Elasticsearch 运行时类型 Runtime fields 深入详解
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 运行时类型 Runtime fields 深入详解相关的知识,希望对你有一定的参考价值。
1、实战问题
实战业务中,遇到数据导入后,但发现缺少部分必要字段,一般怎么解决?
比如:emotion 代表情感值,取值范围为:0-1000。
其中:300-700 代表中性;0-300 代表负面;700-1000 代表正面。
但实际业务中,我们需要:中性:0;负面:-1;正面:1。
如何实现呢?
这时,可能想到的解决方案:
方案一:重新创建索引时添加字段,清除已有数据再重新导入数据。
方案二:重新创建索引时添加字段,原索引通过 reindex 写入到新索引。
方案三:提前指定数据预处理,结合管道 ingest 重新导入或批量更新 update_by_query 实现。
方案四:保留原索引不动,通过script 脚本实现。
方案一、二类似,新加字段导入数据即可。
方案三、方案四 我们模拟实现一把。
2、方案三、四实现一把
2.1 方案三 Ingest 预处理实现
DELETE news_00001
PUT news_00001
{
"mappings": {
"properties": {
"emotion": {
"type": "integer"
}
}
}
}
POST news_00001/_bulk
{"index":{"_id":1}}
{"emotion":558}
{"index":{"_id":2}}
{"emotion":125}
{"index":{"_id":3}}
{"emotion":900}
{"index":{"_id":4}}
{"emotion":600}
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"script": {
"description": "Set emotion flag param",
"lang": "painless",
"source": """
if (ctx['emotion'] < 300 && ctx['emotion'] > 0)
ctx['emotion_flag'] = -1;
if (ctx['emotion'] >= 300 && ctx['emotion'] <= 700)
ctx['emotion_flag'] = 0;
if (ctx['emotion'] > 700 && ctx['emotion'] < 1000)
ctx['emotion_flag'] = 1;
"""
}
}
]
}POST news_00001/_update_by_query?pipeline=my-pipeline
{
"query": {
"match_all": {}
}
}方案三的核心:定义了预处理管道:my-pipeline,管道里做了逻辑判定,对于emotion 不同的取值区间,设置 emotion_flag 不同的结果值。
该方案必须提前创建管道,可以通过写入时指定缺省管道 default_pipeline 或者结合批量更新实现。
实际是两种细分实现方式:
方式一:udpate_by_query 批量更新。而更新索引尤其全量更新索引是有很大的成本开销的。
方式二:写入阶段指定预处理管道,每写入一条数据预处理一次。
2.2 方案四 script 脚本实现
POST news_00001/_search
{
"query": {
"match_all": {}
},
"script_fields": {
"emotion_flag": {
"script": {
"lang": "painless",
"source": "if (doc['emotion'].value < 300 && doc['emotion'].value>0) return -1; if (doc['emotion'].value >= 300 && doc['emotion'].value<=700) return 0; if (doc['emotion'].value > 700 && doc['emotion'].value<=1000) return 1;"
}
}
}
}方案四的核心:通过 script_field 脚本实现。
该方案仅是通过检索获取了结果值,该值不能用于别的用途,比如:聚合。
还要注意的是:script_field 脚本处理字段会有性能问题。
两种方案各有利弊,这时候我们会进一步思考:
能不能不改 Mapping、不重新导入数据,就能得到我们想要的数据呢?
