[人工智能-深度学习-19]:神经网络基础 - 模型训练 - 泛化过拟合欠拟合以及常见的解决办法
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-深度学习-19]:神经网络基础 - 模型训练 - 泛化过拟合欠拟合以及常见的解决办法相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120591865
目录
第1章 学习效果评估标准与学习效果状态
1.1 概述
机器学习的结果有如下几个评估标准
(1)准确率
大白话就是考试成绩,有100道题,能做对多少。分数越高,预测准确率越高。
(2)误差、偏差
偏差是指偏离真实值的程度和大小。由于分类是离散的,而不是连续量,准确率高,并不代表误差小。
(3)泛化能力
泛化能力,把学习到的内容,应用到新的领域的能力。
泛化能力差有两个主要表现:欠拟合与过拟合。
1.2 泛化能力
泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力。
学习的目的是学到隐含在数据背后的规律,对具有同一规律的、学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。
简而言之是在原有的数据集上添加新的数据集,通过训练输出一个合理的结果,这就是泛化能力。
通常期望经训练样本训练的网络具有较强的泛化能力,也就是对新输入给出合理响应的能力。
应当指出并非训练的次数越多越能得到正确的输入输出映射关系。
网络的性能主要用它的泛化能力(而不仅仅是准确率)来衡量。
1.3 学习训练后的三种状态
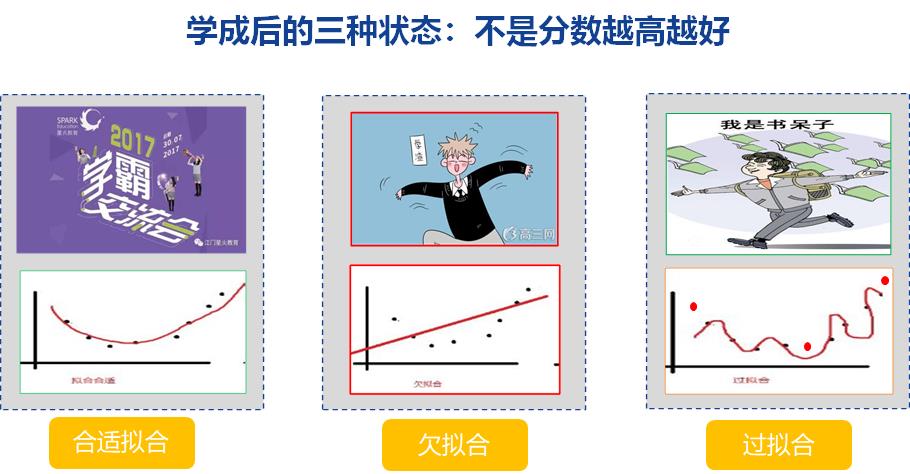
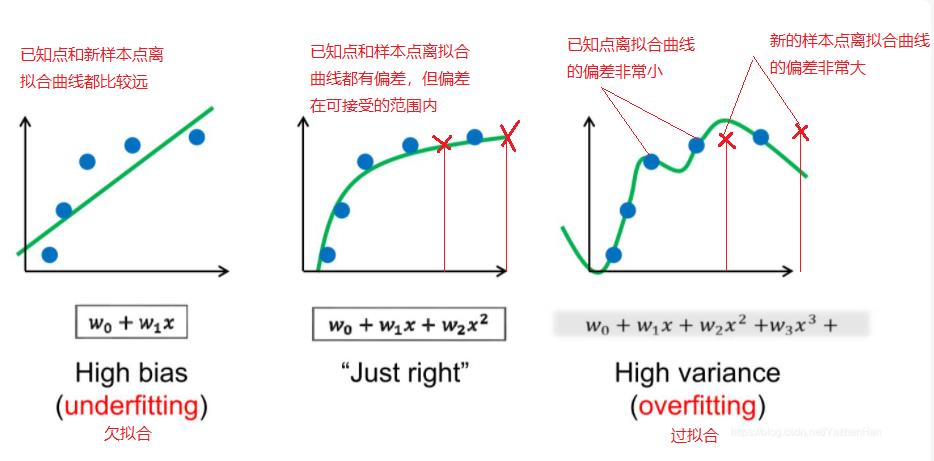
(1)适当拟合:
学业有成,能力强,在新的工作岗位尤鱼得水。
学习好,泛化能力强。
(2)欠拟合
考试成绩差,在新工作岗位上,能力水平差。典型的学渣型结果。
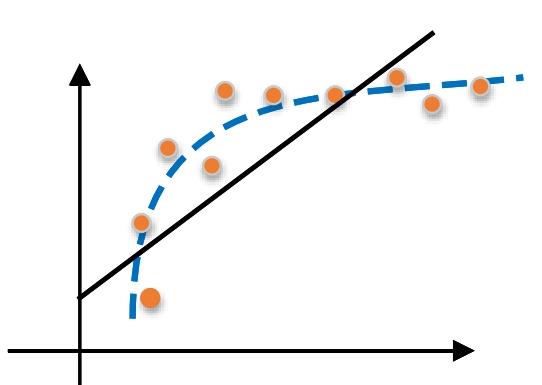
对于训练好的模型,若在训练集表现差,在验证数据集和测试集表现同样会很差,这可能是欠拟合导致。
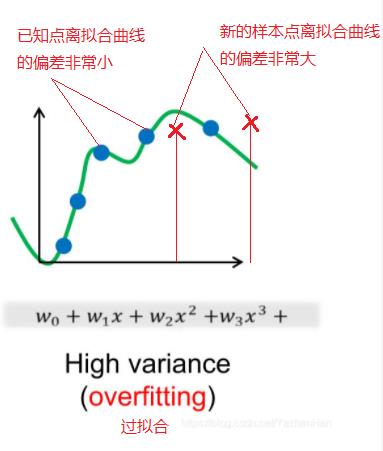
(3)过拟合
就是平时考试都是高分,甚至100分,但遇到新题,遇到新考试,总是不及格。
第2章 泛化能力差的解决办法
2.1 欠拟合的解决办法
欠拟合的情况比较容易克服, 常见解决方法有:
-
增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间;(增加输入数据的维度)
-
添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强;(用更高阶的函数进行拟合)
