欢度国庆⭐️共享爬虫之美⭐️基于 Python 实现微信公众号爬虫(Python无所不能爬)
Posted zhulin1028
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了欢度国庆⭐️共享爬虫之美⭐️基于 Python 实现微信公众号爬虫(Python无所不能爬)相关的知识,希望对你有一定的参考价值。
此文章撰写于国庆假期,以此纪念。祝大家万事大吉,心想事成,家和万事兴!国庆快乐!
目录
微信公众号爬虫的基本原理
网上关于爬虫的教程多如牛毛,但很少有看到微信公众号爬虫教程,要有也是基于搜狗微信的,不过搜狗提供的数据有诸多弊端,比如文章链接是临时的,文章没有阅读量等指标,所以我想写一个比较系统的关于如何通过手机客户端利用 Python 爬微信公众号文章的教程,并对公众号文章做数据分析,为更好的运营公众号提供决策。
爬虫的基本原理
所谓爬虫就是一个自动化数据采集工具,你只要告诉它要采集哪些数据,丢给它一个 URL,就能自动地抓取数据了。其背后的基本原理就是爬虫程序向目标服务器发起 HTTP 请求,然后目标服务器返回响应结果,爬虫客户端收到响应并从中提取数据,再进行数据清洗、数据存储工作。
爬虫的基本流程
爬虫流程也是一个 HTTP 请求的过程,以浏览器访问一个网址为例,从用户输入 URL 开始,客户端通过 DNS 解析查询到目标服务器的 IP 地址,然后与之建立 TCP 连接,连接成功后,浏览器构造一个 HTTP 请求发送给服务器,服务器收到请求之后,从数据库查到相应的数据并封装成一个 HTTP 响应,然后将响应结果返回给浏览器,浏览器对响应内容进行数据解析、提取、渲染并最终展示在你面前。

HTTP 协议的请求和响应都必须遵循固定的格式,只有遵循统一的 HTTP 请求格式,服务器才能正确解析不同客户端发的请求,同样地,服务器遵循统一的响应格式,客户端才得以正确解析不同网站发过来的响应。
HTTP 请求格式
HTTP 请求由请求行、请求头、空行、请求体组成。
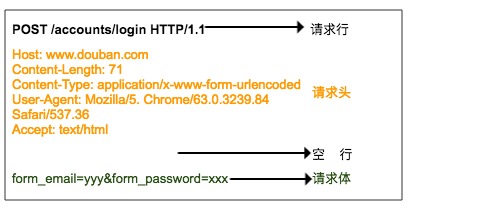
请求行由三部分组成:
- 第一部分是请求方法,常见的请求方法有 GET、POST、PUT、DELETE、HEAD
- 第二部分是客户端要获取的资源路径
- 第三部分是客户端使用的 HTTP 协议版本号
请求头是客户端向服务器发送请求的补充说明,比如 User-Agent 向服务器说明客户端的身份。
请求体是客户端向服务器提交的数据,比如用户登录时需要提高的账号密码信息。请求头与请求体之间用空行隔开。请求体并不是所有的请求都有的,比如一般的GET都不会带有请求体。
上图就是浏览器登录豆瓣时向服务器发送的HTTP POST 请求,请求体中指定了用户名和密码。
HTTP 响应格式
HTTP 响应格式与请求的格式很相似,也是由响应行、响应头、空行、响应体组成。
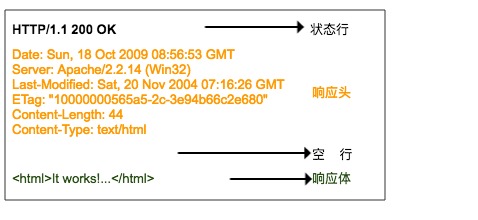
响应行也包含三部分,分别是服务端的 HTTP 版本号、响应状态码、状态说明,响应状态码常见有 200、400、404、500、502、304 等等,一般以 2 开头的表示服务器正常响应了客户端请求,4 开头表示客户端的请求有问题,5 开头表示服务器出错了,没法正确处理客户端请求。状态码说明就是对该状态码的一个简短描述。
第二部分就是响应头,响应头与请求头对应,是服务器对该响应的一些附加说明,比如响应内容的格式是什么,响应内容的长度有多少、什么时间返回给客户端的、甚至还有一些 Cookie 信息也会放在响应头里面。
第三部分是响应体,它才是真正的响应数据,这些数据其实就是网页的 html 源代码。
使用 Requests 实现一个简单网页爬虫
Python 提供了非常多工具去实现 HTTP 请求,但第三方开源库提供的功能更丰富,你无需从 socket 通信开始写,比如使用Pyton内建模块 urllib 请求一个 URL 代码示例如下:
import ssl from urllib.request;
import Request from urllib.request;
import urlopen context = ssl._create_unverified_context()
# HTTP 请求
request = Request(url="https://foofish.net/pip.html", method="GET", headers={"Host": "foofish.net"}, data=None) # HTTP 响应
response = urlopen(request, context=context) headers = response.info() # 响应头
