Hbase
Posted 买糖买板栗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase相关的知识,希望对你有一定的参考价值。
目录
架构图

核心概念解释:
- HLog:Hbase写数据先写到Mem Store(JVM内存存储),为了防止机器挂了数据丢失,写到Mem Store之前先记录操作日志到HLog。Mem Store中的数据在符合特定条件下,再写入到StoreFile,写入后删除HLog中的记录;
- Mem Store:记录最新写入的value,支持随机修改(Hbase中DataNode中的数据是不支持随机修改的)
Hbase写流程

- Client进行写操作的时候,会先查询Meta缓存中是否含有目标table的region信息以及Meta表位置信息,如果有就不再去访问zookeeper,而是直接进行下一步的操作。如果没有则会去访问zookeeper,获取hbase:meta表位于哪个Region Server。Meta表主要用于存储用户表和系统表的所在位置。在低版本的时,会有一个-ROOT-表,用于存储meta表的位置信息,这个操作主要是为了预防meta表过大而需要对meta表进行切分,切分之后就会造成有多个meta表,这就需要一个表准们存储meta表的位置信息;
- 获取到meta的位置信息以后,会去访问对应的Region Server,根据读请求的信息namespace:table/rowkey,查询处目标数据位于哪个Region Server中的哪个Region。并将该table的region信息以及meta表的位置信息缓存到客户端的meta cache,方便下次访问;
- 然后与得到的RegionServer通讯,将数据顺序写入(append)到WAL,此时并不进行同步操作,即并不将wal写到hdfs
- 将数据写入对应Region的memstore中,数据会在MemStore中进行排序;
- 同步wal,将wal写到hdfs,如果不能同步成功则会进行回滚操作。wal和数据写入到memstore是一个整体的事务,要么都成功要么都失败;
- 上面成功后,向客户端发送ack;
- 等达到MemStore的刷写时机后,将数据刷写到HFile中
说明:
- 数据读写不需要HMaster参与
- “当memstore写入的值变多,触发溢写操作(flush),进行文件的溢写,成为一个StoreFile”触发的条件:1、RegionServer内,单个Region里面的memstore>阈值1,所在Region的memstore全部刷到StoreFile;2、RegionServer内,所有的memstore的总大小>阈值2,所在RegionServer的memstore全部刷到StoreFile
- 当文件过多时,会触发文件的合并(Compact)操作,合并有两种方式(major,minor),多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除;minor compaction:小范围合并,默认是3-10个文件进行合并,不会删除其他版本的数据;major compaction:将当前目录下的所有文件全部合并,一般手动触发,会删除其他版本的数据(不同时间戳的)
- 当region中的数据逐渐变大之后,达到某一个阈值,会进行裂变(一个region等分为两个region,并分配到不同的regionserver),原本的Region会下线,新Split出来的两个Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。由此可知HBase只是增加数据,所有的更新和删除操作,都是在Compact阶段做的,所以用户写操作只需要进入到内存即可立即返回,从而保证I/O高性能读写。
- 上述一条,若列族很多,很容易导致很多小文件产生,Hbase不推荐过多的列族,1-2个即可
- Hbase希望使用者,单个RegionServer内不要有太多的Region,单个Region 5~20G
Hbase读流程
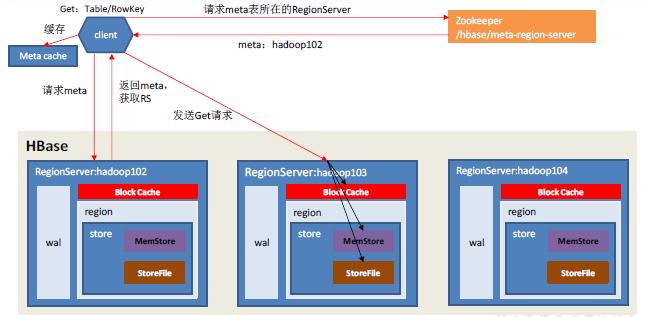
- Client 先访问zookeeper,获取hbase:meta 表位于哪个Region Server。
- 访问对应的Region Server,获取hbase:meta 表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
- 与目标Region Server进行通讯;
- 分别在Block Cache(读缓存),MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
- 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为64KB)缓存到Block Cache。
- 将合并后的最终结果返回给客户端。
获取Meta等相关操作同写流程,需要注意的点如下:
- 读,先读“读缓存”,若缓存没有,再从memstore内存中读,若还没有,则只能从storefile中加载冷数据了
- “读缓存”:Block Cache,是RegionServer级别的,不是Region级别的,他也不在JVM的堆中,其实我目前也不懂
- 读数据的时候,block cache、memstore、storefile中的数据要一起读,读出来之后要做merge(合并),merge的过程中要比较所有读出的数据的时间戳,谁的时间戳大,就返回哪一条数据。此时,磁盘和内存是一起读的,磁盘中的数据读出来之后会放入block cache中,所以,读流程无论如何都会扫描磁盘,也就造成了HBase的读流程要慢于写流程。
- 从读写流程的两幅流程图可以看出,HMaster好像并没有参与整个的读写流程,其实Master可以完全不参与读写流程,因为读写数据所需的meta表位置信息是存储在zookeeper的,zookeeper担任了一部分Master与客户端的交互的功能,所以即使Master挂掉了,用户也可以在客户端进行读写。但是如果Master一直处于挂掉的状态,对于HBase集群来说是非常不健康的,比如集群中某个RegionServer出故障挂掉了,那么就无法及时将该RegionServer上的Region转移到其他健康的RegionServer上面。
RowKey设计
- 考虑
1、要解决热点问题,一般did都是自增的话最好是倒序的,放在开头,不需加盐,对scan友好。
2、做好预分区。
3、组成rowkey的字段最好是定长的。
4、column family是存储的真正逻辑单元,建议family不要过多
5、分多张表也可以,单张表也可以,但有一个点需要注意,就是hbase会split,分裂的时候对写入是有一些影响的,要防止数据量小的被数据量大的影响到 - 目的:数据能均衡分布在Region中
Hbase-client操作
- 在HBase中Connection类已经实现对连接的管理功能,所以不需要在Connection之上再做额外的管理。另外,Connection是线程安全的,然而Table和Admin则不是线程安全的,因此正确的做法是一个进程共用一个Connection对象,而在不同的线程中使用单独的Table和Admin对象;
以上是关于Hbase的主要内容,如果未能解决你的问题,请参考以下文章