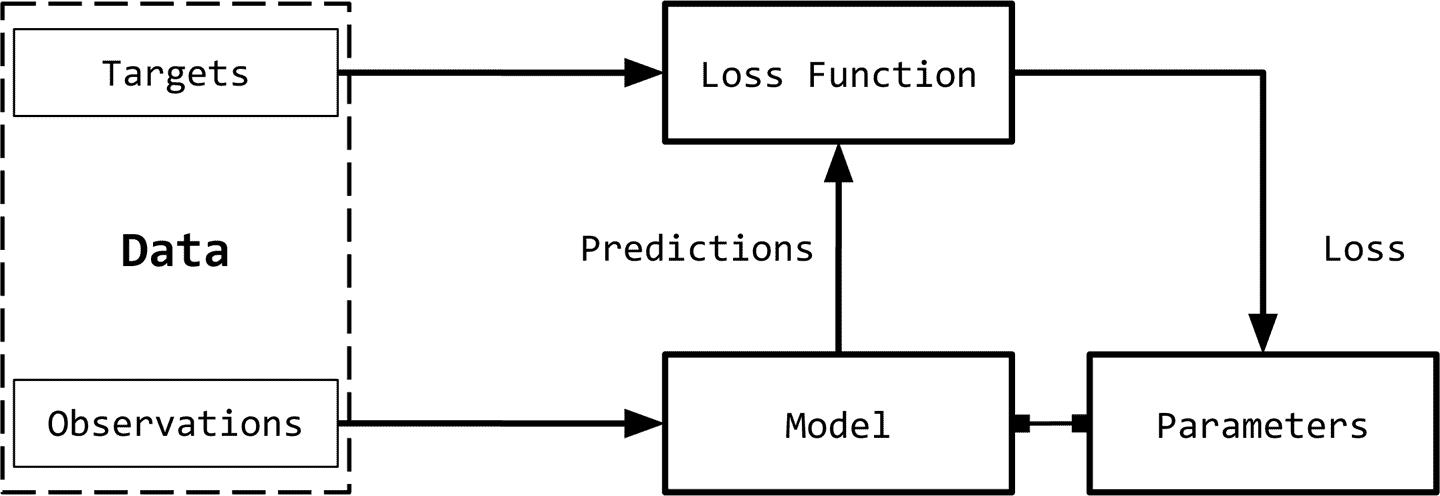
我们可以将监督学习范式分解为六个主要概念,如图所示: 观察: 观察是我们想要预测的东西。
我们用x表示观察值。我们有时把观察值称为“输入”。 目标: 目标是与观察相对应的标签。它通常是被预言的事情。
按照机器学习/深度学习中的标准符号,我们用y表示这些。有时,这被称为真实情况。 模型: 模型是一个数学表达式或函数,它接受一个观察值x,并预测其目标标签的值。 参数: 有时也称为权重,这些参数化模型。标准使用的符号w(权重)或w_hat。
预测: 预测,也称为估计,是模型在给定观测值的情况下所猜测目标的值。我们用一个hat表示这些。所以,目标y的预测用y_hat来表示。
损失函数: 损失函数是比较预测与训练数据中观测目标之间的距离的函数。
给定一个目标及其预测,损失函数将分配一个称为损失的标量实值。损失值越低,模型对目标的预测效果越好。我们用L表示损失函数。
虽然在 NLP /深度学习建模或编写本书时,这在数学上并不是正式有效,但我们将正式重述监督学习范例,以便为该领域的新读者提供标准术语,以便他们拥有熟悉 arXiv 研究论文中的符号和写作风格。
考虑一个数据集D={X[i],y[i]}, i=1..n,有n个例子。给定这个数据集,我们想要学习一个由权值w参数化的函数(模型)f,也就是说,我们对f的结构做一个假设,给定这个结构,权值w的学习值将充分表征模型。