content = response.read() # 响应体
code = response.getcode() # 状态码发起请求前首先要构建请求对象 Request,指定 url 地址、请求方法、请求头,这里的请求体 data 为空,因为你不需要提交数据给服务器,所以你也可以不指定。urlopen 函数会自动与目标服务器建立连接,发送 HTTP 请求,该函数的返回值是一个响应对象 Response,里面有响应头信息,响应体,状态码之类的属性。
但是,Python 提供的这个内建模块过于低级,需要写很多代码,使用简单爬虫可以考虑 Requests,Requests 在GitHub 有近30k的Star,是一个很Pythonic的框架。先来简单熟悉一下这个框架的使用方式
安装 requests
pip install requestsGET 请求
>>> r = requests.get("https://httpbin.org/ip")
>>> r
<Response [200]> # 响应对象
>>> r.status_code # 响应状态码 200
>>> r.content # 响应内容
'{\\n "origin": "183.237.232.123"\\n}\\n'POST 请求
>>> r = requests.post('http://httpbin.org/post', data = {'key':'value'})自定义请求头
这个经常会用到,服务器反爬虫机制会判断客户端请求头中的User-Agent是否来源于真实浏览器,所以,我们使用Requests经常会指定UA伪装成浏览器发起请求
>>> url = 'https://httpbin.org/headers'
>>> headers = {'user-agent': 'Mozilla/5.0'}
>>> r = requests.get(url, headers=headers)参数传递
很多时候URL后面会有一串很长的参数,为了提高可读性,requests 支持将参数抽离出来作为方法的参数(params)传递过去,而无需附在 URL 后面,例如请求 url http://bin.org/get?key=val ,可使用
>>> url = "http://httpbin.org/get"
>>> r = requests.get(url, params={"key":"val"})
>>> r.url u'http://httpbin.org/get?key=val'指定Cookie
Cookie 是web浏览器登录网站的凭证,虽然 Cookie 也是请求头的一部分,我们可以从中剥离出来,使用 Cookie 参数指定
>>> s = requests.get('http://httpbin.org/cookies', cookies={'from-my': 'browser'})
>>> s.text
u'{\\n "cookies": {\\n "from-my": "browser"\\n }\\n}\\n'设置超时
当发起一个请求遇到服务器响应非常缓慢而你又不希望等待太久时,可以指定 timeout 来设置请求超时时间,单位是秒,超过该时间还没有连接服务器成功时,请求将强行终止。
r = requests.get('https://google.com', timeout=5)设置代理
一段时间内发送的请求太多容易被服务器判定为爬虫,所以很多时候我们使用代理IP来伪装客户端的真实IP。
import requests
proxies = { 'http': 'http://127.0.0.1:1080', 'https': 'http://127.0.0.1:1080', }
r = requests.get('http://www.kuaidaili.com/free/', proxies=proxies, timeout=2)Session
如果想和服务器一直保持登录(会话)状态,而不必每次都指定 cookies,那么可以使用 session,Session 提供的API和 requests 是一样的。
import requests
s = requests.Session()
s.cookies = requests.utils.cookiejar_from_dict({"a": "c"})
r = s.get('http://httpbin.org/cookies')
print(r.text)
# '{"cookies": {"a": "c"}}'
r = s.get('http://httpbin.org/cookies')
print(r.text)
