R语言入门——多元回归交叉验证的实现
Posted 统计学小王子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言入门——多元回归交叉验证的实现相关的知识,希望对你有一定的参考价值。
引言
随着模型复杂度的提高和数据量的提升,预测精度也会提高,但是使用传统的方法评估模型的精度,模型的泛化能力也会降低。我们这时候就有必要使用划分数据集的方法去评估模型。基本思想是参与评估的数据不去拟合模型。本文以多元回归为例子,构建函数去实现交叉验证建立CV模型评估。
下面是本文使用的三个包,大家可以自行载入:
# 载入包
library(ggplot2)
library(data.table)
library(MASS)
1、主要函数编写
1.1 随机数据的产生
– n:产生数据的观测次数
– p:产生数据的维数
– Beta:回归模型的真实值
为了降低信噪比,模型的残差标准差设为0.5.
> getData <- function(n = 200, p = 3, Beta = rep(1, p)){
+ library(MASS)
+ x <- mvrnorm(n, rep(0, p), diag(rep(1, p)))
+ names(x) <- paste0('x', 1:p)
+ y <- x %*% Beta + rnorm(n, 0, 0.5)
+ Data <- data.frame(y = y, x)
+ Data
+ }
> head(getData())
y X1 X2 X3
1 -1.3952665 -0.7776920 -1.2173153 1.0370153
2 -0.3843078 0.1367314 0.7210690 -0.9921161
3 2.2212180 0.8984214 0.1888832 0.8709175
4 1.8005513 -0.2479999 1.1831627 0.9138255
5 -1.7861434 -0.8760386 -1.9289443 1.6050439
6 -3.4022036 -2.2106594 -1.3107755 -0.4465723
1.2 CV.lm的编写
– Data:模型数据
– k :交叉验证的折数(k = n是为留一交叉验证)
– p:每折的抽样占比,默认每折比例近似相同
– methed:cv和MCMC可选,默认CV
CV.lm <- function(data = Data, k = 5, p = rep(1, k)/k, method = 'CV'){
n <- nrow(data)
e <- n - sum(round(n*p))
ngroup <- round(n*p)
if(e != 0){
for(i in 1:e){
ngroup[i] <- ngroup[i] + 1
}
}
start <- c(1, cumsum(ngroup)[1:(k-1)]+1)
end <- cumsum(ngroup)
ind <- sample(1:n)
if(method != 'CV'){
testdata <- data[ind[start[1]:end[1]],]
traindata <- data[-ind[start[1]:end[1]],]
fit <- lm(y ~ ., data = traindata)
yhat <- predict(fit, newdata = testdata)
erro <- yhat - data$y[ind[start[1]:end[1]]]
RMSE <- sqrt((t(erro) %*% erro)/nrow(data))
out <- list(yhat = yhat, RMSE = RMSE)
return(out)
}
yhats <- c()
for(i in 1:k){
testdata <- data[ind[start[i]:end[i]],]
traindata <- data[-ind[start[i]:end[i]],]
fit <- lm(y ~ ., data = traindata)
yhat <- predict(fit, newdata = testdata)
yhats <- c(yhats, yhat)
}
erro <- yhats - data$y[ind]
RMSE <- sqrt((t(erro) %*% erro)/nrow(data))
out <- list(yhat = yhats, RMSE = RMSE)
return(out)
}
1.2 CV.lm的调用
> Data <- getData(n = 100, p = 20)
> CV.lm(Data, k = 5, method = 'CV')
$yhat
81 67 20 74 71 100 41 51 83 44 1 5 26
2.18654037 -0.01443100 9.87465172 -6.88415433 -4.84993135 -5.46583888 -6.24346588 -3.29852477 -0.91897172 5.83005552 -1.74781478 -9.20326282 -4.43044632
46 93 73 12 86 90 2 50 39 43 30 76 21
-2.52187250 -2.56797877 1.19273371 -8.09899265 0.12887602 4.43536269 -2.61761784 -0.26978052 -2.15083278 -7.51510079 2.79867447 -2.40063565 -0.19497446
79 49 25 45 16 85 89 3 58 65 32 61 84
-5.76782017 4.56694383 -0.21526687 3.25852907 -0.52974764 -3.83607700 1.62073269 3.08459944 0.02073593 2.62093830 -1.40076722 -5.52651415 -7.27654391
