带你学习不一样的Hbase|概述|核心原理
Posted 涤生手记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你学习不一样的Hbase|概述|核心原理相关的知识,希望对你有一定的参考价值。
Hbase是什么?学习东西的一手资料就是看官网,看hbase官网的背书:一个基于hadoop的分布式的,可扩展的,可以大量存储的数据库,主要应对大量数据的随机读写需求,实现海量数据的实时随机读写。
但是官网的表述往往是言简意赅,简洁客观性的陈述介绍。其实不利于很多初级学习者的学习和理解,或者不够的深入的和细节性的学习。技术是为了应用,技术的发展是为了解决已经存在问题。所以学一个技术框架,首先了解为什么需要它?它的出现是为了解决什么问题?以及它是如何解决的?把这个三个问题搞透了,也就对整个技术框架成竹在胸了,其他剩下就是深入的细节研究。
1.为什么需要Hbase?
1.1Hbase的前世
随着互联网的发展,企业收集的数据规模越来越大。所谓的大数据其实就是为了解决两个问题:海量的数据存储+海量的数据计算 。 面对海量的数据存储,单机已经不可能在实现了。Google在面对海量网页信息存储的时候,弄出了一个GFS(后来的分布式文件存储系统HDFS/Hadoop基于此实现)进行分布式文件存储。
但是很快Google又遇到了麻烦,随着数据规模的增大,Google的海量数据搜索,需要对数据进行建索引,那么数据在分布式多台服务器上存储时,如何维护这个巨大的数据索引?并且能保证它高度一致,可以低延迟随机读写,以及实现故障转移等?这个时候Google为了解决这个问题又搞出来一个BIgtable,Hbase的前世。
1.2 Bigtable是什么?
Bigtable是一个分布式的结构化数据存储系统,用来处理海量数据,注意官方介绍不是数据库。在Google发表的关于Bigtable的论文中这样介绍:Bigtable是一个稀疏的、分布式的、持久化存储的多维度排序的Map。
A Bigtable is a sparse, distributed, persistent multidimensional sorted map.Map这玩意大家都知道,就是一个Key-value键值对。设计的Bigtable的key是一个复合的值,包含行键rowkey ,列键column key 和时间戳timestamp,而值value是一个字节数组。如下所示,其他的几点就不展开介绍了。
(rowkey:string,column:string,timestatmp:int)---> byte[]而后来Hbase是基于Google的Bigtable开源而来,所以Hbase的核心应该是一个MAP,而不是传统的数据库的二维表结构,所以如果只看官网,很容易误导人,没能真正地理解hbase。只是这里Hbase 使用的 Map 的主键更加复杂,是一个复合键由 row key行键 、column key列族(一个列族里可以在使用时任意添加拓展列,百万列的级别) ,qualifier列(也称限定符),type和 timestamp构成。