早期版本不可以,7.11 版本之后的版本有了新的解决方案——Runtime fields 运行时字段。
3、Runtime fields 产生背景
Runtime fields 运行时字段是旧的脚本字段 script field 的 Plus 版本,引入了一个有趣的概念,称为“读取建模”(Schema on read)。
有 Schema on read 自然会想到 Schema on write(写时建模),传统的非 runtime field 类型 都是写时建模的,而 Schema on read 则是另辟蹊径、读时建模。
这样,运行时字段不仅可以在索引前定义映射,还可以在查询时动态定义映射,并且几乎具有常规字段的所有优点。
Runtime fields在索引映射或查询中一旦定义,就可以立即用于搜索请求、聚合、筛选和排序。
4、Runtime fields 解决文章开头问题
4.1 Runtime fields 实战求解
PUT news_00001/_mapping
{
"runtime": {
"emotion_flag_new": {
"type": "keyword",
"script": {
"source": "if (doc['emotion'].value > 0 && doc['emotion'].value < 300) emit('-1'); if (doc['emotion'].value >= 300 && doc['emotion'].value<=700) emit('0'); if (doc['emotion'].value > 700 && doc['emotion'].value<=1000) emit('1');"
}
}
}
}
GET news_00001/_search
{
"fields" : ["*"]
}4.2 Runtime fields 核心语法解读
第一:PUT news_00001/_mapping 是在已有 Mapping 的基础上 更新 Mapping。
这是更新 Mapping 的方式。实际上,创建索引的同时,指定 runtime field 原理一致。实现如下:
PUT news_00002
{
"mappings": {
"runtime": {
"emotion_flag_new": {
"type": "keyword",
"script": {
"source": "if (doc['emotion'].value > 0 && doc['emotion'].value < 300) emit('-1'); if (doc['emotion'].value >= 300 && doc['emotion'].value<=700) emit('0'); if (doc['emotion'].value > 700 && doc['emotion'].value<=1000) emit('1');"
}
}
},
"properties": {
"emotion": {
"type": "integer"
}
}
}
}第二:更新的什么呢?
加了字段,确切的说,加了:runtime 类型的字段,字段名称为:emotion_flag_new,字段类型为:keyword,字段数值是用脚本 script 实现的。
脚本实现的什么呢?
当 emotion 介于 0 到 300 之间时,emotion_flag_new 设置为 -1 。
当 emotion 介于 300 到 700 之间时,emotion_flag_new 设置为 0。
当 emotion 介于 700 到 1000 之间时,emotion_flag_new 设置为 1。
第三:如何实现检索呢?
我们尝试一下传统的检索,看一下结果。
