微博数据爬取 之 “保熟”的爬虫
Posted 风信子的猫Redamancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微博数据爬取 之 “保熟”的爬虫相关的知识,希望对你有一定的参考价值。
微博数据爬取 之 “保熟” 的爬虫
文章目录
起因
这篇博客的原因单纯只是为了记录了一下自己的思路和最后的一些结果哈哈,并没有什么商业用途,所以大家谨慎一点哈哈哈,仅供学习。
起因呢,就是有一个学姐需要我在微博上爬取一个话题上的数据,将里面的发布者ID,发布时间,发布内容,点赞收藏评论都给爬下来,这样的话,他们就根据这样的数据,去针对一个话题进行一个文本数据分析之类的。具体的后续操作我就不多说了,这里我就说一下我的爬虫之路。
(实际上,我的爬虫是自学的,在大一的时候的疫情期间学的,虽然零零散散用的不多,但是总归是一项技能,我们可以从中获取一些信息,或者更简单来说,用计算机简化我们的操作,节省时间,还是有用的哈哈哈)
这里我对刘华强刘华强卖瓜这个话题进行爬取哈哈哈,因为B站有时候还蛮火的,所以这一定是一个保熟的爬虫

解析微博 刘华强卖瓜 网址参数Params
当我们想要爬微博的数据的时候,那我们一定要解析一下这个微博的网址有什么特点,或者更专业一点,他的域名有包含什么信息,亦或是说,他们的域名有带什么参数。

首先,我们可以看到我们的微博主页是这样的,我们需在这里搜索我们想要的数据