对于一个给定的输入X,模型预测y_hat作为目标: y_hat = f(X;W)在监督学习中,对于训练例子,我们知道观察的真正目标y。这个实例的损失将为L(y, y_hat)。
然后,监督学习就变成了一个寻找最优参数/权值w的过程,从而使所有n个例子的累积损失最小化。
利用**(随机)梯度下降法**进行训练 监督学习的目标是为给定的数据集选择参数值,使损失函数最小化。换句话说,这等价于在方程中求根。
我们知道梯度下降法是一种常见的求方程根的方法。回忆一下,在传统的梯度下降法中,我们对根(参数)的一些初值进行猜测,并迭代更新这些参数,直到目标函数(损失函数)的计算值低于可接受阈值(即收敛准则)。
对于大型数据集,由于内存限制,在整个数据集上实现传统的梯度下降通常是不可能的,而且由于计算开销,速度非常慢。相反,通常采用一种近似的梯度下降称为随机梯度下降(SGD)。
在随机情况下,数据点或数据点的子集是随机选择的,并计算该子集的梯度。当使用单个数据点时,这种方法称为纯 SGD,当使用(多个)数据点的子集时,我们将其称为小型批量 SGD。
通常情况下,“纯”和“小型批量”这两个词在根据上下文变得清晰时就会被删除。在实际应用中,很少使用纯 SGD,因为它会由于有噪声的更新而导致非常慢的收敛。一般 SGD 算法有不同的变体,都是为了更快的收敛。在后面的章节中,我们将探讨这些变体中的一些,以及如何使用渐变来更新参数。这种迭代更新参数的过程称为反向传播。反向传播的每个步骤(又名周期)由向前传递和向后传递组成。
