Linux 磁盘管理详解--企业实战篇
Posted 涤生手记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux 磁盘管理详解--企业实战篇相关的知识,希望对你有一定的参考价值。

写在前面:
无论是windows 系统还是Linux 系统中,所有的文件最终都是存储在硬盘上的,都是在用文件系统管理,要想彻底搞清楚文件系统的管理机制,对磁盘的了解是必不可少的。
一、磁盘的认识
磁盘的分类
如果从存储数据的介质上来区分,硬盘可分为机械硬盘(Hard Disk Drive, HDD)和固态硬盘(Solid State Disk, SSD),机械硬盘采用磁性碟片来存储数据,而固态硬盘通过闪存颗粒来存储数据。
机械硬盘(HDD)
机械硬盘(HDD)是传统硬盘,为电脑主要的存储媒介之一。由一个或者多个铝制或者玻璃制成的磁性碟片,磁头,转轴,控制电机,磁头控制器,数据转换器,接口和缓存等几个部分组成。工作时,磁头悬浮在高速旋转的碟片上进行读写数据。机械硬盘是集精密机械、微电子电路、电磁转换为一体的电脑存储设备。
机械硬盘的内部核心图:

固态硬盘(SSD)
固态硬盘和传统的机械硬盘最大的区别就是不再采用盘片进行数据存储,而采用存储芯片进行数据存储。固态硬盘的存储芯片主要分为两种:一种是采用闪存作为存储介质的;另一种是采用DRAM作为存储介质的。目前使用较多的主要是采用闪存作为存储介质的固态硬盘。
固态硬盘内部核心图:

机械硬盘与SSD固态对比首先差距最大的就是性能,也就是读写速度的差距。
一般机械硬盘的都区委读取速度为150MB/s左右,而SATA SSD的读取速度能够达到600MB/s,NVMe M.2 SSD最高甚至可以达到3500MB/s以上。
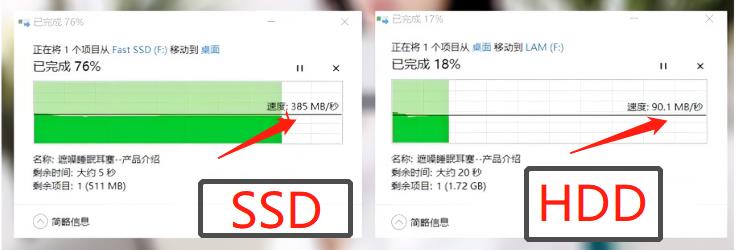
小记:生产环境下,在选用磁盘的类型上,一般都会有一个折中的考虑,如果存储数据量不是很大,偏重于计算型的场景,可以优先考虑选用SSD的磁盘,能很大的提升计算性能,反之,如果是大数据的存储场景,需要的存储就会很多,低价格的HDD盘就会节省很多成本,性能自然也就会有降低。
二、磁盘的使用
磁盘的使用,也即是磁盘的管理,在整个系统中的使用中是起到很核心的作用的,磁盘管理好坏直接关系到整个系统的性能状况。
2.磁盘分区
1.1分区的作用:
- 分区是将一个硬盘驱动器分成若干个逻辑驱动器,分区是把硬盘连续的区块当做一个独立的磁硬使用。
- 分区表是一个硬盘分区的索引,分区的信息都会写进分区表