1.3 Hbase是什么?
参照Bigtable的核心,Hbase定义也应该是一个稀疏的、分布式的、持久化存储的多维度排序的Map。
1.3.1分布式的
Hbase存储在分布式文件系统上,如HDFS/S3等。所以Hbase底层数据是分布式存储在不同服务器上的。这里HDFS可以理解成硬盘,Hbase基于HDFS存储,不直接操作底层linux文件系统。
1.3.2 持久化的
Hbase的数据在创建或访问它的程序完成后“持久化”存储在机器上
1.3.3排序的
与大多数Map的实现不同,在 Hbase/BigTable 中,k-V键值对K严格按照字母顺序保存,即字典排序的,有序存放(也是其支持高效查询的原因之一),注意V不排序。也就是说,k“aaaaa”的行应该紧挨着k“aaaab”的行,并且离键“zzzzz”的行很远。
{
“1”:“x”,
“aaaaa”:“y”,
“aaaab”:“世界”,
“xyz”:“你好”,
“zzzzz”:“woot”
}1.3.4 稀疏的
给定的行在每个列族中可以有任意数量的列,或者根本没有列不.同行列数可以不同,不需要用null值填充,不占空间。
另一种稀疏类型是基于行的间隙,这仅意味着键之间可能存在间隙,键不用连续。
1.3.5多维
多维如果从Map的角度看就是一个多维Map,从Hbase数据库的角度看多维一个是指基于列族的存储。另一个多维是指时间戳,所有数据都使用整数时间戳(自纪元以来的秒数)或您选择的另一个整数进行版本控制。具体后面在深入介绍。
如下,才是Hbase的底层真面目:1张表,有三个列族,每个列族的里列数不固定,时间戳也不固定。Hbase底层是复合的(多维的)Map键值对格式存储。

为什么官网又把Hbase叫做database呢?因为Hbase使用了大量数据库的概念:表,行,列等,数据以表的形式组织的,所以从数据库的角度看也是没有问题的。但是坑就坑在这,把Hhbae称呼成database,很不利于真正了解Hbase基本工作原理。
Hbase底层依赖于HDFS进行文件存储,HDFS不支持随机读写,那么Hbase如何实现的可以支持随机读写呢?以及为何可以实现低延迟,近实时的数据读写操作呢?
2.先见森林,了解Hbase架构
2.1 hbase架构初见
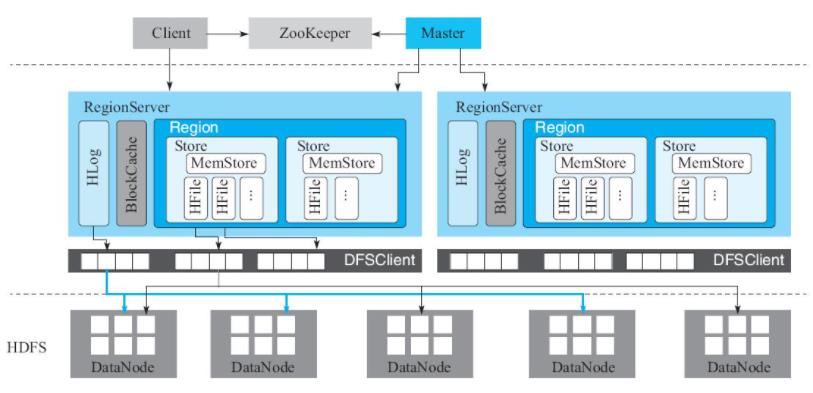
如上图所以,先了解下Hbase集群架构
1.Master/Slave模式,一个Hbase集群由一个活跃的Master节点(HA,可以多个备份Master)管理各种工作,以及多个RegionServer(负责实际干活)角色组成。
2.RegionServer是Hbase核心的模块,用来响应用户的IO请求。如上图RegionServer组成:WAL(Hlog),BlockCache,N个region组成(N>=0)。
3.Zookeeper主要是保证Master节点的HA,管理Hbase核心元数据(hbase:meta),提供分布式锁,保证对分布式存储的数据表进行分布式操作时状态的一致性。
4.HDFS是Hbase底层实际存储数据的文件系统,可以理解成Hbase存储数据的硬盘,Hbase主要用它的分布式存储和数据高可靠性。
2.2 Hbase集群角色剖析
2.2.1核心的RegionServer

如上图尖叫提示:
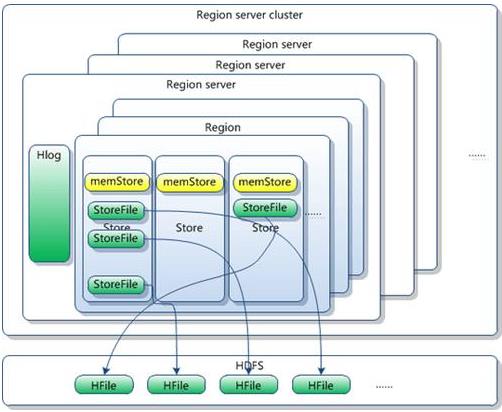
- 1个RegionServer=1个WAL(HLOG)+1个BlockCache+N个Region(N>=0)
- 1个Region=N 个Store(N>=1)