向前传递用参数的当前值计算输入并计算损失函数。
反向传递使用损失梯度更新参数。
请注意,到目前为止,这里没有什么是专门针对深度学习或神经网络的。图 1-1 中箭头的方向表示训练系统时数据的“流”。
关于训练和“计算图”中“流”的概念,我们还有更多要说的,但首先,让我们看看如何用数字表示 NLP 问题中的输入和目标,这样我们就可以训练模型并预测结果。
观测和目标编码
我们需要用数字表示观测值(文本),以便与机器学习算法一起使用。图 1-2 给出了一个可视化的描述。
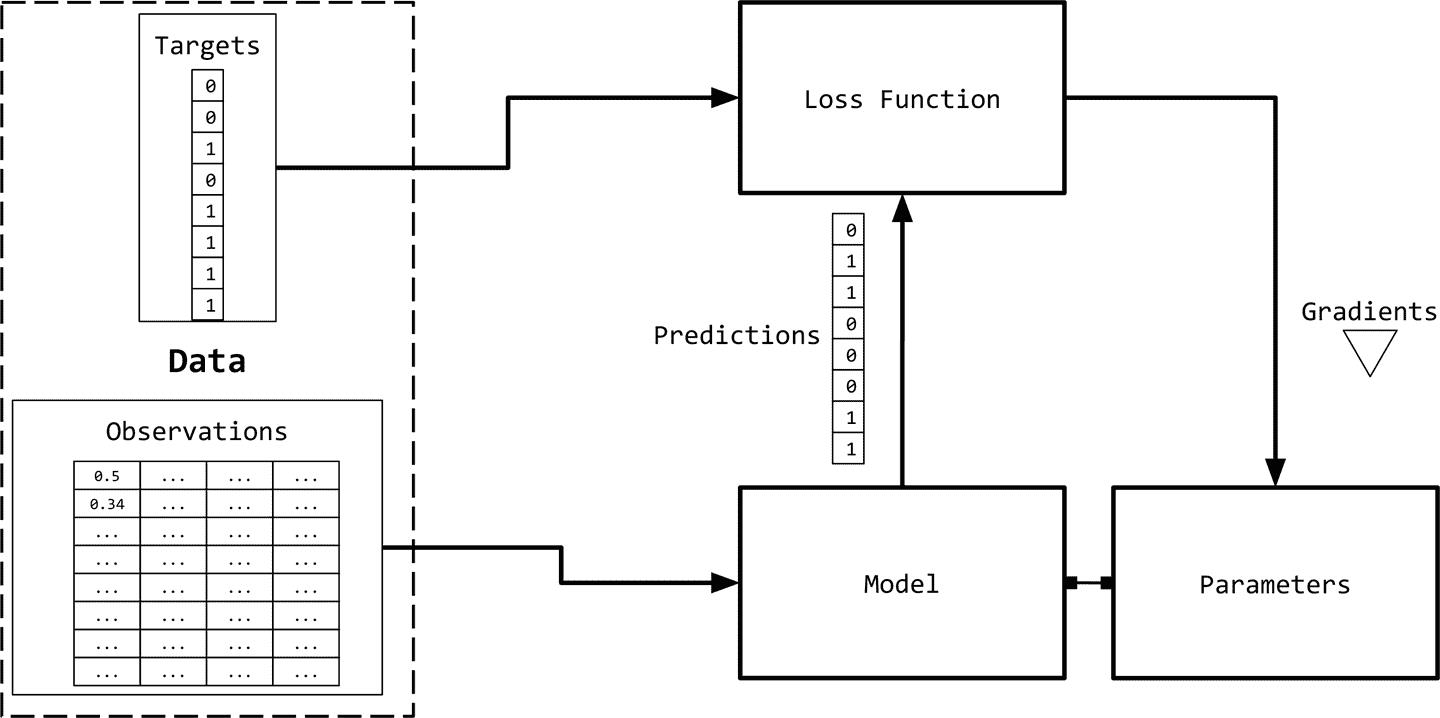
表示文本的一种简单方法是用数字向量表示。有无数种方法可以执行这种映射/表示。事实上,本书的大部分内容都致力于从数据中学习此类任务表示。然而,我们从基于启发式的一些简单的基于计数的表示开始。
虽然简单,但是它们非常强大,或者可以作为更丰富的表示学习的起点。所有这些基于计数的表示都是从一个固定维数的向量开始的。
One-Hot 表示
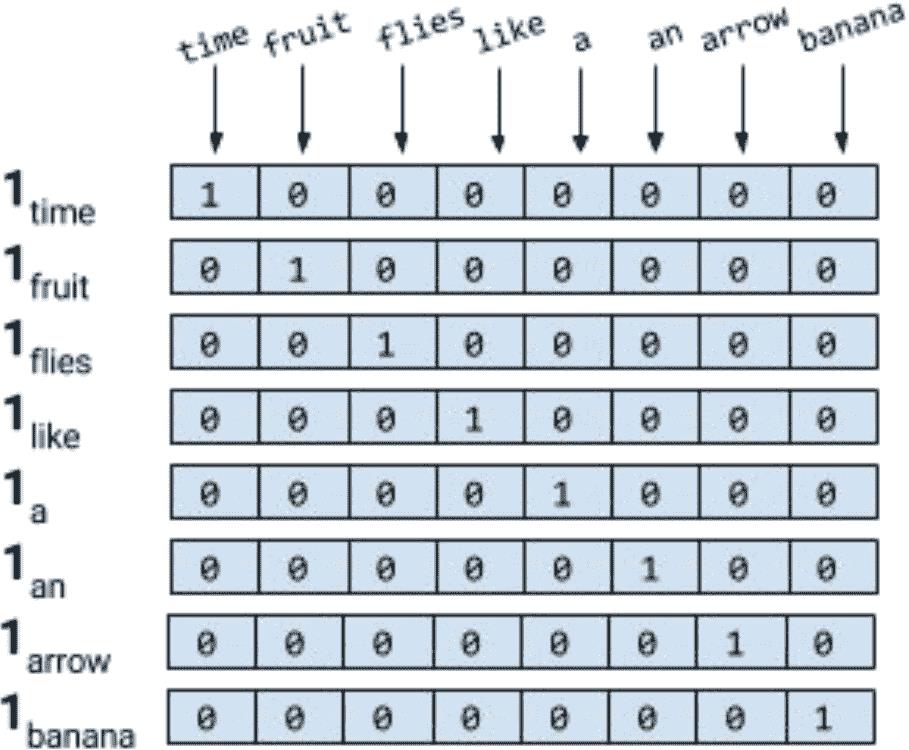
顾名思义,单热表示从一个零向量开始,如果单词出现在句子或文档中,则将向量中的相应条目设置为 1。考虑下面两句话。
Time flies like an arrow.