- 多个分区可以防止数据的丢失,如果系统只有一个分区,那么这个分区损坏,用户将会丢失所的有数据,如果将用户数据和系统数据分开,其中数据盘的数据激增到极限,也不会影响系统的正常运行。
- 对磁盘根据文件大小的平均值进行不同区块大小来格式化分区,比如有很多2K的文件,而硬盘分区区块大小为6K,那么每存储一个文件将会浪费4K空间。合理的分区可以很大提高磁盘的使用率。
2.2分区工具一【fdisk】
fdisk是Linux下常用的磁盘分区工具。受mbr分区表的限制,fdisk工具只能给小于2TB的磁盘划分分区。如果使用fdisk对大于2TB的磁盘进行分区,虽然可以分区,但其仅识别2TB的空间,所以磁盘容量若超过2TB,就要使用parted分区工具(后面会讲)进行分区。
【语法格式】
fdisk [必要参数][选择参数]
- -l 列出素所有分区表
- -u 与 -l 搭配使用,显示分区数目
操作菜单说明:
- m :显示菜单和帮助信息
- a :活动分区标记/引导分区
- d :删除分区
- l :显示分区类型
- n :新建分区
- p :显示分区信息
- q :退出不保存
- t :设置分区号
- v :进行分区检查
- w :保存修改
- x :扩展应用,高级功能
分区操作示例:
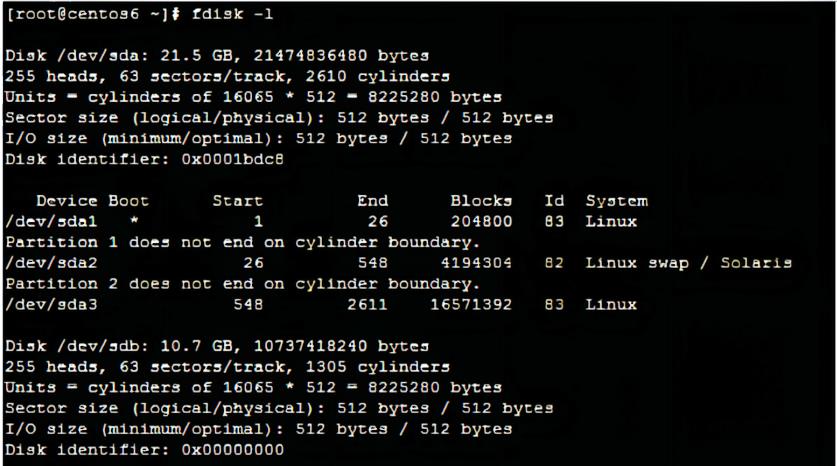
1.使用fdisk -l可以查看新的硬盘sdb
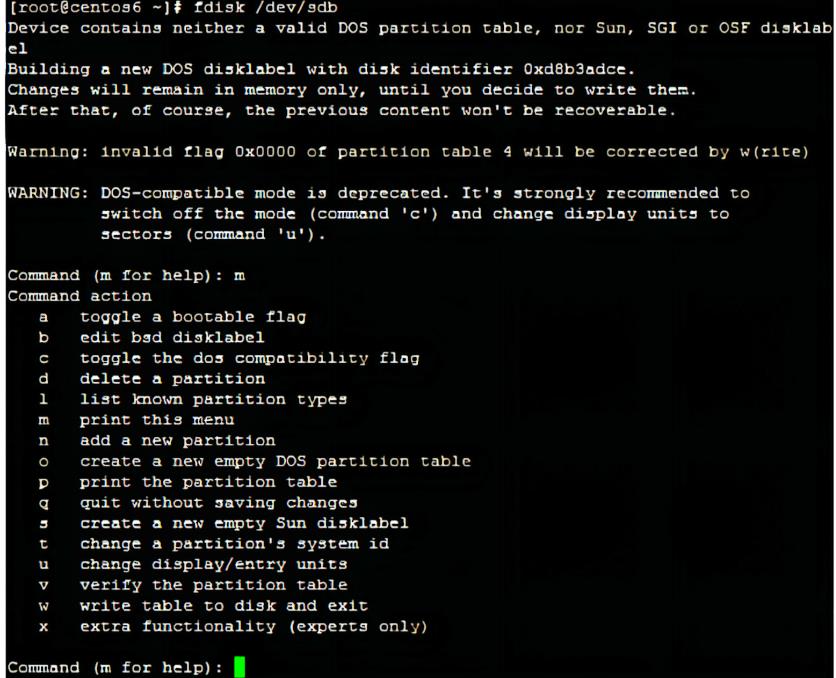
2.使用fdisk /dev/sdb命令对新磁盘进行分区,输入m查看可以使用的指令
3.创建第一个分区:/dev/sdb1,大小为2GB。
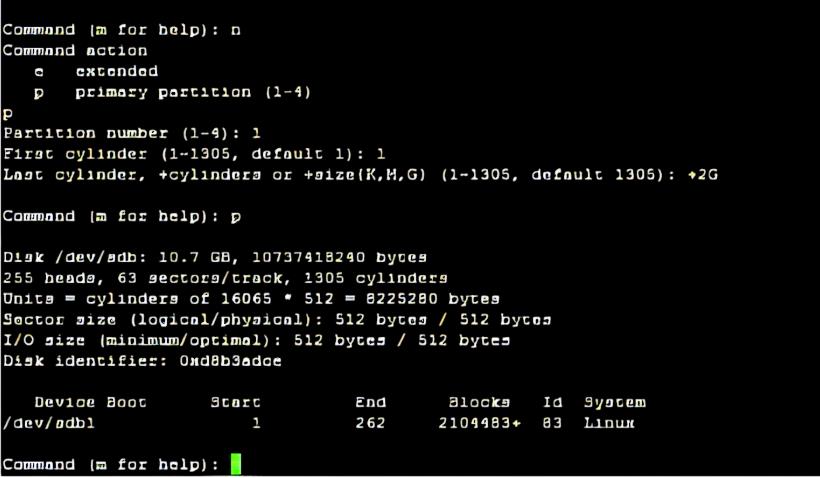
n 新建分区
p 选择主分区(扩展分区e+主分区p<=4)< span>
1 分区号(1,2,3,4)
起始柱面:1
结束柱面:+2G
p 查看分区信息
4.创建一个扩展分区:/dev/sdb2
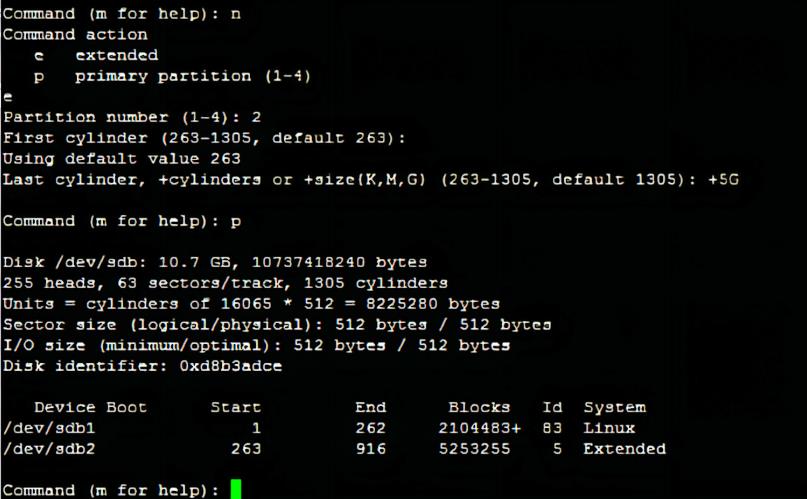
n 新建分区
这里有了一个扩展分区,所以可以选择在扩展分区里划分逻辑分区l,或者继续新建主分区p。
l 在扩展分区里划分逻辑分区(默认从分区号5开始)
起始柱面:回车(因为是第一个逻辑分区,所以默认从扩展分区的起始柱面开始)
结束柱面:+2G(不能超过该扩展分区的结束柱面)
p 查看分区信息
5.在扩展分区中创建逻辑分区:/dev/sdb5
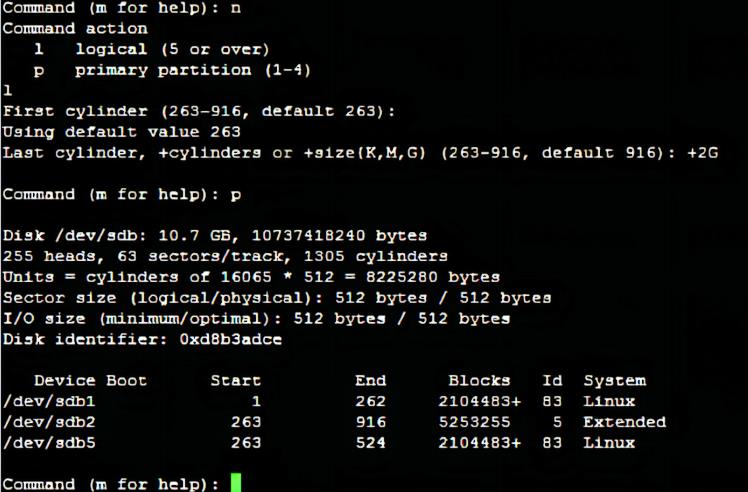
n 新建分区
这里有了一个扩展分区,所以可以选择在扩展分区里划分逻辑分区l,或者继续新建主分区p。