我们先看一下 Mapping:
{
"news_00001" : {
"mappings" : {
"runtime" : {
"emotion_flag_new" : {
"type" : "keyword",
"script" : {
"source" : "if (doc['emotion'].value > 0 && doc['emotion'].value < 300) emit('-1'); if (doc['emotion'].value >= 300 && doc['emotion'].value<=700) emit('0'); if (doc['emotion'].value > 700 && doc['emotion'].value<=1000) emit('1');",
"lang" : "painless"
}
}
},
"properties" : {
"emotion" : {
"type" : "integer"
}
}
}
}
}多了一个 runtime 类型的字段:emotion_flag_new。
执行:
GET news_00001/_search返回结果如下:

执行:
GET news_00001/_search
{
"query": {
"match": {
"emotion_flag_new": "-1"
}
}
}返回结果如下:
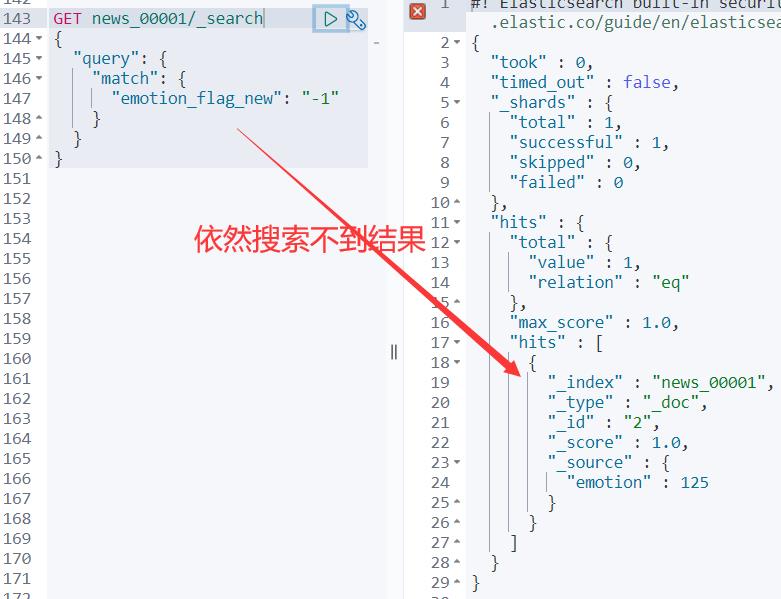
执行:
GET news_00001/_search
{
"fields" : ["*"],
"query": {
"match": {
"emotion_flag_new": "-1"
}
}
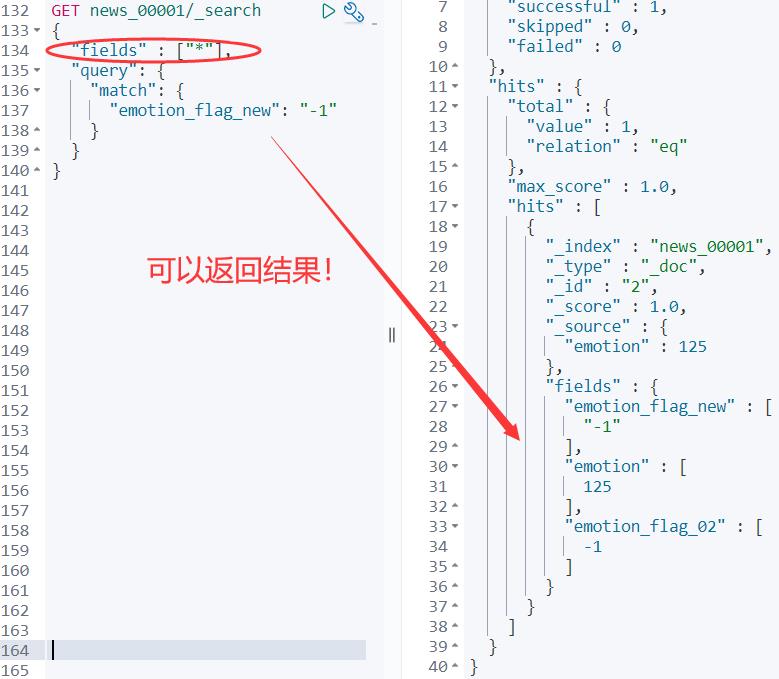
}返回结果如下:
4.3 Runtime fields 核心语法解读
为什么加了:field:[*] 才可以返回检索匹配结果呢?
因为:Runtime fields 不会显示在:_source 中,但是:fields API 会对所有 fields 起作用。
如果需要指定字段,就写上对应字段名称;否则,写 * 代表全部字段。
4.4 如果不想另起炉灶定义新字段,在原来字段上能实现吗?
其实上面的示例已经完美解决问题了,但是再吹毛求疵一下,在原有字段 emotion 上查询时实现更新值可以吗?
实战一把如下:
POST news_00001/_search
{
"runtime_mappings": {
"emotion": {
"type": "keyword",
"script": {
"source": """
if(params._source['emotion'] > 0 && params._source['emotion'] < 300) {emit('-1')}
if(params._source['emotion'] >= 300 && params._source['emotion'] <= 700) {emit('0')}
if(params._source['emotion'] > 700 && params._source['emotion'] <= 1000) {emit('1')}
"""
}
}
},
"fields": [
"emotion"
]
}返回结果:
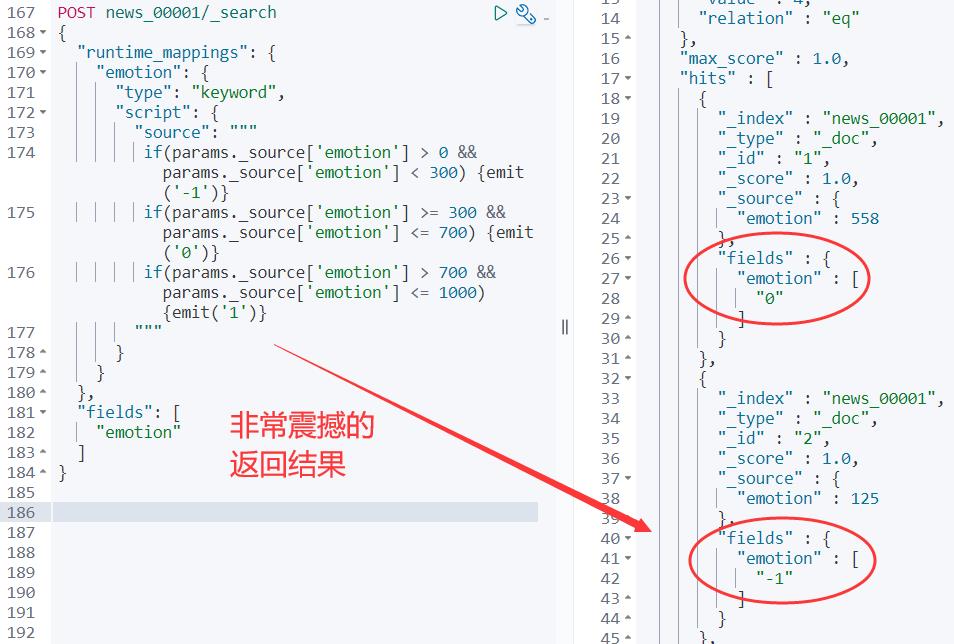
解释一下:
第一:原来 Mapping 里面 emotion是 integer 类型的。
第二:我们定义的是检索时类型,mapping 没有任何变化,但是:检索时字段类型 emotion 在字段名称保持不变的前提下,被修改为:keyword 类型。
这是一个非常牛逼的功能!!!