Fruit flies like a banana.
对句子进行标记,忽略标点符号,并将所有的单词都用小写字母表示,就会得到一个大小为 8 的词汇表:{time, fruit, flies, like, a, an, arrow, banana}。所以,我们可以用一个八维的单热向量来表示每个单词。在本书中,我们使用1[w]表示标记/单词w的单热表示。
对于短语、句子或文档,压缩的单热表示仅仅是其组成词的逻辑或的单热表示。使用图 1-3 所示的编码,短语like a banana的单热表示将是一个3×8矩阵,其中的列是 8 维的单热向量。通常还会看到“折叠”或二进制编码,其中文本/短语由词汇表长度的向量表示,用 0 和 1 表示单词的缺失或存在。like a banana的二进制编码是:[0,0,0,1,1,0,0,1]。
注意:在这一点上,如果你觉得我们把flies的两种不同的意思(或感觉)搞混了,恭喜你,聪明的读者!语言充满了歧义,但是我们仍然可以通过极其简化的假设来构建有用的解决方案。学习特定于意义的表示是可能的,但是我们现在做得有些超前了。
尽管对于本书中的输入,我们很少使用除了单热表示之外的其他表示,但是由于 NLP 中受欢迎、历史原因和完成目的,我们现在介绍术语频率(TF)和术语频率反转文档频率(TF-idf)表示。这些表示在信息检索(IR)中有着悠久的历史,甚至在今天的生产 NLP 系统中也得到了广泛的应用。(翻译有不足)
TF 表示
短语、句子或文档的 TF 表示仅仅是构成词的单热的总和。为了继续我们愚蠢的示例,使用前面提到的单热编码,Fruit flies like time flies a fruit这句话具有以下 TF 表示:[1,2,2,1,1,1,0,0]。注意,每个条目是句子(语料库)中出现相应单词的次数的计数。我们用 TF(w)表示一个单词的 TF。
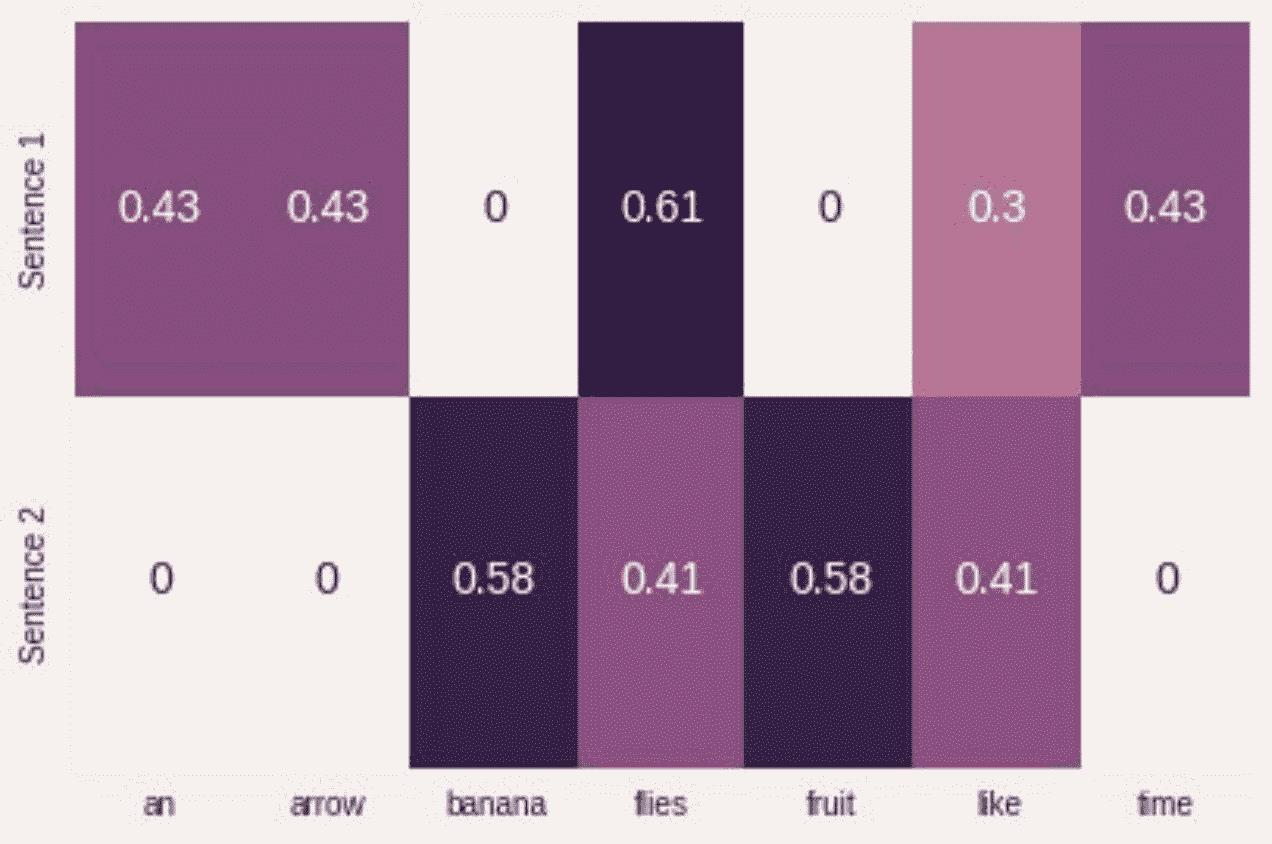
示例 1-1:使用 sklearn 生成“塌陷的”单热或二进制表示
from sklearn.feature_extraction.text import CountVectorizer
import seaborn as sns