l 在扩展分区里划分逻辑分区(默认从分区号5开始)
起始柱面:回车(因为是第一个逻辑分区,所以默认从扩展分区的起始柱面开始)
结束柱面:+2G(不能超过该扩展分区的结束柱面
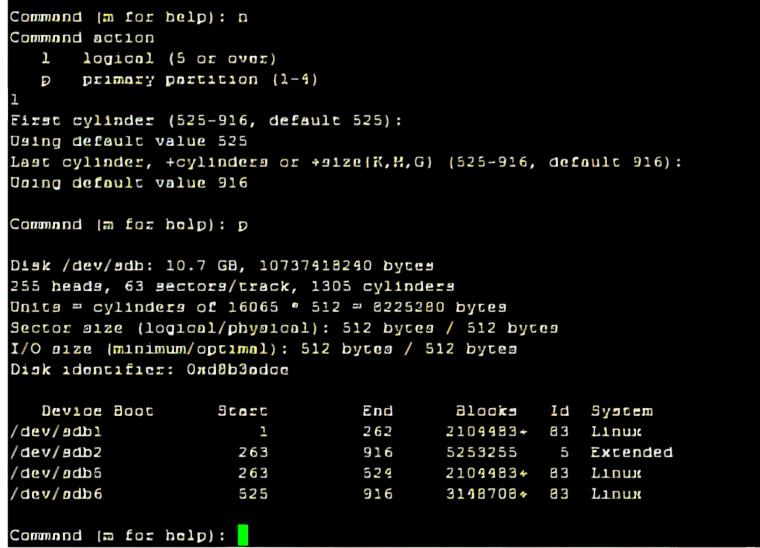
6.创建第二个逻辑分区:/dev/sdb6
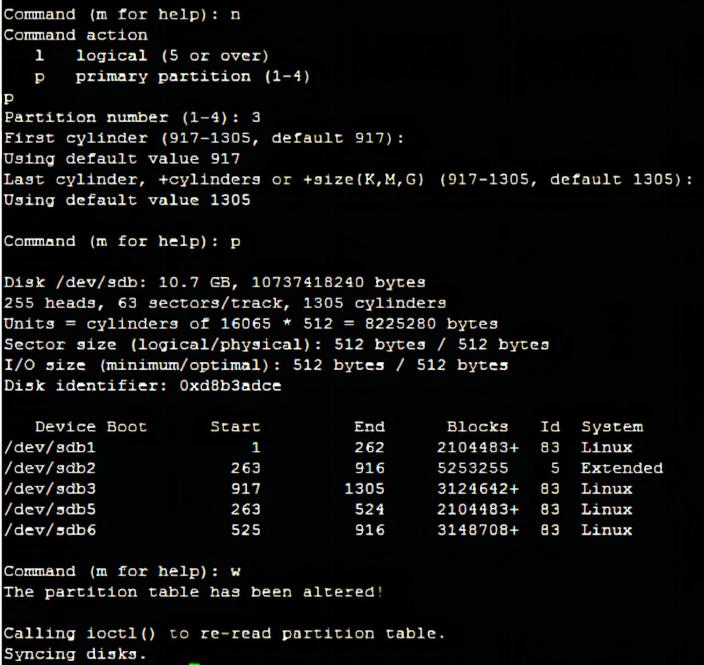
7.剩下磁盘空间再创建一个主分区(8G-10G),结尾出使用【w】会保存所有的操作【q】会直接退出不保存此次磁盘的分区操作。
2.3 分区工具二【Parted】
1 概要说明
parted用于对磁盘(或RAID磁盘)进行分区及管理,与fdisk分区工具相比,支持2TB以上的磁盘分区,并且允许调整分区的大小。
2 GNU手册说明
parted是一个用于硬盘分区或调整分区大小的工具。使用它你可以创建、清除、调整、移动和复制ext2、ext3、linux-swap、FAT、FAT32和reiserfs分区;也能创建、调整和移动苹果系统的HFS分区;还能检测jfs、ntfs、ufs和xfs分区。该工具常用于为新安装的操作系统创建空间,重新分配硬盘使用情况,在将数据拷贝到新硬盘的时候也常常使用。
【语法格式】
用法:parted [选项] [设备] [指令]
将带有“参数”的命令应用于“设备”。如果没有给出“命令”,则以交互模式运行。
参数选项:
- -h, 显示此求助信息
- -l, 列出系统系统中所有的磁盘设备,和fdisk -l命令的作用差不多。
- -m, 进入交互模式,如果后面不加设备则对第一个磁盘进行操作
- -s, 脚本模式
- -v, 显示版本
- 设备:磁盘设备名称,如/dev/sda
- 指令:如果没有给出“指令”,则parted将进入交互模式运行。
- align-check 检查分区N的类型(min|opt)是否对齐
- help 打印通用求助信息,或关于[指令]的帮助信息
- mklabel 创建新的磁盘标签 (分区表)
- mkpart 创建一个分区
- name 给指定的分区命名
- print 打印分区表,或者分区
- quit 退出程序
- rescue 修复丢失的分区
- resizepart 调整分区大小
- rm 删除分区
- select 选择要编辑的设备,默认只对指定的设备操作,这里可以改变指定的设备
- disk_set 更改选定设备上的标志
- disk_toggle 切换选定设备上的标志状态
- set 更改分区的标记
- toggle 设置或取消分区的标记