我最近对B站的刘华强刘华强卖瓜比较感兴趣,那么我们就在微博中爬取有关刘华强刘华强卖瓜的数据吧,那我们就可以搜索刘华强刘华强卖瓜,看一下刘华强刘华强卖瓜跌落神坛后,还有多少人有发布关于他的数据,我们就可以得到以下的页面,接下来我们就解析一下这个域名和里面的参数。
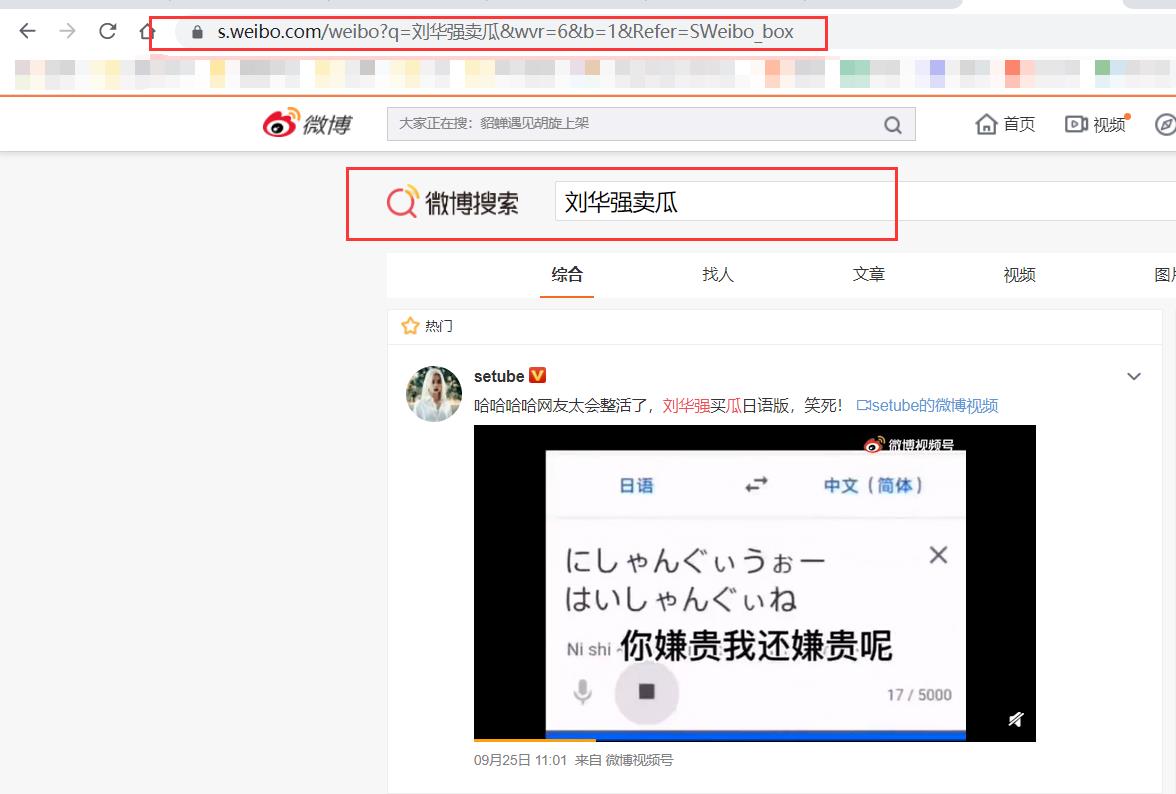
搜索以后,我们可以得到网址https://s.weibo.com/weibo?q=%E5%88%98%E5%8D%8E%E5%BC%BA%E5%8D%96%E7%93%9C&wvr=6&b=1&Refer=SWeibo_box,我们可以仔细对我们的网址进行一个解析,很容易我们就可以得出,首先https://s.weibo.com/weibo就是微博的原始域名,如果我们进入这个页面,我们可以看见最原始的微博的搜索页面。

然后除此之外,好像还有一些参数,q,wvr,b,Refer这些参数,对于这些数据,我经过一些测试,我还是没有明白其中一些参数,但是有些还是明白的,这里解析一下其中的一些参数
部分参数解析
- q:我们可以看到,我们的数据中有一段“%E5%88%98%E5%8D%8E%E5%BC%BA%E5%8D%96%E7%93%9C”这样的字符串,实际上,这个字符串就是“刘华强刘华强卖瓜”,网页自动对其编码变成了字符串,实际上我们换成刘华强刘华强卖瓜也是可以的。
- Refer:我推测是来源,但是这个其实也没什么用,这里就是说,我们是通过微博主页搜索的,也就是Weibo_box