corpus = ['Time flies flies like an arrow.',
'Fruit flies like a banana.']
one_hot_vectorizer = CountVectorizer(binary=True)
one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()
sns.heatmap(one_hot, annot=True,
cbar=False, xticklabels=vocab,
yticklabels=['Sentence 1', 'Sentence 2'])
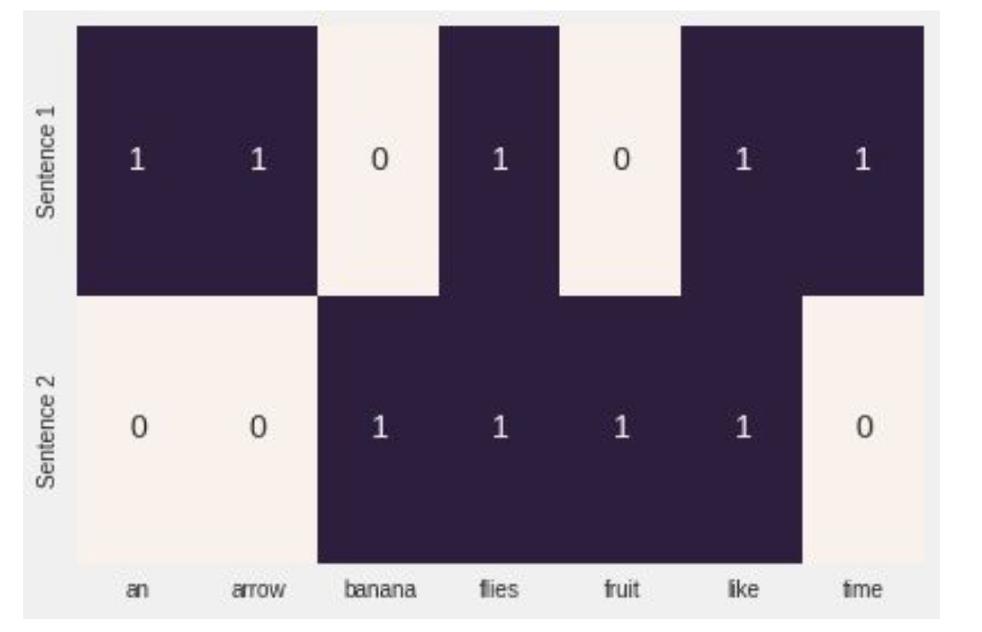
折叠的单热是一个向量中有多个 1 的单热
TF-IDF 表示
考虑一组专利文件。您可能希望它们中的大多数都有诸如claim、system、method、procedure等单词,并且经常重复多次。TF 表示对更频繁的单词进行加权。然而,像claim这样的常用词并不能增加我们对具体专利的理解。相反,如果tetrafluoroethylene这样罕见的词出现的频率较低,但很可能表明专利文件的性质,我们希望在我们的表述中赋予它更大的权重。反文档频率(IDF)是一种启发式算法,可以精确地做到这一点。
IDF 表示惩罚常见的符号,并奖励向量表示中的罕见符号。 符号w的IDF(w)对语料库的定义为
其中n[w]是包含单词w的文档数量,N是文档总数。TF-IDF 分数就是TF(w) * IDF(w)的乘积。首先,请注意在所有文档(例如,n[w] = N), IDF(w)为 0, TF-IDF 得分为 0,完全惩罚了这一项。其次,如果一个术语很少出现(可能只出现在一个文档中),那么 IDF 就是log n的最大值。
示例 1-2:使用 sklearn 生产 TF-IDF 表示
from sklearn.feature_extraction.text import TfidfVectorizer
import seaborn as sns
tfidf_vectorizer = TfidfVectorizer()