早期 5.X、6.X 没有这个功能的时候,实际业务中我们的处理思路如下:
步骤一:停掉实时写入;
步骤二:创建新索引,指定新 Mapping,新增 emotion_flag 字段。
步骤三:恢复写入,新数据会生效;老数据 reindex 到新索引,reindex 同时结合 ingest 脚本处理。
有了 Runtime field,这种相当繁琐的处理的“苦逼”日子一去不复回了!
5、Runtime fields 适用场景
比如:日志场景。运行时字段在处理日志数据时很有用,尤其是当不确定数据结构时。
使用了 runtime field,索引大小要小得多,可以更快地处理日志而无需对其进行索引。
6、Runtime fields 优缺点
优点 1:灵活性强
运行时字段非常灵活。主要体现在:
需要时,可以将运行时字段添加到我们的映射中。
不需要时,轻松删除它们。
删除操作实战如下:
PUT news_00001/_mapping
{
"runtime": {
"emotion_flag": null
}
}也就是说将这个字段设置为:null,该字段便不再出现在 Mapping 中。
优点 2:打破传统先定义后使用方式
运行时字段可以在索引时或查询时定义。
由于运行时字段未编入索引,因此添加运行时字段不会增加索引大小,也就是说 Runtime fields 可以降低存储成本。
优点3:能阻止 Mapping 爆炸
Runtime field 不被索引(indexed)和存储(stored),能有效阻止 mapping “爆炸”。
原因在于 Runtime field 不计算在 index.mapping.total_fields 限制里面。
缺点1:对运行时字段查询会降低搜索速度
对运行时字段的查询有时会很耗费性能,也就是说,运行时字段会降低搜索速度。
7、Runtime fields 使用建议
权衡利弊:可以通过使用运行时字段来减少索引时间以节省 CPU 使用率,但是这会导致查询时间变慢,因为数据的检索需要额外的处理。
结合使用:建议将运行时字段与索引字段结合使用,以便在写入速度、灵活性和搜索性能之间找到适当的平衡。
8、小结
本文通过实战中添加字段的问题引出解决问题的几个方案;传统的解决方案大多都需要更改 Mapping、重建索引、reindex 数据等,相对复杂。
因而,引申出更为简单、快捷的 7.11 版本后才有的方案——Runtime fields。
Runtime fields 的核心知识点如下:
Mapping 环节定义;
在已有 Mapping 基础上更新;
检索时使用 runtime fields 达到动态添加字段的目的;
覆盖已有 Mapping 字段类型,保证字段名称一致的情况下,实现特定用途
优缺点、适用场景、使用建议。
你在实战环节使用 Runtime fields 了吗?效果如何呢?
欢迎留言反馈交流。
参考
https://opster.com/elasticsearch-glossary/runtime-fields/
https://www.elastic.co/cn/blog/introducing-elasticsearch-runtime-fields
https://dev.to/lisahjung/beginner-s-guide-understanding-mapping-with-elasticsearch-and-kibana-3646
https://www.elastic.co/cn/blog/getting-started-with-elasticsearch-runtime-fields
推荐
1、重磅 | 死磕 Elasticsearch 方法论认知清单(2021年国庆更新版)
更短时间更快习得更多干货!
已带领70位球友通过 Elastic 官方认证!
中国仅通过百余人

比同事抢先一步学习进阶干货!
以上是关于Elasticsearch 运行时类型 Runtime fields 深入详解的主要内容,如果未能解决你的问题,请参考以下文章