另外两个我并没有试出来,看起来是一些无关紧要的一些参数,因为去掉两个参数后,依然可以得到一摸一样的结果,我只能猜测,可能和微博数据无关,和其他有关吧
高级搜索网址解析
当然,如果你觉得解析到这里就结束了,那就比较low了哈哈哈,微博给了我们一个高级搜索的框,所以我们可以好好利用这个框去设置参数从而爬取特定的数据。
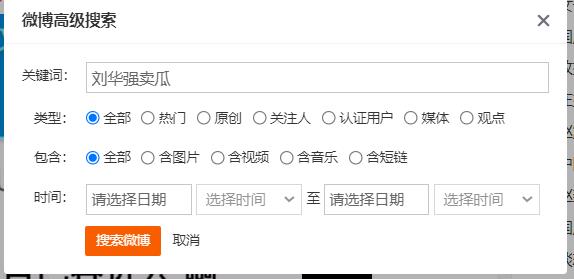
比如我们选择全部,包含也选择全部,不变,我们会发现我们的网址已经改变了,已经变成了https://s.weibo.com/weibo?q=%E5%88%98%E5%8D%8E%E5%BC%BA%E5%8D%96%E7%93%9C&typeall=1&suball=1&Refer=g,可以看到,我们的结果中,有四个参数,其中q还是一样的,因为我们的关键词不变,这里多出了两个参数
- typeall :1 代表着包含着所有的类型 如 热门,原创等
- suball :1 代表着含图片,含视频,含音乐,含短链
- Refer :q 代表着关键词搜索
当然,我们爬数据肯定是有目的的爬取对吧,所以我们还得选择一些时间,刘华强刘华强卖瓜入狱是7.31号,在这两个月都是刘华强刘华强卖瓜的热度期,所以来说,我们就以7.1-9.1号为我们的爬取时间范围吧。
我们选择了时间以后,我们发现多了一个参数,也就是timescope,并且从后面的数据来看,实际上,这个参数的意思就是时间线,所以说我们可以设置时间线参数对其爬取,并且我们甚至可以设置到小时级别的数据进行爬取。