# '{"cookies": {"a": "c"}}'小试牛刀
现在我们使用Requests完成一个爬取知乎专栏用户关注列表的简单爬虫为例,找到任意一个专栏,打开它的关注列表。用 Chrome 找到获取粉丝列表的请求地址:https://www.zhihu.com/api/v4/columns/pythoneer/followers?include=data%5B%2A%5D.follower_count%2Cgender%2Cis_followed%2Cis_following&limit=10&offset=20。 我是怎么找到的?就是逐个点击左侧的请求,观察右边是否有数据出现,那些以 .jpg,js,css 结尾的静态资源可直接忽略。
现在我们用 Requests 模拟浏览器发送请求给服务器,写程序前,我们要先分析出这个请求是怎么构成的,请求URL是什么?请求头有哪些?查询参数有哪些?只有清楚了这些,你才好动手写代码,掌握分析方法很重要,否则一头雾水。
回到前面那个URL,我们发现这个URL是获取粉丝列表的接口,然后再来详细分析一下这个请求是怎么构成的。
- 请求URL:https://www.zhihu.com/api/v4/columns/pythoneer/followers
- 请求方法:GET
- user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
- 查询参数:
- include: data[*].follower_count,gender,is_followed,is_following
- offset: 0
- limit: 10
利用这些请求数据我们就可以用requests这个库来构建一个请求,通过Python代码来抓取这些数据。
import requests
class SimpleCrawler:
def crawl(self, params=None):
# 必须指定UA,否则知乎服务器会判定请求不合法
url = "https://www.zhihu.com/api/v4/columns/pythoneer/followers"
# 查询参数
params = {"limit": 20,
"offset": 0,
"include": "data[*].follower_count, gender, is_followed, is_following"}
headers = {
"authority": "www.zhihu.com",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
}
response = requests.get(url, headers=headers, params=params)
print("请求URL:", response.url)
# 你可以先将返回的响应数据打印出来,拷贝到 http://www.kjson.com/jsoneditor/ 分析其结构。
print("返回数据:", response.text)
# 解析返回的数据
for follower in response.json().get("data"):
print(follower)
if __name__ == '__main__':
SimpleCrawler().crawl()这就是一个最简单的基于 Requests 的单线程知乎专栏粉丝列表的爬虫,requests 非常灵活,请求头、请求参数、Cookie 信息都可以直接指定在请求方法中,返回值 response 如果是 json 格式可以直接调用json()方法返回 python 对象。关于 Requests 的更多使用方法可以参考官方文档:Requests: HTTP for Humans™ — Requests 2.26.0 documentation
使用 Fiddler 抓包分析公众号请求过程
上一节我们熟悉了 Requests 基本使用方法,配合 Chrome 浏览器实现了一个简单爬虫,但因为微信公众号的封闭性,微信公众平台并没有对外提供 Web 端入口,只能通过手机客户端接收、查看公众号文章,所以,为了窥探到公众号背后的网络请求,我们需要借以代理工具的辅助。
HTTP代理工具又称为抓包工具,主流的抓包工具 Windows 平台有 Fiddler,macOS 有 Charles,阿里开源了一款工具叫 AnyProxy。它们的基本原理都是类似的,就是通过在手机客户端设置好代理IP和端口,客户端所有的 HTTP、HTTPS 请求就会经过代理工具,在代理工具中就可以清晰地看到每个请求的细节,然后可以分析出每个请求是如何构造的,弄清楚这些之后,我们就可以用 Python 模拟发起请求,进而得到我们想要的数据。
