mybatis的缓存机制源码分析之二级缓存解析
Posted 犀牛饲养员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mybatis的缓存机制源码分析之二级缓存解析相关的知识,希望对你有一定的参考价值。
引言
本篇源码解析基于mybatis 3.5.8版本。
MyBatis 中的缓存指的是 MyBatis 在执行一次SQL查询时,在满足一定的条件下,会把这个sql和对应的查询结果缓存起来。当再次执行相同SQL语句的时候,就会直接从缓存中进行提取,而不是请求到数据库。当然如果中间有更新操作,缓存会失效。
MyBatis中的缓存分为一级缓存和二级缓存,一级缓存又被称为 SqlSession 级别的缓存,二级缓存又被称为表级缓存。通俗的说,一级缓存是本次会话有效,二级缓存可以跨越多个会话共享缓存。
当开启缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -> 数据库。
本篇我们关注二级缓存,一级缓存请查看文章:
正文
开启二级缓存的配置是:
<setting name="cacheEnabled" value="true"/>
二级缓存开启后,同一个namespace下的所有操作语句,都影响着同一个Cache,即二级缓存被多个SqlSession共享,是一个全局的变量。
二级缓存也可以认为是表级别的缓存,因为通常我们在代码里定义mapper文件类似下面这种:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.xxx.yyy.mapper.TestOrderMapper" >
<resultMap id="BaseResultMap" type="com.xxx.yyy.model.TestOrder" >
<!--
WARNING - @mbggenerated
This element is automatically generated by MyBatis Generator, do not modify.
This element was generated on Wed Aug 21 08:47:05 CST 2019.
-->
<id column="id" property="id" jdbcType="BIGINT" />
<result column="order_id" property="orderId" jdbcType="VARCHAR" />
...
一个mapper文件里面有一个namespace,对应一个表的所有增删改查操作。
二级缓存使用的缓存管理类是CachingExecutor,它的初始化在org.apache.ibatis.session.Configuration#newExecutor方法中:
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
...
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
//如果二级缓存开关开启的话,是使用CahingExecutor装饰BaseExecutor的子类
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
...
类关系图如下:
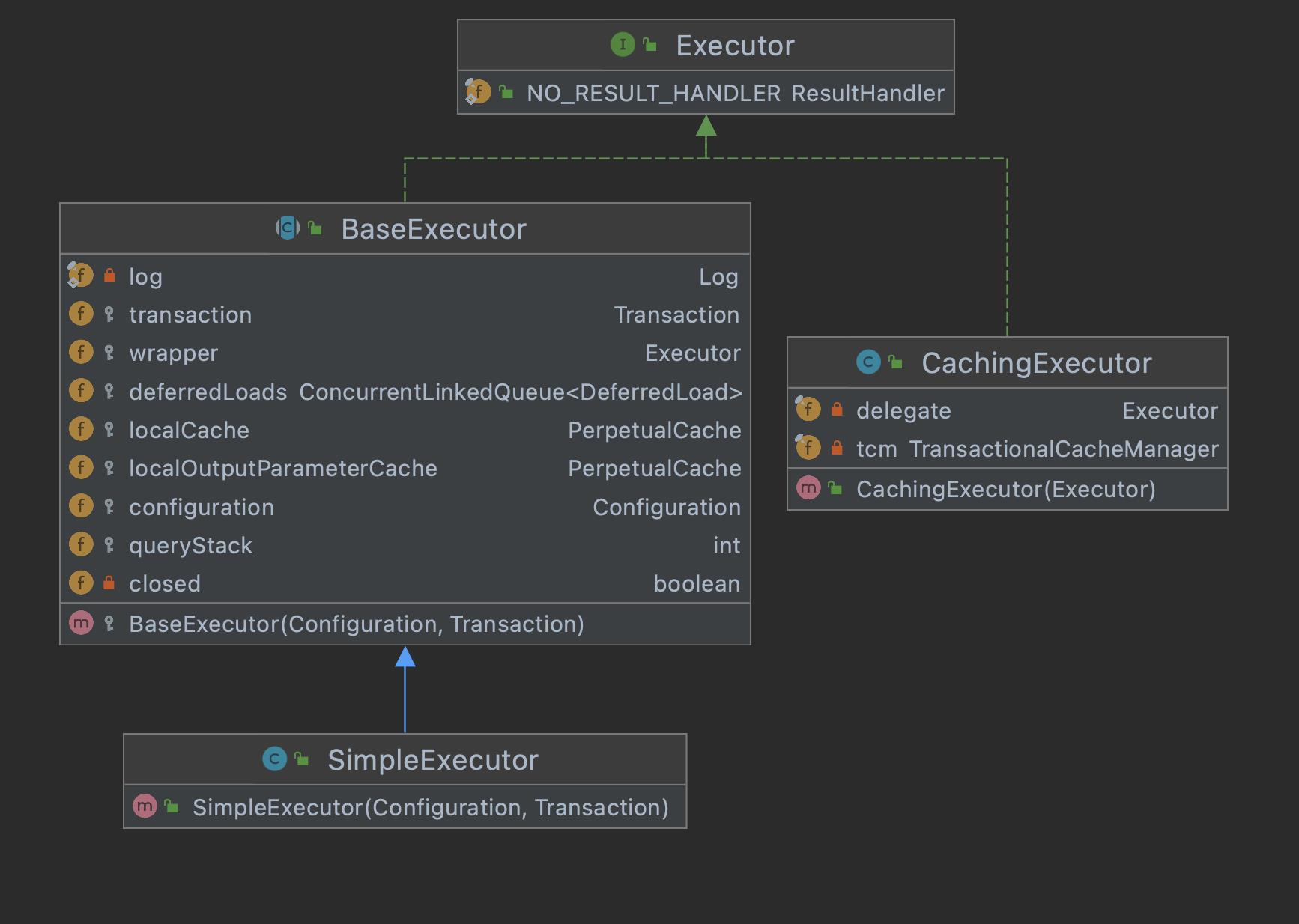
可以看到CachingExecutor持有一个Executor的委托,这就是装饰器模式。CachingExecutor在委托给代理类执行之前,先用自己的逻辑进行装饰,这也是二级缓存实现的关键。
我们通过query方法看看具体的逻辑:
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