- timescope :custom:2021-07-01:2021-09-01 代表7.1-9.1的数据
在这里的话,我就不解析其他的了,因为方法是一样的,我们可以根据其中的结果进行一个判断,通过高级搜索观察其中的参数。
解析微博 刘华强卖瓜 的Header
如果也学过爬虫的话,我们大概知道有header的东西,其实更通俗简单的来说,这个就是一个作为模仿浏览器操作的参数,如何或者这个参数,或者是前面解析网址后的参数呢,接下来我们就可以操作一下了
开发者工具
首先,我们需要打开开发者工具,大部分浏览器可以直接按F12打开开发者工具,如果没显示,就去设置找开发者工具,我们会出现这样的界面,这里的右边就是我们的网页源代码。

当然,这个对我们来说还没什么用,我们需要点到里面的Network,在里面看看有没有我们的网址。

因为我们刚刚加载,所以没有显示,我们可以刷新一下我们的页面的,或者直接按ctrl + R就可以得到数据,我们可以看到,我们得到我们的网页的数据了,微博的数据一般,没有ajax请求,如果有ajax请求,他的网址很难找。

打开这个以后,我们可以在里面看到他原始的代码,并且是没有CSS和JS的,在里面我们可以看到我们的请求头,和真正的网址。
得到参数
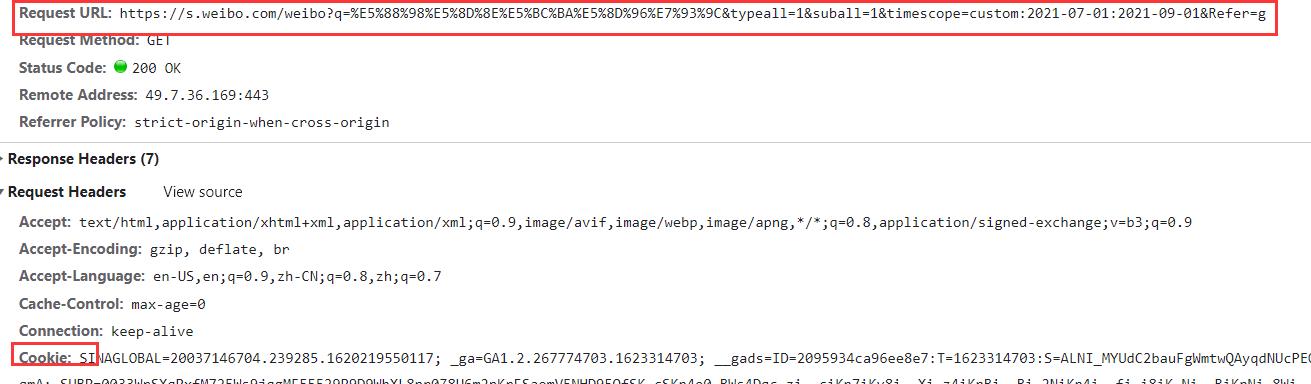
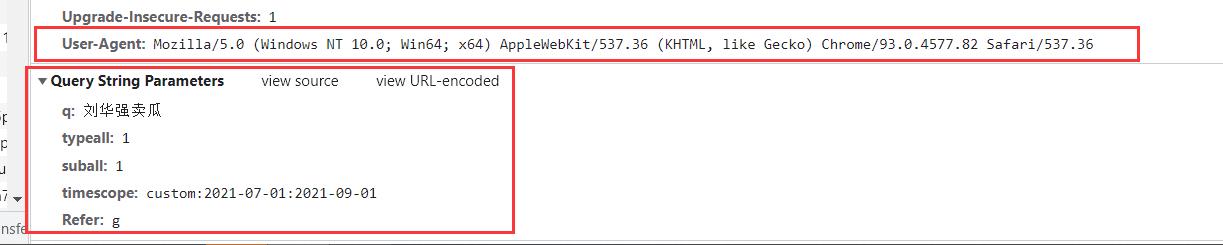
在里面我们看到几个东西,这些就是我们的请求头的数据,第一个是我们的请求网址,当然微博很人性化,没有加密很多,就是原始的网址,其次就是Cookie和User-Agent,如果有爬虫的可能都知道这是什么,如果不知道的话,我这里就简单提一下