Fiddler 下载地址是 Download Fiddler Web Debugging Tool for Free by Telerik,安装包就 4M 多,在配置之前,首先要确保你的手机和电脑在同一个局域网,如果不在同一个局域网,你可以买个随身WiFi,在你电脑上搭建一个极简无线路由器。安装过程一路点击下一步完成就可以了。
Fiddler 配置
选择 Tools > Fiddler Options > Connections
Fiddler 默认的端口是使用 8888,如果该端口已经被其它程序占用了,你需要手动更改,勾选 Allow remote computers to connect,其它的选择默认配置就好,配置更新后记得重启 Fiddler。一定要重启 Fiddler,否则代理无效。
接下来你需要配置手机,我们以 android 设备为例,现在假设你的手机和电脑已经在同一个局域网(只要连的是同一个路由器就在同局域网内),找到电脑的 IP 地址,在 Fiddler 右上角有个 Online 图标,鼠标移过去就能看到IP了,你也可以在CMD窗口使用 ipconfig 命令查看到
Android 手机代理配置
进入手机的 WLAN 设置,选择当前所在局域网的 WiFi 链接,设置代理服务器的 IP 和端口,我这是以小米设备为例,其它 Android 手机的配置过程大同小异。
测试代理有没有设置成功可以在手机浏览器访问你配置的地址:http://192.168.31.236:8888/ 会显示 Fiddler 的回显页面,说明配置成功。
现在你打开任意一个HTTP协议的网站都能看到请求会出现在 Fiddler 窗口,但是 HTTPS 的请求并没有出现在 Fiddler 中,其实还差一个步骤,需要在 Fiddler 中激活 HTTPS 抓取设置。在 Fiddler 选择 Tools > Fiddler Options > HTTPS > Decrypt HTTPS traffic, 重启 Fiddler。
为了能够让 Fiddler 截取 HTTPS 请求,客户端都需要安装且信任 Fiddler 生成的 CA 证书,否则会出现“网络出错,轻触屏幕重新加载:-1200”的错误。在浏览器打开 Fiddler 回显页面 http://192.168.31.236:8888/ 下载 FiddlerRoot certificate,下载并安装证书,并验证通过。
ios下载安装完成之后还要从 设置->通用->关于本机->证书信任设置 中把 Fiddler 证书的开关打开
Android 手机下载保存证书后从系统设置里面找到系统安全,从SD卡安装证书,如果没有安装证书,打开微信公众号的时候会弹出警告。
至此,所有的配置都完成了,现在打开微信随便选择一个公众号,查看公众号的所有历史文章列表。微信在2018年6月份对 iOS 版本的微信以及部分 Android 版微信针对公众号进行了大幅调整,改为现在的信息流方式,现在要获取某个公众号下面「所有文章列表」大概需要经过以下四个步骤:
如果你的微信版本还不是信息流方式展示的,那么应该是Android版本(微信采用的ABTest,不同的用户呈现的方式不一样)
同时观察 Fiddler 主面板
进入「全部消息」页面时,在 Fiddler 上已经能看到有请求进来了,说明公众号的文章走的都是HTTP协议,这些请求就是微信客户端向微信服务器发送的HTTP请求。
注意:第一次请求「全部消息」的时候你看到的可能是一片空白:
在Fiddler或Charles中看到的请求数据是这样的:
这个时候你要直接从左上角叉掉重新进入「全部消息」页面。
现在简单介绍一下这个请求面板上的每个模块的意义。
这样说明这个请求被微信服务器判定为一次非法的请求,这时你可以叉掉该页面重新进入「全部消息」页面。不出意外的话就能正常看到全部文章列表了,同时也能在Fiddler中看到正常的数据请求了。
我把上面的主面板划分为 7 大块,你需要理解每块的内容,后面才有可能会用 Python 代码来模拟微信请求。
1、服务器的响应结果,200 表示服务器对该请求响应成功
2、请求协议,微信的请求协议都是基 于HTTPS 的,所以前面一定要配置好,不然你看不到 HTTPS 的请求。
3、微信服务器主机名
4、请求路径
5、请求行,包括了请求方法(GET),请求协议(HTTP/1.1),请求路径(/mp/profile_ext...后面还有很长一串参数) 6、包括Cookie信息在内的请求头。
7、微信服务器返回的响应数据,我们分别切换成 TextView 和 WebView 看一下返回的数据是什么样的。
TextView 模式下的预览效果是服务器返回的 HTML 源代码
WebView 模式是 HTML 代码经过渲染之后的效果,其实就是我们在手机微信中看到的效果,只不过因为缺乏样式,所以没有手机上看到的美化效果。
