PyTorch学习笔记 4. 定义神经网络
Posted 编程圈子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch学习笔记 4. 定义神经网络相关的知识,希望对你有一定的参考价值。
PyTorch学习笔记 4. 定义神经网络
一、 torch.nn 概述
1. 定义网络
torch.nn是Pytorch专门为神经网络设计的模块化接口,基于AutoGrad实现。nn.Module是其中最重要的一个类,可以看作是网络的封装,包含网络各层的定义和forward方法。调用 forward 方法,可以返回前向传播的结果。
定义网络时,就需要继承nn.Module,并实现它的forward方法。
- 网络中具有可学习参数的层放在构造函数
__init__中。 - 如果层(如ReLu激活函数)中有不可学习的参数,放不放在构造函数里都行。如果不放在
__init__里,则在forward方法里面可以用nn.functional来替代。 - forward方法必须重写,用来实现模型的功能、实现各个层之间的连接关系的核心。
下面是定义的一个网络示例:
class Net(nn.Module):
def __init__(self):
# 调用父类构造函数
super(Net, self).__init__()
# 建立了两个卷积层,第一层1 个通道输入, 6个输出通道, 5x5 卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
# 第一个层输出作为第二个层的输入
self.conv2 = nn.Conv2d(6, 16, 5)
#三个全连接层,y = Wx + b 这里没有做激活/非线性操作
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
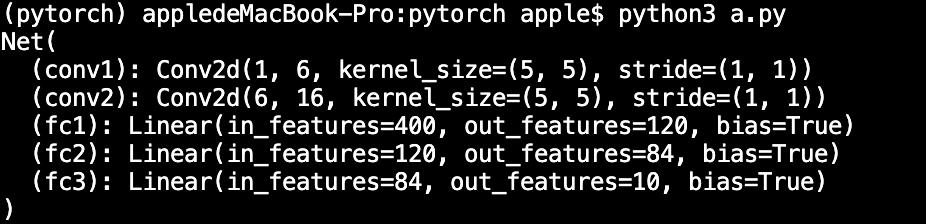
model=Net()
print(model)
运行结果:
在nn.Module的子类中定义了forward函数,backward不需要自己定义,函数会自动被实现。
forward 函数中可使用任何Variable 支持的函数,还可以使用 if、for循环、print、log 等Python语法 。
上面构造函数里定义的一系列层,其之间的连接关系并没有,而是在forward里实现层的连接关系。
2. 网络的属性
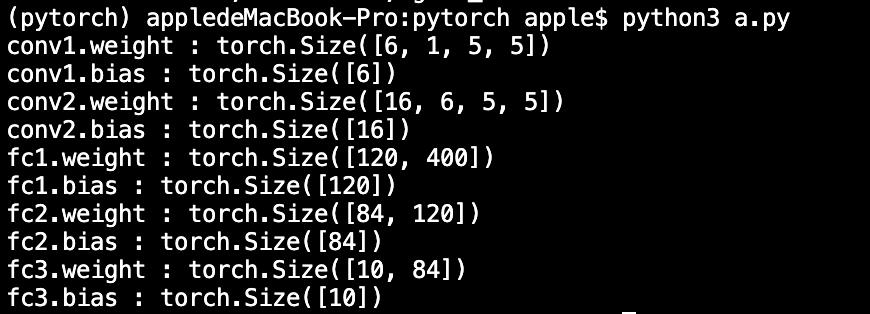
- net.parameters() 返回网络的可学习参数;
- net.named_parameters可同时返回可学习的参数及名称。
params = list(net.parameters())
print(len(params))
for name, parameters in net.named_parameters():
print(name, ':', parameters.size())
3. 输入tensor给网络
输入值使用Variable封装:
input = Variable(torch.randn(1,1,32,32))
out = net(input)
print(out)

4. 反向传播
# 梯度清零
net.zero_grad()
out.backward(torch.randn(1,10))
调用backward()函数之前都要将梯度清零。
如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加。
当硬件限制不能使用更大的bachsize时,使用多次计算较小的bachsize的梯度平均值来代替更方便,坏处就是每次都要清零梯度。
5. 损失函数
nn实现了大部分深度学习的损失函数,这里使用 nn.MSELoss。对于MSELoss,
- 如果 reduction = ‘None’,直接返回向量形式的 loss
- 如果 reduction ≠ ‘None’,那么 loss 返回的是标量
-
- 如果 reduction=‘mean’,返回 loss.mean(); 默认情况下, reduction=‘mean’
-
- 如果 reduction=‘sum’,返回 loss.sum();`py
二、torch.nn.Module类的几种实现
1. 通过Sequential来包装层
包装层,就是把几个层包装成一个大的层,下面是使用Sequential的一个示例:
import torch.nn as nn
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(3, 32, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2))
self.dense_block = nn.Sequential(
nn.Linear(32 * 3 * 3, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
# 在层之间的连接关系,前向传播
def forward(self, x):
conv_out = self.conv_block(x)
res = conv_out.view(conv_out.size(0), -1)
out = self.dense_block(res)
return out
model = MyNet()
print(model)
运行:

2. 使用OrderdDict有序字典包装层
import torch.nn as nn
from collections import OrderedDict
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.conv_block = nn.Sequential(
OrderedDict(
[
("conv1", nn.Conv2d(3, 32, 3, 1, 1)),
("relu1", nn.ReLU()),
("pool", nn.MaxPool2d(2))
]
))
self.dense_block = nn.Sequential(
OrderedDict([
("dense1", nn.Linear(32 * 3 * 3, 128)),
("relu2", nn.ReLU()),
("dense2", nn.Linear(128, 10))
])
)
def forward(self, x):
conv_out = self.conv_block(x)
res = conv_out.view(conv_out.size(0), -1)
out = self.dense_block(res)
return out
model = MyNet()
print(model)
另外可以使用块的add_module来添加层,示例:
self.conv_block=torch.nn.Sequential()
self.conv_block.add_module("conv1",torch.nn.Conv2d(3, 32, 3, 1, 1))
self.conv_block.add_module("relu1",torch.nn.ReLU())
self.conv_block.add_module("pool1",torch.nn.MaxPool2d(2))
三、 Module类的几个方法
1. children()
遍历器,查看每一次迭代的元素,迭代Sequential类型。
2. model.named_children()
迭代器,每次迭代返回的元组类型。
3. model.modules()
迭代器,整个模型的属性(主要是层),迭代时返回层对象。
4. model.named_modules()
迭代器,整个模型的属性(主要是层),迭代时返回元组类型。
以上是关于PyTorch学习笔记 4. 定义神经网络的主要内容,如果未能解决你的问题,请参考以下文章