- Cookie其实就是一个你的身份证,因为有时候我们爬取微博是需要登录的,或者爬取淘宝的时候,这时候,需要我们登录,如果没有登录就不行,那我们可以用Cookie相当于模仿我们的登录,这样我们就可以不用一直登录了
- User-Agent可能大家都比较了解吧,就是我们爬虫是去模仿人的操作,那我们就假装我们是通过浏览器访问的,所以这个参数里面就是一些浏览器的名字,也就是说明,我们的code去伪装浏览器进行访问,这样就不会被检测出来。
代码code
最后的Parmas就更容易理解了,就是前面说要传递的参数,所以我们就可以开始设置我们的代码了
前面可能漏说了一个,就是page参数,我们可以设置我们的page进行跳转页码,由于我们默认第一页,所以是没有显示的,但是如果我们尽可能爬取数据,我们要设置这个page
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/68.0.3440.75 Safari/537.36',# 伪装成浏览器
'Cookie':'你的Cookie',
'Host':'s.weibo.com',
'sec-ch-ua':'"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':'"Windows"',
'Sec-Fetch-Dest':'document',
'Sec-Fetch-Mode':'navigate',
'Sec-Fetch-Site':'none',
'Sec-Fetch-User':'?1',
'Upgrade-Insecure-Requests':'1',
'Connection': 'keep-alive'
}
params = {
'q':'刘华强刘华强卖瓜',
"typeall":"1",
"suball":"1",
'timescope':'custom:2021-07-1:2021-09-1',
# "Refer":"SWeibo_box",
"Refer":"g",
'page':"1"
}
就这样,我们就设置好我们的参数了嘻嘻
解析微博 刘华强卖瓜 的内容
接下来就让我们干点正事吧,看看我们需要什么数据,那我们就对他们进行一个爬取吧,首先我们先确定我们想爬的内容
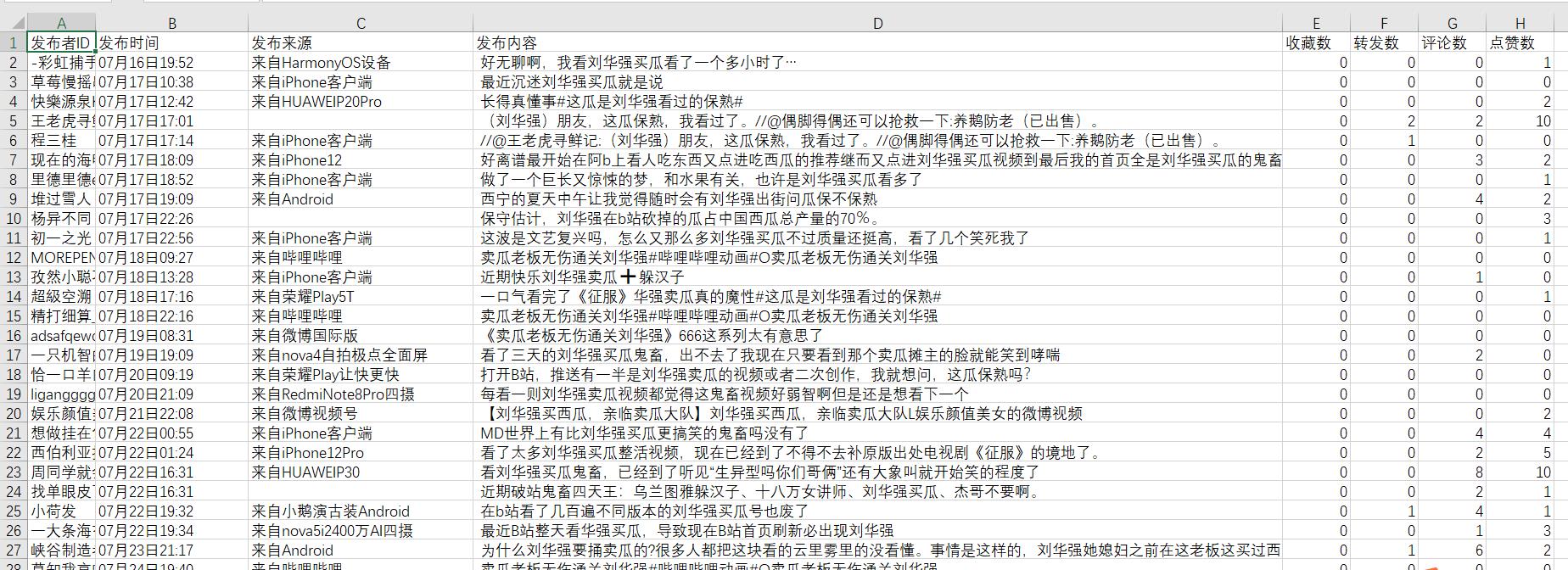
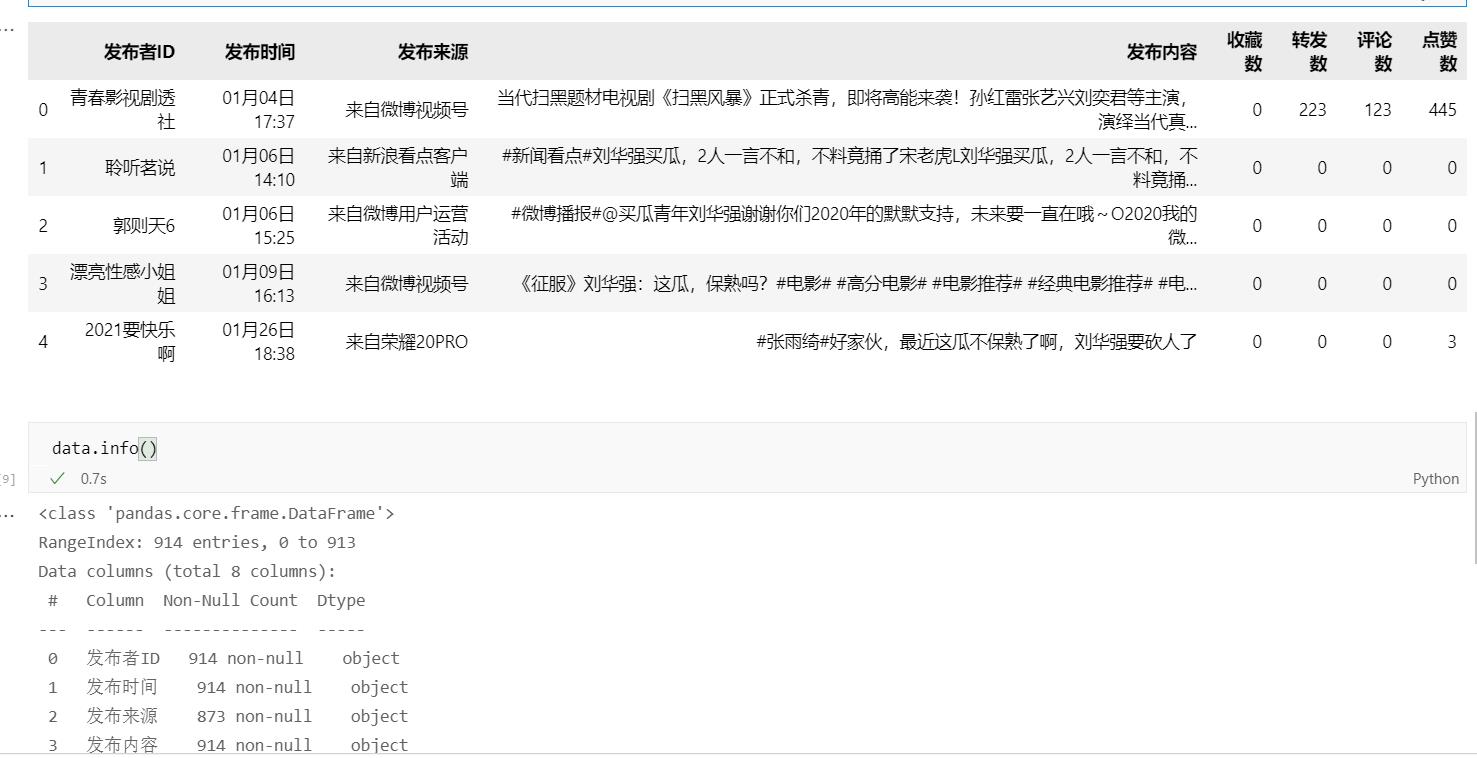
那我们希望最后的数据是下面这样子的,有发布者ID,有时间,有内容,还有点赞转发评论收藏的数目,那我们就开始吧
利用xpath爬 刘华强卖瓜 数据
我个人比较喜欢xpath来解析爬取,有些人喜欢用Beautifulsoup来解析数据,我觉得都可以,没有优劣吧,只是说我更喜欢哈哈哈
那这样的话,我们就开始来解析我们的数据吧,一样的,我们解析的是网页源代码的数据,所以说,首先我们都要先对我们源代码进行解析