如果服务器返回的是 Json格式或者是 XML,你还可以切换到对应的页面预览查看。
小结
配置好Fiddler的几个步骤主要包括指定监控的端口,开通HTTPS流量解密功能,同时,客户端需要安装CA证书。下一节我们基于Requests模拟像微信服务器发起请求。
抓取第一篇微信公众号文章
打开微信历史消息页面,我们从 Fiddler 看到了很多请求,为了找到微信历史文章的接口,我们要逐个查看 Response 返回的内容,最后发现第 11 个请求 "https://mp.weixin.qq.com/mp/profile_ext?action=home..." 就是我们要寻找的(我是怎么找到的呢?这个和你的经验有关,你可以点击逐个请求,看看返回的Response内容是不是期望的内容)
确定微信公众号的请求HOST是 mp.weixin.qq.com 之后,我们可以使用过滤器来过滤掉不相关的请求。
爬虫的基本原理就是模拟浏览器发送 HTTP 请求,然后从服务器得到响应结果,现在我们就用 Python 实现如何发送一个 HTTP 请求。这里我们使用 requests 库来发送请求。
创建一个 Pycharm 项目
我们使用 Pycharm 作为开发工具,你也可以使用其它你熟悉的工具,Python 环境是 Python3(推荐使用 Python3.6),先创建一个项目 weixincrawler
现在我们来编写一个最粗糙的版本,你需要做两件事:
- 1:找到完整URL请求地址
- 2:找到完整的请求头(headers)信息,Headers里面包括了cookie、User-agent、Host 等信息。
我们直接从 Fiddler 请求中拷贝 URL 和 Headers, 右键 -> Copy -> Just Url/Headers Only
最终拷贝出来的URL很长,它包含了很多的参数:
url = "https://mp.weixin.qq.com/mp/profile_ext" \\
"?action=home" \\
"&__biz=MjM5MzgyODQxMQ==" \\
"&scene=124" \\
"&devicetype=android-24" \\
"&version=26051633&lang=zh_CN" \\
"&nettype=WIFI&a8scene=3" \\
"&pass_ticket=MXADI5SFjXvX7DFPRuUEJhWHEWvRha2x1Re%2BoJkveUxIonMfnxY1kM9cOPmm6JRx" \\
"&wx_header=1"暂且不去分析(猜测)每个参数的意义,也不知道那些参数是必须的,总之我把这些参数全部提取出来。然后把 Headers 拷贝出来,发现 Fiddler 把 请求行、响应行、响应头都包括进来了,我们只需要中间的请求头部分。
因为 requests.get 方法里面的 headers 参数必须是字典对象,所以,先要写个函数把刚刚拷贝的字符串转换成字典对象。
def headers_to_dict(headers):
"""
将字符串
'''
Host: mp.weixin.qq.com
Connection: keep-alive
Cache-Control: max-age=
'''
转换成字典对象
{
"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Cache-Control":"max-age="
}
:param headers: str
:return: dict
"""
headers = headers.split("\\n")
d_headers = dict()
for h in headers:
if h:
k, v = h.split(":", 1)
d_headers[k] = v.strip()
return d_headers
最终 v0.1 版本出来了,不出意外的话,公众号历史文章数据就在 response.text 中。如果返回的内容非常短,而且title标签是<title>验证</title>,那么说明你的请求参数或者请求头有误,最有可能的一种请求就是 Headers 里面的 Cookie 字段过期,从手机微信端重新发起一次请求获取最新的请求参数和请求头试试。
# v0.1
def crawl():
url = "https://mp.weixin.qq.com/..." # 省略了
headers = """ # 省略了
Host: mp.weixin.qq.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
"""
headers = headers_to_dict(headers)
