评论区抽奖程序
Posted 布小禅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了评论区抽奖程序相关的知识,希望对你有一定的参考价值。
评论区抽奖程序
这个小程序很简陋,没什么难度
1. 思路
- 使用爬虫爬取评论区数据
- 随机抽取一名幸运用户
思路很简单,实现也很简单
2. 准备
- 新建一个py文件,命名为
talkprize.py - 导入相关模块
requests
import random
import requests
import json
import jsonpath
3. 实现爬虫爬取数据
先打开送书文章链接:https://blog.csdn.net/m0_52883898/article/details/120535359
右键检查,先拿到请求头和cookie,然后存入head字典中
head = {
"user-agent": "xxxx",
"Cookie": "xxx"
}
# 将url存入变量url
url = 'https://blog.csdn.net/m0_52883898/article/details/120535359'
然后放入get方法,输出文本,看看源码
print(requests.get(url=url, headers=head).text)
在控制台会输出源码,回到浏览器界面的检查界面,点击检查界面的左上角的小手,点击到左边的评论区界面,找到一个属性,在源码界面使用组合键ctrl+f搜索,发现搜索不到
说明评论区不在本页面的html代码中,转换思路,查找json数据,找到了评论区接口
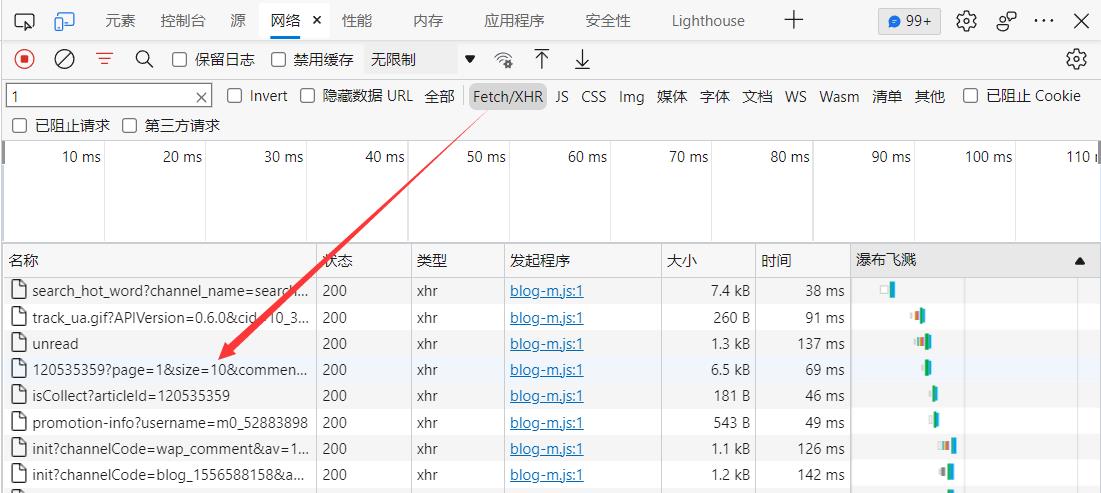
点开查看url:

发现了一个page参数,这个参数是代表几页,不要问为什么,这是经验。
回到评论区,你会发现我们的评论区是分了好几页的,所以我们就不使用爬虫爬这个页数了,虽然这很帅~~
然后我们定一个获取评论数据的函数
def get_name(head, num):
"""总共几页循环几次"""
ans = [] # 返回值
for i in range(num):
url = "https://blog.csdn.net/phoenix/web/v1/comment/list/120535359?page=%d&size=10&comment_id=" % (i+1)
get_html = requests.post(url, headers=head).content # 获取评论区数据
json_data = json.loads(get_html) # 转为python数据
name_li = jsonpath.jsonpath(json_data, '$..nickName')
ans += name_li
return ans
我们直接使用格式化字符串拼接这个参数,设置三次循环获取全部评论区数据
获取完数据使用json模块转为python数据类型,然后使用jsonpath提取评论名字
$..nickName
从根节点的所有节点获取所有nicjName属性的数据
并将数据添加进一个ans,将其返回
4. 随机数模块抽取
定义一个函数实现随机抽取一个评论用户,需要使用随机数模块的randit方法
def chou_jiang(li):
"""
随机数函数抽奖
参数为评论用户的用户名
:param li:
:return: None
"""
i = len(li)
j = random.randint(0, i-1)
return li[j]
然后就OK了
5. main函数
在main函数中设置几个变量,分别为:
- head —— 存储cookie和请求头
- name_list —— 所有评论用户列表
- user —— 获奖名单
if __name__ == '__main__':
head = {
"user-agent": "你自己的请求头",
"Cookie": "你自己的cookie"
}
name_list = get_name(head, 3)
prize_user = chou_jiang(name_list)
print("获奖者是:", prize_user)
6. 大功告成
右键运行你的程序,就大功告成啦~~
以上是关于评论区抽奖程序的主要内容,如果未能解决你的问题,请参考以下文章