tfidf = tfidf_vectorizer.fit_transform(corpus).toarray()
sns.heatmap(tfidf, annot=True, cbar=False, xticklabels=vocab,
yticklabels= ['Sentence 1', 'Sentence 2'])
在深度学习中,很少看到使用像 TF-IDF 这样的启发式表示对输入进行编码,因为目标是学习一种表示。
通常,我们从一个使用整数索引的单热编码和一个特殊的“嵌入查找”层开始构建神经网络的输入。在后面的章节中,我们将给出几个这样做的例子。
目标编码
正如“监督学习范式”所指出的,目标变量的确切性质取决于所解决的 NLP 任务。例如,在机器翻译、摘要和回答问题的情况下,目标也是文本,并使用前面描述的单热编码方法进行编码。
许多 NLP 任务实际上使用分类标签,其中模型必须预测一组固定标签中的一个。对此进行编码的一种常见方法是对每个标签使用惟一索引。当输出标签的数量太大时,这种简单的表示可能会出现问题。这方面的一个例子是语言建模问题,在这个问题中,任务是预测下一个单词,给定过去看到的单词。标签空间是一种语言的全部词汇,它可以很容易地增长到几十万,包括特殊字符、名称等等。我们将在后面的章节中重新讨论这个问题以及如何解决这个问题。
一些 NLP 问题涉及从给定文本中预测一个数值。例如,给定一篇英语文章,我们可能需要分配一个数字评分或可读性评分。给定一个餐馆评论片段,我们可能需要预测直到小数点后第一位的星级。给定用户的推文,我们可能需要预测用户的年龄群。有几种方法可以对数字目标进行编码,但是将目标简单地绑定到分类“容器”中(例如,“0-18”、“19-25”、“25-30”等等),并将其视为有序分类问题是一种合理的方法。 绑定可以是均匀的,也可以是非均匀的,数据驱动的。虽然关于这一点的详细讨论超出了本书的范围,但是我们提请您注意这些问题,因为在这种情况下,目标编码会显著影响性能,我们鼓励您参阅 Dougherty 等人(1995)及其引用。
计算图
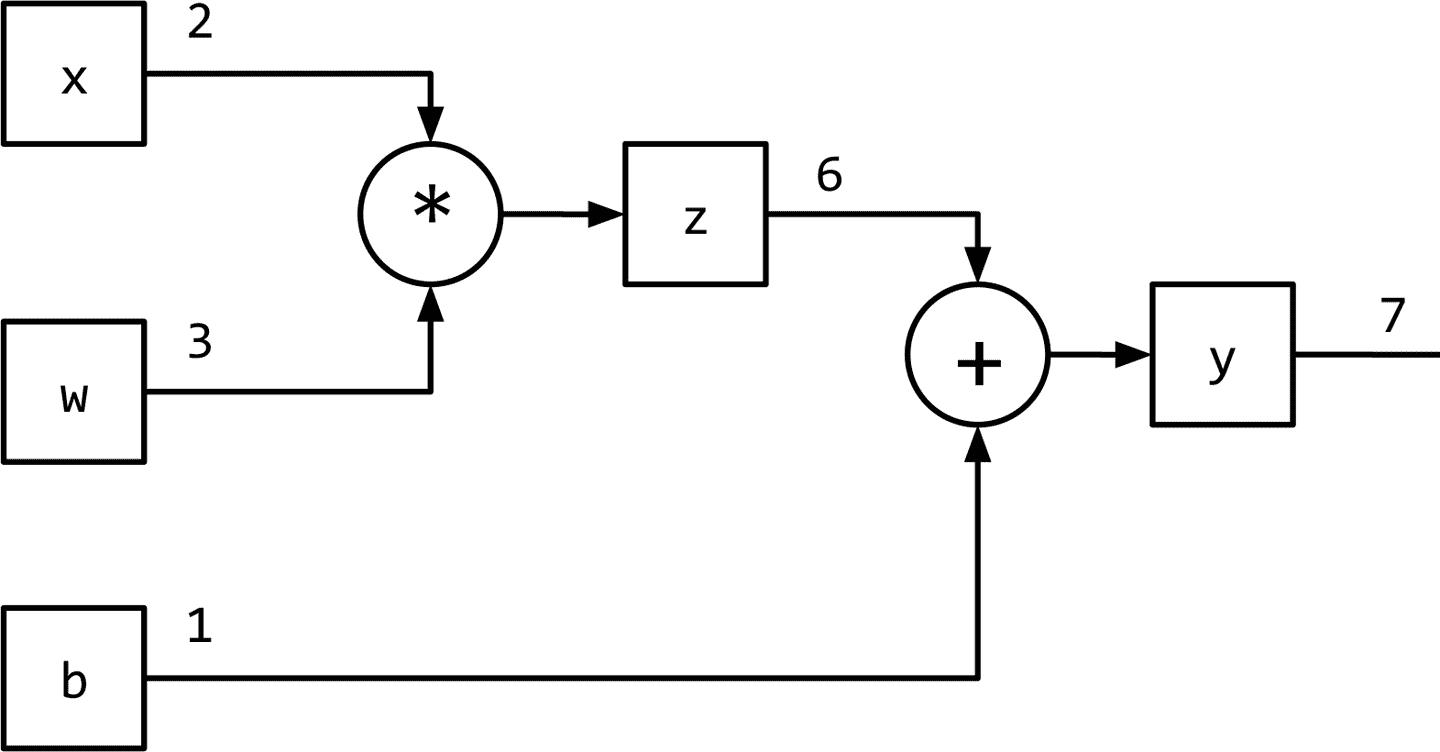
