跟着开源项目学因果推断——whynot(十四)
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了跟着开源项目学因果推断——whynot(十四)相关的知识,希望对你有一定的参考价值。
文章目录

WhyNot是一个Python包,它提供了一个用于动态决策的实验沙箱,将因果推理和强化学习工具与具有挑战性的动态环境连接起来。
该软件包有助于开发、测试、基准测试和教学因果推理和顺序决策工具。
github: https://github.com/zykls/whynot
文档:https://whynot.readthedocs.io/en/latest/
下载:
pip install whynot
举一个例子 hiv_simulator.ipynb
%load_ext autoreload
%autoreload 2
import whynot.gym as gym
import numpy as np
import matplotlib.pyplot as plt
import torch
from scripts import utils
%matplotlib inline
# HIV环境
# Make the HIV environment and set random seed.
env = gym.make('HIV-v0')
np.random.seed(1)
env.seed(1)
torch.manual_seed(1)
# 策略
class NoTreatmentPolicy(utils.Policy):
"""The policy of always no treatment."""
def __init__(self):
super(NoTreatmentPolicy, self).__init__(env)
def sample_action(self, obs):
return 0
class MaxTreatmentPolicy(utils.Policy):
"""The policy of always applying both RT inhibitor and protease inhibitor."""
def __init__(self):
super(MaxTreatmentPolicy, self).__init__(env)
def sample_action(self, obs):
return 3
class RandomPolicy(utils.Policy):
"""The policy of picking a random action at each time step."""
def __init__(self):
super(RandomPolicy, self).__init__(env)
def sample_action(self, obs):
return np.random.randint(4)
# 模拟
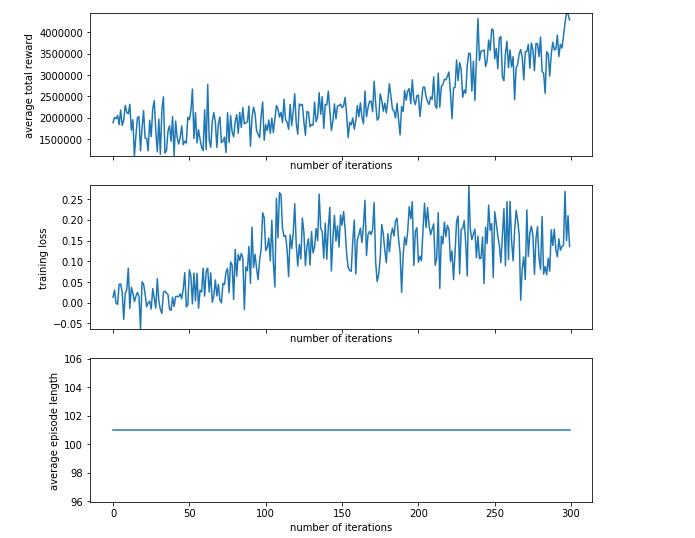
learned_policy = utils.run_training_loop(
env=env, n_iter=300, max_episode_length=100, batch_size=1000, learning_rate=1e-3)
几种策略,我们定义了一个基本的Policy类。每个策略都有一个sample_action函数,它接受一个观察并返回一个操作,一共四类:
- NNPolicy
一种1层前馈神经网络,以状态维为输入维,一个包含8个神经元的隐藏层(状态维度为6),以动作作为输出维度。我们使用批处理归一化和ReLU激活。 - 没有任何刺激策略
任何调整都不要,属于最基本的 - 刺激最大策略
任何调整都需要,属于过分敏感 - 随机的政策
采取随机行动而不考虑观察结果。
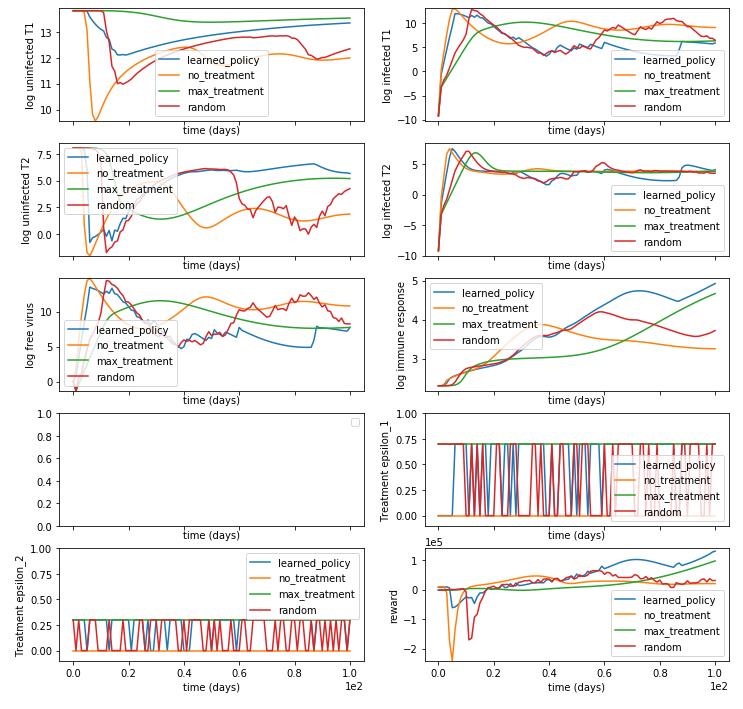
# 其他三个策略
policies = {
"learned_policy": learned_policy,
"no_treatment": NoTreatmentPolicy(),
"max_treatment": MaxTreatmentPolicy(),
"random": RandomPolicy(),
}
utils.plot_sample_trajectory(env, policies, 100, wn.hiv.State.variable_names())
以上是关于跟着开源项目学因果推断——whynot(十四)的主要内容,如果未能解决你的问题,请参考以下文章