//判断是否需要刷新缓存,默认情况下select不需要刷新,update/delete/insert需要
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
//从缓存获取数据
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//如果二级缓存没命中,使用代理进入一级缓存的逻辑
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
首先从MappedStatement获取cache的实例,如果获取不到,直接通过代理进入一级缓存的查询逻辑了。
flushCacheIfRequired判断是否需要刷新缓存。
这里的重点是tcm,可以看到缓存的数据是从这里获取的,tcm是TransactionalCacheManager的实例,用来实现缓存的事务管理。来看看:
public class TransactionalCacheManager {
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
...
TransactionalCacheManager持有一个map,key是Cache本身,value是TransactionalCache,是对Cache做了一层包装,这层包装是实现事务的关键。我们来看下TransactionalCacheManager的put方法:
@Override
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}
entriesToAddOnCommit是个map,
private final Map<Object, Object> entriesToAddOnCommit;
然后看下get方法,
@Override
public Object getObject(Object key) {
// issue #116
Object object = delegate.getObject(key);
if (object == null) {
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}
是不是觉得比较奇怪,为啥put方法放到一个本地的map,但是get方法居然是从delegate拿数据,其实这就是事务缓存的关键。当我们使用put方法提交数据时只是把缓存临时放到了内存里,并没有使缓存真正生效。那么什么时候生效呢?
我们来看下TransactionalCache的commit方法,
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();
reset();
}
然后看看flushPendingEntries方法,
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
看到了没,只有调用了commit方法才会触发缓存提交。那么commit方法什么时候调用呢?如果你顺着链路往上找,会发现最终调用者是:org.apache.ibatis.session.defaults.DefaultSqlSession#commit(boolean)。原来最终是被sql session的commit方法调用的。
最后,如果获取的list为空,通过代理类进入了一级缓存的流程,这部分前面已经有文章解析了。
参考
- https://tech.meituan.com/2018/01/19/mybatis-cache.html
以上是关于mybatis的缓存机制源码分析之二级缓存解析的主要内容,如果未能解决你的问题,请参考以下文章