图 1-1 将监督学习(训练)范式概括为数据流架构,模型(数学表达式)对输入进行转换以获得预测,损失函数(另一个表达式)提供反馈信号来调整模型的参数。利用计算图数据结构可以方便地实现该数据流。从技术上讲,计算图是对数学表达式建模的抽象。在深度学习的上下文中,计算图的实现(如 Theano、TensorFlow 和 PyTorch)进行了额外的记录(bookkeeping),以实现在监督学习范式中训练期间获取参数梯度所需的自动微分。我们将在“PyTorch 基础知识”中进一步探讨这一点。推理(或预测)就是简单的表达式求值(计算图上的正向流)。让我们看看计算图如何建模表达式。考虑表达式:y=wx+b
这可以写成两个子表达式z = wx和y = z + b,然后我们可以用一个有向无环图(DAG)表示原始表达式,其中的节点是乘法和加法等数学运算。操作的输入是节点的传入边,操作的输出是传出边。
因此,对于表达式y = wx + b,计算图如图 1-6 所示。在下一节中,我们将看到 PyTorch 如何让我们以一种直观的方式创建计算图形,以及它如何让我们计算梯度,而无需考虑任何记录(bookkeeping)。
引用说明
译者:Yif Du
所有模型都是错的,但其中一些是有用的。
本书旨在为新人提供自然语言处理(NLP)和深度学习,以涵盖这两个领域的重要主题。这两个主题领域都呈指数级增长。对于一本介绍深度学习和强调实施的 NLP 的书,本书占据了重要的中间地带。
在写这本书时,我们不得不对哪些材料遗漏做出艰难的,有时甚至是不舒服的选择。对于初学者,我们希望本书能够为基础知识提供强有力的基础,并可以瞥见可能的内容。特别是机器学习和深度学习是一种经验学科,而不是智力科学。我们希望每章中慷慨的端到端代码示例邀请您参与这一经历。当我们开始编写本书时,我们从 PyTorch 0.2 开始。每个 PyTorch 更新从 0.2 到 0.4 修改了示例。
PyTorch 1.0 将于本书出版时发布。本书中的代码示例符合 PyTorch 0.4,它应该与即将发布的 PyTorch 1.0 版本一样工作。 关于本书风格的注释。
我们在大多数地方都故意避免使用数学;并不是因为深度学习数学特别困难(事实并非如此),而是因为它在许多情况下分散了本书主要目标的注意力——增强初学者的能力。在许多情况下,无论是在代码还是文本方面,我们都有类似的动机,我们倾向于对简洁性进行阐述。