- 一个Store=1个MemStore+N个HStoreFile(也叫HFile)(n>=1)
1.Hlog(WAL预写日志)
WAL(write ahead log),预写日志。这个其实是Hbase的一个安全机制,为了保障数据的高可靠性。Hbase在的客户端在操作数据时,不是直接操作底层数据(Hfile),而是先写入缓存(内存),为了防止缓存数据丢失,所以在写入缓存之前先写入Hlog(WAL,是落盘日志,一个滚动更新日志),这样万一缓存断电丢失等可以从HLOG中恢复,有点类似mysql的binlog日志;
2.BlockCache(非主要)
这个主要是Hbase的读缓存,缓存是block块,注意这个block块不是HDFS的block,而是Hbase的block,默认值64k。主要作用是从磁盘读取数据后缓存到内存里,防止后续再次读取这样就不需要访问磁盘了,对于热点数据有利于提高请求性能,类似于HDFS的块读取缓存机制。
3.Region及其内部剖析
Region是一个表的“水平分片”,即一个表一部分。简单理解举个例子:一个表10亿行,2个列族,大概平均每行10万列左右,那么如何存储呢,一个节点肯定存储不了。那么这时候就给表按行切分存储,比如rowkey1-10000行为一个Region,存储在某个节点上,其他依次类推。
那么表的Region如何切分呢?当表的大小超过某个阈值时就会切分成两个(默认10GB),然后由Master节点根据负载均衡原则分配到不同的RegionServer(RS)上存储。所以一个生产上的RS会同时管理多个表的多个Region。所以Region是Hbase中表的分布式存储单元,但是注意其实Region只是一个逻辑划分的概念,实际底层存储的Store。那么为什么表切分后不直接叫Store呢?因为表是按排序后的rowkey范围切分的,要保证每个切分都是唯一的单元。而Store其实存储的是列族,Store个数等于列族个数。每个表会不止一个列族,且每个表的列族个数不确定,没法唯一标识这个表的切片,所以加了一个逻辑层叫Region(里面有一个或多个Store组成)
一个Region由具体有多少个Store组成呢?1个Region的Store个数的取决于这个Region对应表的列族个数,比如这个表只有1个列族,那么这个表对应的所有的Region都只有一个Store,同理表有N个列族,表单个Region就有N个Store。
一个Store=1个MemStore+N个HStoreFile(也叫HFile)(n>=1) 。MemStore其实是一个写缓存,客户端写数据时,先写入MemStore内存中,其实就是一个环形缓冲区,当其写入的数据超过指定的阈值(比如写满默认128Mb或者某个设置的百分比)时,就会Flush到HDFS上成一个Hfile文件。因为缓冲区不大,所以写数据时会有大量的HFile产生,
当Hfile的文件个数超过某个设置的阈值后就会进行Compact合并(大合并和小合并),合并成一个或多个大文件。当某个Region下面的所有文件之和超过设定的Region大小时,这个Region又会分裂成两个。
2.2Hbase的性能
2.2.1优势
1.存储容量大,TB,甚至PB的数据规模。我们公司使用的Hbase数据规模在1PB规模,千亿行,甚至万亿行的规模。
2.拓展性强,分布式部署,拓展。
3.高性能,低延迟,
4.多版本,支持数据多版本,稀疏性存储,节省空间
2.2.2缺点
1.不支持复杂的聚合运算,后者需要借助第三方工具,如Phoenix等。
2.不支持去全局跨行事务等,没有实现二级索引等。
以上是关于带你学习不一样的Hbase|概述|核心原理的主要内容,如果未能解决你的问题,请参考以下文章