- unit 设置默认的单位
- version 显示版本信息
交互式操作示例:分区-磁盘 /dev/sdb

后续操作:
格式化分区:mkfs.xfs -f /dev/sdb1
创建挂载点:mkdir /data
挂载磁盘:mount -o noatime,nodiratime /dev/sdb1 /data
后续操作:
mklabel gpt
yes
mklabel primary 0 500
p
mklabel logical 501 1000
p
quit
非交互式操作示例:分区-格式化-挂载 磁盘:/dev/sdi
[root@test ~]# parted -s /dev/sdi mklabel gpt ##对磁盘/dev/sdi进行分区
[root@test ~]# parted -s /dev/sdi mkpart primary 1 100% ##指定分区类型和容量大小
[root@test ~]# mkfs.xfs -f /dev/sdi1 ##格式化磁盘
meta-data=/dev/sdi1 isize=256 agcount=32, agsize=61042880 blks
= sectsz=4096 attr=2, projid32bit=0
data = bsize=4096 blocks=1953372160, imaxpct=5
= sunit=64 swidth=64 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=521728, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@test ~]# mkdir /hadoop11 ##创建挂载点
[root@test ~]# mount -o noatime,nodiratime /dev/sdi1 /hadoop11 ##挂载盘
[root@test ~]# df -h ##查看挂载是否成功
/dev/sdi1 7.3T 34M 7.3T 1% /hadoop11磁盘的开机自动挂载:
一般磁盘 分区-->格式化-->挂载 之后都会配置一个开机自动挂载,否则下册机器自动重启之后,磁盘不会自动挂载,也就无法正常使用,所以需要将分区信息写到/etc/fstab文件中,实现开机自动挂载。
操作方式:
1.通过【blkid】命令查看磁盘的uuid,也是磁盘的唯一标识:
[root@test ~]# blkid
/dev/sdi1: UUID="5a120f30-cfbe-4b70-b837-949f2054e654" TYPE="xfs"2.打开/etc/fstab文件,追加需要挂载的磁盘分区信息