36 77 18 14 28 11 13 78 35 98 95 69 54
1.90159961 -1.33820465 -1.00851747 2.39342585 -1.44773031 -1.52923336 -7.20941753 -4.58400811 -0.33950637 -6.81580122 -3.43827376 1.83511295 0.49283565
82 42 59 10 19 15 4 33 91 62 60 22 38
-0.01923878 7.36222613 -0.48926252 -6.74970251 -9.11778698 1.94610032 1.74760592 -4.24623324 -1.76799507 1.18516389 1.79362303 -9.22521042 -8.64803652
34 87 68 72 37 6 63 80 31 53 88 70 56
1.96267748 -4.36196234 -2.64362333 -5.44288180 -4.34245648 0.25427637 7.74405120 3.41536736 9.13814499 -11.86642616 -7.39859153 8.01582381 -6.89951848
55 96 7 57 17 40 48 27 64 92 23 75 9
10.04581990 8.31775866 6.85081589 -10.29939349 0.75059299 -4.95233326 -1.36855339 2.56054428 6.77722209 1.09484657 -4.81534017 0.67397664 -7.86602131
24 8 94 29 99 52 47 66 97
-3.41131443 2.90677676 -7.04131687 -1.17112236 -2.90742471 -6.22888626 4.69440408 0.72042252 1.89888377
$RMSE
[,1]
[1,] 0.5477361
> CV.lm(Data, k = 100, method = 'CV')
$yhat
65 24 72 36 18 68 63 3 8 61 20 48 11
2.52588053 -3.47060450 -5.32799035 1.84975569 -1.12687832 -2.64406253 7.71981902 3.22563182 2.97051773 -5.33389902 10.18055762 -1.51795688 -1.69575435
89 67 78 58 79 5 51 9 34 75 83 86 37
1.69704665 -0.01853040 -4.66147804 0.09195376 -5.64092202 -9.04541722 -3.13346224 -7.82568027 2.10499678 0.71148817 -0.90057462 0.01139815 -4.03867105
17 45 35 32 50 73 77 46 4 74 26 31 40
0.88123507 3.14912166 -0.30819995 -1.35422218 -0.47778272 1.06719657 -1.37560765 -2.22359621 1.74974015 -7.09349240 -4.54148902 9.00315834 -4.93746637
1 21 47 42 28 62 91 52 57 12 22 70 6
-1.71513134 -0.08771302 4.54552617 7.15571019 -1.39776243 1.36692534 -1.88909668 -6.18803453 -10.21234077 -8.22405093 -9.23876931 8.14555067 0.34291775
10 30 15 80 99 85 23 16 53 71 38 44 54
-6.73316821 2.80866625 1.88918155 3.26064640 -3.06896221 -3.72892140 -4.84853389 -0.44968635 -11.53890858 -4.83509140 -9.12473157 5.84074956 0.48655993
93 97 39 82 2 84 92 76 60 41 69 88 90
-2.49499509 1.78350944 -2.07119866 -0.09541769 -2.61132764 -7.13839842 1.13286076 -2.22649789 1.70945033 -6.17799578 1.72007248 -7.30759854 4.40874681
95 14 59 100 33 66 43 98 25 55 7 19 81
-3.57752862 2.22975392 -0.63589766 -5.44952858 -4.26985257 0.72807131 -7.38922570 -6.83987480 -0.11549540 10.21944053 6.74082071 -9.27371592 1.87665457
87 64 96 13 29 94 56 27 49
-4.39576478 6.90841001 8.38828200 -7.20398759 -0.98490498 -7.13502356 -7.14203152 2.58218323 4.65594828
$RMSE
[,1]
[1,] 0.5246706
> CV.lm(Data, k = 2, p = c(0.3, 0.7), method = 'MCMC')
$yhat
18 26 4 65 73 23 93 61 49 52 32 96 35 24 70
