搞到你手软Selenium 自动化访问CSDN大牛的全部文章
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搞到你手软Selenium 自动化访问CSDN大牛的全部文章相关的知识,希望对你有一定的参考价值。
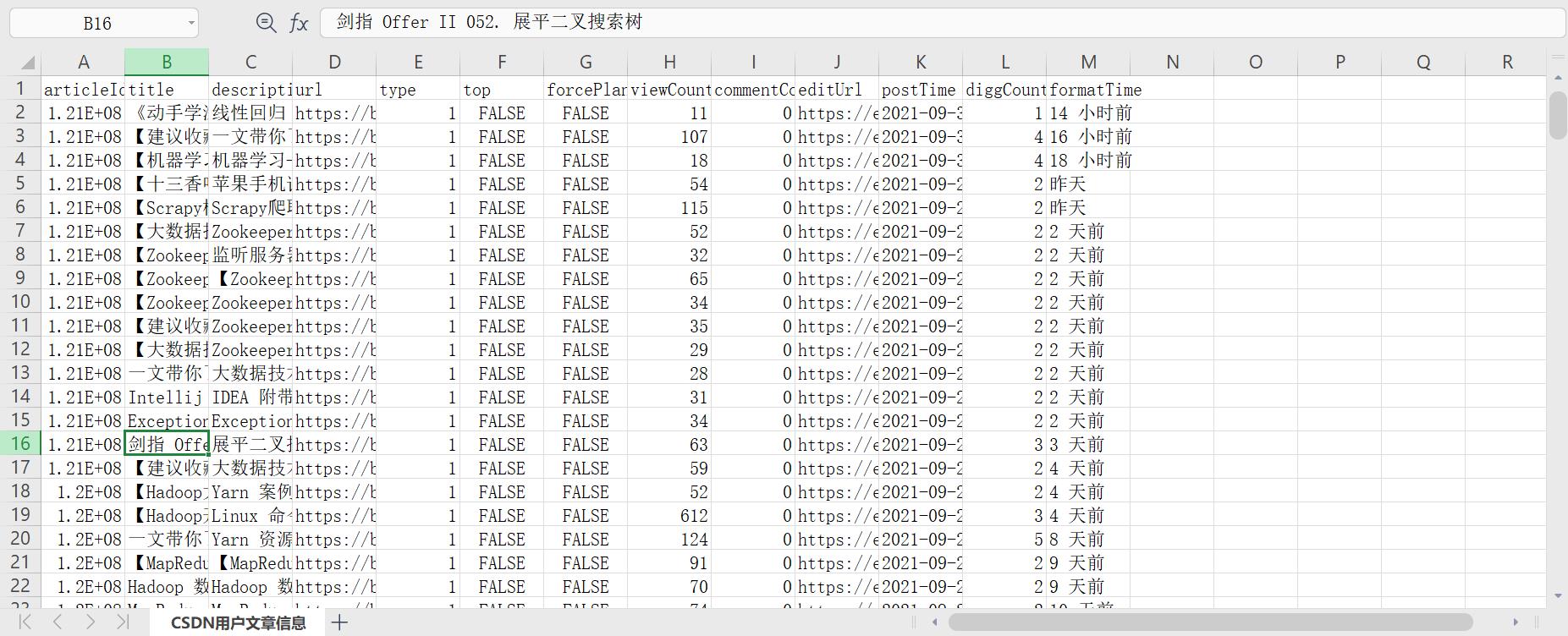
1. 获取数据
2. 初始化
def __init__(self, path):
# 获取driver驱动
self.driver = webdriver.Chrome()
# 获取工作表
self.ws = openpyxl.load_workbook(path).active
3. 自动化测试
def autoAccessArtical(self):
# print(type(self.ws.rows)) # <class 'generator'>
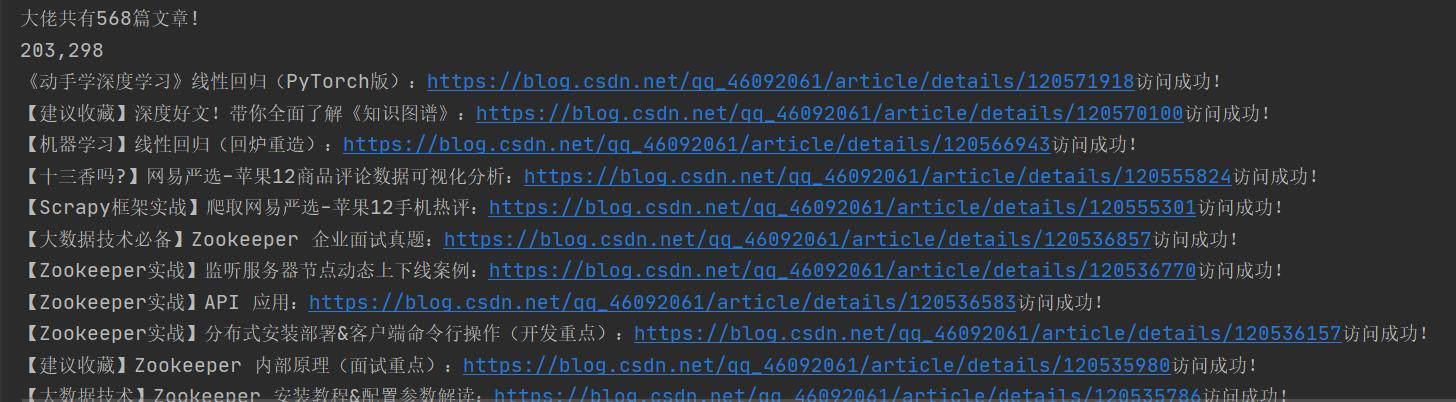
print("大佬共有{}篇文章!".format(self.ws.max_row)) # 568
# 当前访问量
self.driver.get('https://blog.csdn.net/qq_46092061?spm=1001.2014.3001.5343')
visits1 = self.driver.find_element_by_xpath('//*[@id="floor-user-profile_485"]/div/div[1]/div[2]/div[3]/ul/li[1]/div[1]').text
print(visits1)
# 获取URL和title整列
urls = self.ws['D'][1:]
titles = self.ws['B'][1:]
# print(type(urls)) # <class 'tuple'>
for url, title in zip(urls, titles):
# 访问url
self.driver.get(url.value)
time.sleep(2)
# 获取文章title
print('{}:{}访问成功!'.format(title.value, url.value), end='\\n')
# 最后的访问量
self.driver.get('https://blog.csdn.net/qq_46092061?spm=1001.2014.3001.5343')
visits2 = self.driver.find_element_by_xpath('//*[@id="floor-user-profile_485"]/div/div[1]/div[2]/div[3]/ul/li[1]/div[1]').text
print('第一次访问量:{}\\n第二次访问量:{}\\n'.format(visits1, visits2))
4. 完整代码
if __name__ == '__main__':
# 实例化一个对象
csdn = CSDN('CSDN用户文章信息.xlsx')
# 调用方法
csdn.autoAccessArtical()
print('自动化测试成功!')
# 退出模拟浏览器
csdn.driver.quit() # 一定要退出!不退出会有残留进程!
5. 结果展示
仅供学习!
加油!
感谢!
努力!
以上是关于搞到你手软Selenium 自动化访问CSDN大牛的全部文章的主要内容,如果未能解决你的问题,请参考以下文章