高级读者和有经验的程序员可以找到方法来收紧代码等等,但我们的选择是尽可能明确,以便覆盖我们想要达到的大多数受众。
贡献指南
本项目需要校对,欢迎大家提交 Pull Request。
请您勇敢地去翻译和改进翻译。虽然我们追求卓越,但我们并不要求您做到十全十美,因此请不要担心因为翻译上犯错——在大部分情况下,我们的服务器已经记录所有的翻译,因此您不必担心会因为您的失误遭到无法挽回的破坏。(改编自维基百科)
联系方式
负责人
- 飞龙: 562826179
其他
- 在我们的 apachecn/nlp-pytorch-zh github 上提 issue.
- 发邮件到 Email:
apachecn@163.com. - 在我们的 组织学习交流群 中联系群主/管理员即可.
下载
Docker
docker pull apachecn0/nlp-pytorch-zh
docker run -tid -p <port>:80 apachecn0/nlp-pytorch-zh
# 访问 http://localhost:{port} 查看文档
PYPI
pip install nlp-pytorch-zh
nlp-pytorch-zh <port>
# 访问 http://localhost:{port} 查看文档
NPM
npm install -g nlp-pytorch-zh
nlp-pytorch-zh <port>
# 访问 http://localhost:{port} 查看文档
- PyTorch 自然语言处理
- 一、基础介绍
- 二、传统 NLP 快速回顾
- 三、神经网络基础组件
- 四、自然语言处理的前馈网络
- 五、嵌入单词和类型
- 六、自然语言处理的序列模型
- 七、自然语言处理的进阶序列模型
- 八、自然语言处理的高级序列模型
- 九、经典, 前沿和后续步骤
本人出于学习的目的,引用本书内容,非商业用途,推荐大家阅读此书,一起学习!!!
加油!
感谢!
努力!
以上是关于开山篇自然语言处理(PyTorch版)的主要内容,如果未能解决你的问题,请参考以下文章