response = requests.get(url, headers=headers, verify=False)
print(response.text)
最后,我们顺带把响应结果另存为html文件,以便后面重复使用,分析里面的内容
with open("weixin_history.html", "w", encoding="utf-8") as f:
f.write(response.text)用浏览器打开 weixin_history.html 文件,查看该页面的源代码,搜索微信历史文章标题的关键字 "11月赠书"(就是我以往发的文章),你会发现,历史文章封装在叫 msgList 的数组中(实际上该数组包装在字典结构中),这是一个 Json 格式的数据,但是里面还有 html 转义字符需要处理
接下来我们就来写一个方法提取出历史文章数据,分三个步骤,首先用正则提取数据内容,然后 html 转义处理,最终得到一个列表对象,返回最近发布的10篇文章。
def extract_data(html_content):
"""
从html页面中提取历史文章数据
:param html_content 页面源代码
:return: 历史文章列表
"""
import re
import html
import json
rex = "msgList = '({.*?})'"
pattern = re.compile(pattern=rex, flags=re.S)
match = pattern.search(html_content)
if match:
data = match.group(1)
data = html.unescape(data)
data = json.loads(data)
articles = data.get("list")
for item in articles:
print(item)
return articles
最终提取出来的数据总共有10条,就是最近发表的10条数据,我们看看每条数据返回有哪些字段。
article = {'app_msg_ext_info':
{'title': '11月赠书,总共10本,附Python书单',
'copyright_stat': 11,
'is_multi': 1,
'content': '',
'author': '刘志军',
'subtype': 9,
'del_flag': 1,
'fileid': 502883895,
'content_url': 'http:\\\\/\\\\/mp.weixin.qq.com...',
''
'digest': '十一月份赠书福利如期而至,更多惊喜等着你',
'cover': 'http:\\\\/\\\\/mmbiz.qpic.cn\\\\...',
'multi_app_msg_item_list': [{'fileid': 861719336,
'content_url': 'http:\\\\/\\\\/mp.weixin.qq.com',
'content': '', 'copyright_stat': 11,
'cover': 'http:\\\\/\\\\/mmbiz.qpic.cn',
'del_flag': 1,
'digest': '多数情况下,人是种短视的动物',
'source_url': '',
'title': '罗胖60秒:诺贝尔奖设立时,为何会被骂?',
'author': '罗振宇'
}],
'source_url': 'https:\\\\/\\\\/github.com\\'
},
'comm_msg_info': {'datetime': 1511827200,
'status': 2,
'id': 1000000161,
'fakeid': '2393828411',
'content': '',
'type': 49}}
comm_msg_info.datetime,app_msg_ext_info中的字段信息就是第一篇文章的字段信息,分别对应:
- title:文章标题
- content_url:文章链接
- source_url:原文链接,有可能为空
- digest:摘要
- cover:封面图
- datetime:推送时间
后面几篇文章以列表的形式保存在 multi_app_msg_item_list 字段中。
到此,公众号文章的基本信息就抓到了,但也仅仅只是公众号的前10条推送。
资源来源于网络,纯属分享,不做商业用途,如若侵犯了您的权益和利益,请告知删除。
以上是关于欢度国庆⭐️共享爬虫之美⭐️基于 Python 实现微信公众号爬虫(Python无所不能爬)的主要内容,如果未能解决你的问题,请参考以下文章