注意:/etc/fstab文件中已有内容不要动,将内容追加即可。
vim /etc/fstab
UUID=5a120f30-cfbe-4b70-b837-949f2054e654 /hadoop11 xfs noatime,nodiratime 0 0内容说明:
第1列是设备名或者卷标
第2列是挂载点(也就是挂载目录)
第3列是所要挂载设备的文件系统或者文件系统类型
第4列是挂载选项,通常使用defaults就可以
第5列设置是否使用dump备份,置0为不备份,置1,2为备份,但2的备份重要性比1小
第6列设置是否开机的时候使用fsck检验所挂载的磁盘,置0为不检验,置1,2为检验,但置2盘比置1的盘晚检验。【线上一般都是设置为0】
测试配置是否生效:
可以手动先umount卸载已挂载好的磁盘,配置好上述文件之后,执行mount -a 执行命令 df -h 查看磁盘又重新挂载上去,则说明配置生效。
小记:
因为传统的MBR分区表格式,仅支持最大四个主分区,而且不可以格式化2TB以上的磁盘,因此,生产环境像大数据存储场景下,基本都是大磁盘比较多,所以parted工具的使用也会偏多一些,当然还有很多非大数据场景或者单盘容量本生就不大于2TB的,建议使用fdisk工作操作。
分享一个自动化分区的脚本:【注意:需要根据线上环境微调部分参数】
#!/bin/bash
df -h|grep '/hadoop' && exit 1
yum install parted kmod-xfs xfsprogs -y
disk_num=`fdisk -l | grep 8001 | awk '{print $2}'| awk -F ':' '{print $1}'`
NUM=0
for i in $disk_num
do
parted -s $i mklabel gpt
parted -s $i mkpart primary 1 100%
mkfs.xfs -f ${i}1
if [ $NUM -eq 0 ];then
TMP=""
else
TMP=$NUM
fi
mkdir /hadoop${TMP}
mount -o noatime,nodiratime ${i}1 /hadoop${TMP}
uuid=`blkid ${i}1 |awk '{print $2}' |sed s#\\"##g`
echo "$uuid /hadoop${TMP} xfs noatime,nodiratime 0 0">>/etc/fstab
((NUM++))
done三、磁盘的运维