我们可以看到,其中微博的数据在一个id="pl_feedlist_index"内,然后每一个微博的数据都在一个class="card-wrap"的div中
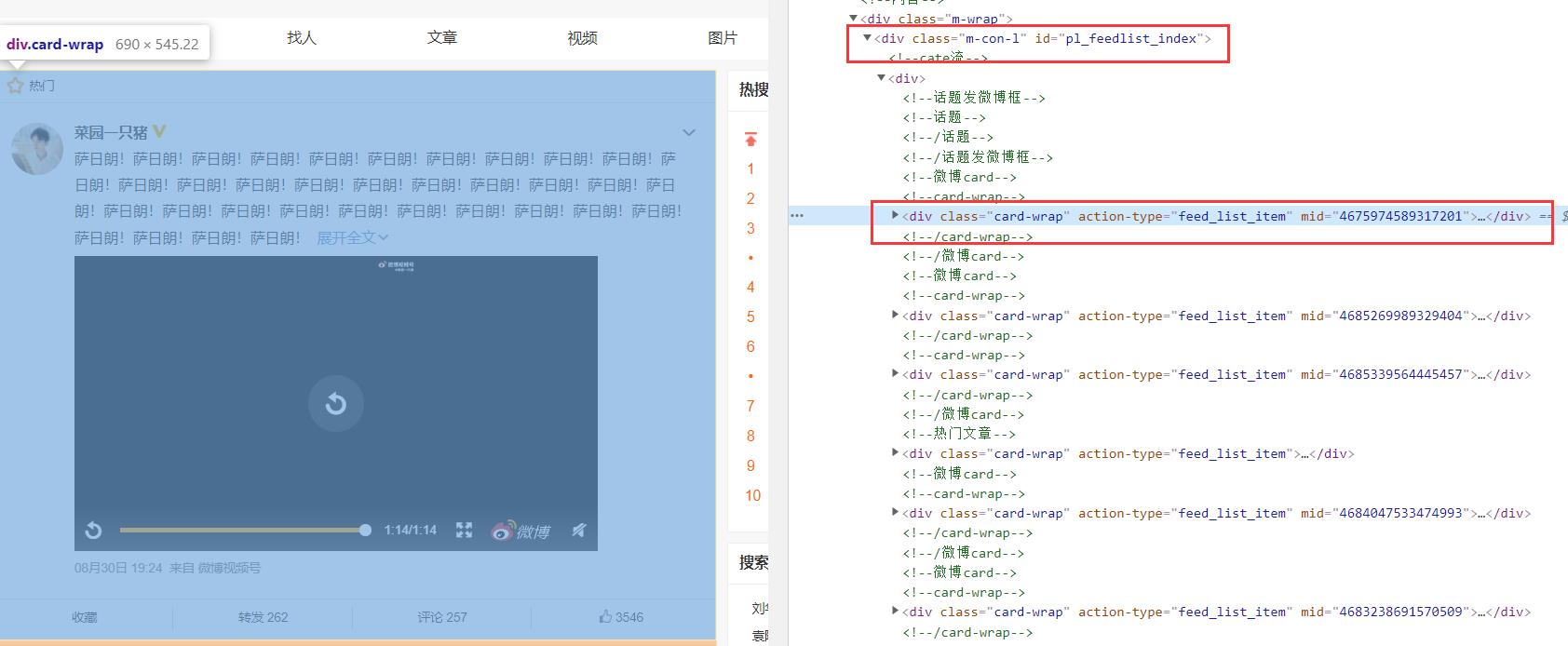
接着我们再仔细解析一下,观察一下具体的信息在哪,我们就可以得到相应的标签
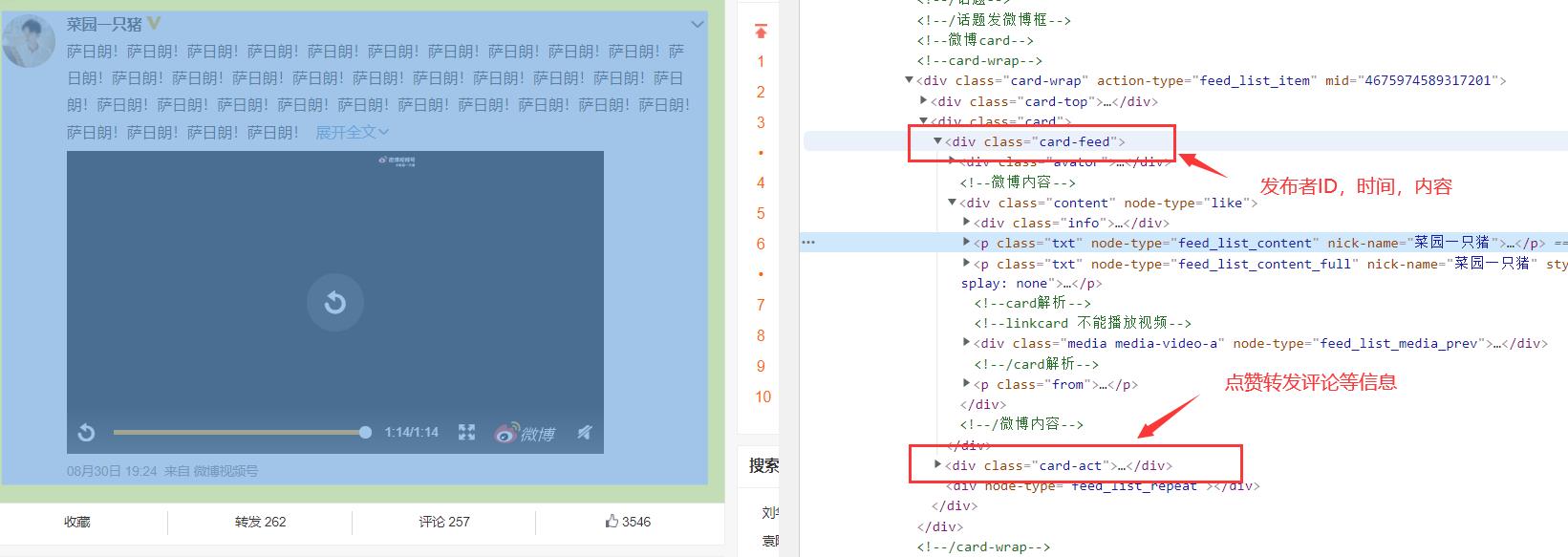
比如这里我对ID做一个xpath,我们可以看到,我们ID在一下这个位置,所以我们可以定义他的xpath就可以得到我们的结果,当然我们也可以直接右键去copy它的xpath了。

代码code
用这段简单的代码我们就可以得到我们的这页中所有ID的数据了
from lxml import etree
response = get_page(url, headers, params)
text = response.text
tree = etree.HTML(text)
ids = tree.xpath('//div[@id="pl_feedlist_index"]//div[@class="content"]/div[@class="info"]/div[2]/a[1]/text()')
同理我们就可以用xpath得到我们的所有的数据了
刘华强卖瓜 爬取可能比较细的难点
可能我讲的太简单了哈哈,但是其中还是有一些问题的,我这里就列举一下问题和我的方法,详细解释就不打了。
-