-1.18704798 -2.22763527 -0.70294619 1.54361154 -1.90441413 -2.69264309 1.34857788 -2.01483135 0.72469515 -0.55287414 1.13532314 0.13860175 0.34771288 -0.32094229 2.42213708
40 55 13 74 57 28 86 54 9 77 51 53 90 5 21
-0.55299565 1.10809922 -0.12173624 1.73395684 -1.17323646 -4.69171818 1.73944592 -1.55977312 -2.86850571 0.50488980 0.57255653 2.22518454 -0.02745386 0.45510601 -3.04409607
46 94 81 62 72 63 25 97 29 8 89 7 80 31 12
3.65177053 -1.88996439 -1.49158575 0.45341147 1.00988180 -1.37892843 -1.02138495 6.12285936 0.14682676 1.89112537 -0.22454335 -1.08578317 0.05420828 -0.35956107 1.45192502
88 48 100 39 41 45 58 20 71 79 91 69 56 76 3
-0.32186855 0.77325767 3.04858813 -0.56988476 -0.58851572 0.59396908 1.12596000 -1.54215044 0.53622862 -1.68363330 -1.31871060 1.33894845 0.31806274 -0.06714099 3.25564750
30 68 43 92 60 78 42 95 75 10 2 19 44 82 66
3.63180068 -1.56899627 0.25288263 -0.90868528 0.01835371 -3.09540446 -1.00224356 1.30433837 1.83360141 0.06254247 -2.45426180 -0.40325555 -0.40294029 -0.90668144 -0.29552699
98 11 17 33 64 27 50 15 47 34 14 85 84 99 1
2.42805749 -1.26225061 -1.80221627 -2.32232043 -1.12199864 0.05185008 -0.44916037 0.48802865 -1.11261560 -0.50571384 -0.34688728 0.53972095 -0.59034839 -1.65673992 0.98014780
38 37 36 67 22 87 59 83 6 16
1.07202486 0.02004368 1.80763711 -1.26913808 0.67916018 -2.00694380 1.41128510 1.15813164 0.83946964 0.83548532
$RMSE
[,1]
[1,] 0.2736122
>
可以看出函数是可以使用的,因为每次抽样带有随机性,下面执行100次不同的CV。
2、数值模拟
2.1 CV模拟
N <- c(100, 300, 500, 1000)
K <- c(5, 10, 20, 50)
RMSEs <- data.table(n = c(), K = c(), RMSE = c())
for(j in 1:100){
for(n in N){
for(k in K){
Data <- getData(n = n, p = 20)
RMSE <- CV.lm(Data, k = k, method = 'CV')$RMSE
RMSEs <- rbind(RMSEs, data.table(n = n, k = k, RMSE = RMSE))
cat(j, '次', ',n = ', n, ',k = ', k, '\\n')
}
}
}
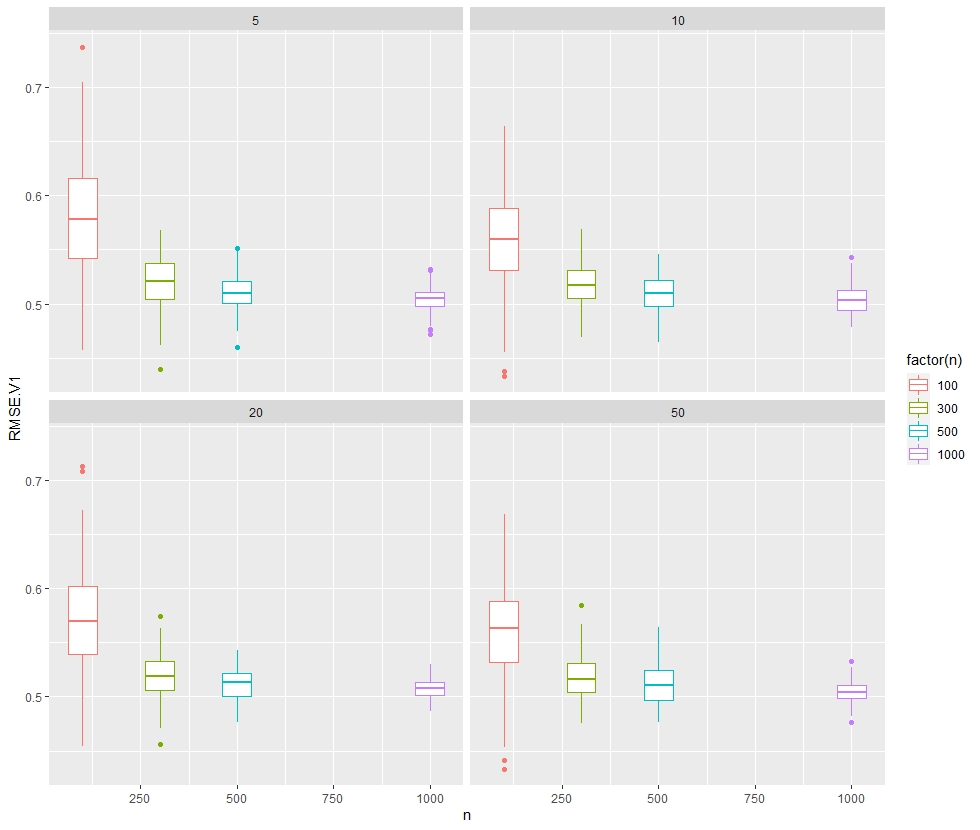
> RMSEs[,.(mean(RMSE.V1), sd(RMSE.V1)),by = c('n', 'k')]
n k RMSE_mean RMSE_sd
1: 100 5 0.5796997 0.055523027
2: 100 10 0.5579595 0.046627906
3: 100 20 0.5698858 0.047016860
4: 100 50 0.5613656 0.045983065
5: 300 5 0.5207754 0.023325919
6: 300 10 0.5188533 0.020100251
7: 300 20 0.5191463 0.022133704
8: 300 50 0.5187397 0.020079312
9: 500 5 0.5101782 0.016237246
10: 500 10 0.5100151 0.016728890
11: 500 20 0.5114958 0.016420630
12: 500 50 0.5108451 0.017669802
13: 1000 5 0.5050968 0.012085097
14: 1000 10 0.5032225 0.012533446
15: 1000 20 0.5079430 0.009645647
16: 1000 50 0.5044087 0.009994131
> p1 <- ggplot(data = RMSEs)
> p1 + geom_boxplot(aes(y = RMSE.V1, x = n
+ , group = n, col = factor(n))) +
+ facet_wrap(k ~ .)
>
2.2 MCMC模拟
P <- c(0.1, 0.2, 0.3