1.查看磁盘使用情况 【df -h】
[root@10-90-49-176-jhdxyjd ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 530G 1.3G 502G 1% /
tmpfs 126G 0 126G 0% /dev/shm
/dev/sdi1 7.3T 34M 7.3T 1% /hadoop11参数说明:
第1列是设备名
第2列是磁盘总容量大小
第3列是已使用容量大小
第4列是剩余容量大小
第5列容量已使用百分比
第6列挂载点目录名称
2.查看磁盘负载状况 推荐命令【top】【iostat】
[root@test ~]# top
top - 14:58:05 up 15 days, 21:46, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 1733 total, 1 running, 1731 sleeping, 1 stopped, 0 zombie
Cpu(s): 0.0%us, 0.1%sy, 0.0%ni, 99.9%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 264143368k total, 3548440k used, 260594928k free, 88548k buffers
Swap: 0k total, 0k used, 0k free, 592176k cached
参数说明:
Cpu(s):
0.0%us :用户空间占用CPU百分比
0.1%sy :内核空间占用CPU百分比
0.0%ni :用户进程空间内改变过优先级的进程占用CPU百分比
99.9%id : 空闲CPU百分比
0.0%wa :等待输入输出的CPU时间百分比,的百分比可以大致的体现出当前的磁盘io请求是否频繁。如果 wa的数量比较大,说明等待输入输出的的io比较多
0.0%hi
0.0%si
0.0%st
小记:
生产环境中对磁盘的运维工作基本上以下两类:
1.磁盘容量使用过多,需要清理
此时就需要结合du命令来查看本盘下具体哪个目录使用量过多,如果是可清理的文件就需要清理掉,如果不能清理,就需要对文件压缩和磁盘的扩容了。
2.磁盘的读写出错
此时最直接的表现就是磁盘不能读写,报错也很明显
ls: cannot open directory .: Input/output error此时就需要定位问题,修复磁盘了。

以上是关于Linux 磁盘管理详解--企业实战篇的主要内容,如果未能解决你的问题,请参考以下文章