-
减少正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数;
-
使用非线性模型,比如核SVM 、决策树、深度学习等模型;(新模型)
-
调整模型的容量(capacity),通俗地,模型的容量是指其拟合各种函数的能力;
-
容量低的模型可能很难拟合训练集;使用集成学习方法,如Bagging ,将多个弱学习器Bagging。
-
增加样本的数量
-
增加训练的次数
-
减少学习率,减少学习的步长,增加学习的精度
2.2 过拟合的解决办法
(1)增加训练集的数据量
over-fitting的一个形成原因就是训练集的数据太少导致无法学习到想要的模型,因此当发生over-fitting时首先应该考虑的就应该是增加训练集的数据量,理论上来说只要数据集足够大就不会发生over-fitting和under-fitting,但是很明显数据集的收集和制作是个很大的工作量,因此就需要下面的几个常用办法。
(2)正则化方法
正则化方法是指在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
第3章 偏差与方差
偏差又称为表观误差,是指个别测定值与测定的平均值之差,它可以用来衡量测定结果的精密度高低。这是评判学习成绩好坏的标准。
在统计学中,偏差可以用于两个不同的概念,即有偏采样与有偏估计。一个有偏采样是对总样本集非平等采样,而一个有偏估计则是指高估或低估要估计的量。方差在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。
在机器学习中,偏差描述的是根据样本拟合出的模型输出结果与真实结果的差距,损失函数就是依据模型偏差的大小进行反向传播的。降低偏差,就需要复杂化模型,增加模型参数,但容易造成过拟合。方差描述的是样本上训练出的模型在测试集上的表现,降低方差,继续要简化模型,减少模型的参数,但容易造成欠拟合。根本原因是,我们总是希望用有限的训练样本去估计无限的真实数据。假定我们可以获得所有可能的数据集合,并在这个数据集上将损失函数最小化,则这样的模型称之为“真实模型”。但实际应用中,并不能获得且训练所有可能的数据,所以真实模型一定存在,但无法获得
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120591865
以上是关于[人工智能-深度学习-19]:神经网络基础 - 模型训练 - 泛化过拟合欠拟合以及常见的解决办法的主要内容,如果未能解决你的问题,请参考以下文章
Tensorflow+Keras 深度学习人工智能实践应用 Chapter Two 深度学习原理
人工智能机器学习深度学习神经网络,都有什么区别,卷积神经网络和全连接神经网络的区别
人工智能机器学习深度学习神经网络,都有什么区别,卷积神经网络和全连接神经网络的区别