当然,xpath听起来好像很简单的样子,实际上并不简单哈哈,因为我们的微博内容的数据,总是不在一个标签里,所以在这里面还需要对其进行处理,就是xpath以后可能得到的是一个列表,所以说,我们还要进行一些拼接和整合就可以得到我们的结果了,当然也不是很难,肯定可以做出来的,相信你们哈哈,这里就不详细讲了。(提示:不要一次性解析所有内容,一个内容一个内容进行解析,这样内容才连续)
-
其次呢,还有一个比较坑的点,由于微博的数据有些大有些小,所以设置了JS,有一个展开全文,如果你用跟其他相同的办法去爬取,那么得到的数据是残缺的。但是我们可以解析一下源代码,在源代码中,实际上就是有两个标签,另一个有style="display: none;"属性,也就是不显示的。所以这时候,我们去解析我们的评论的时候,往往利用的是第二个。
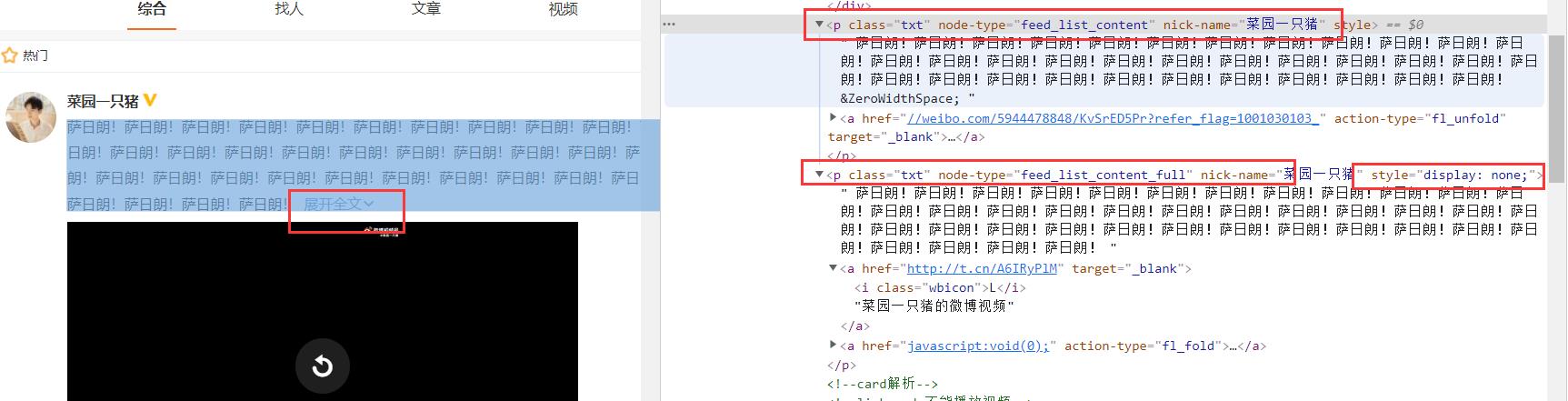
-
再者呢,就是点赞评论的数据了,对于这些数据来说,由于有时候里面是没有数据的也就是0,所以我们需要判断是否为0,并且在不为0的时候,我们也要将字符串转为我们的数字,也就是我们要取出我们的数字出来。
-
还有就是,你可能会觉得数据少了,为什么呢,因为微博一次搜索最多给你50页,一页大概20条,假设如果7.1号有1000+条,他只会出现时间较早的1000条,针对这种情况,我们可以再细粒度地对我们的时间线进行设置,可以设置为1小时的step,这样的话,我们就可以尽可能的爬取比较全的数据。同理得,有时候我们都没什么数据,我们可以设置比较大的时间跨度,这样我们就可以更快得到更多的数据了。
-
最后一点就是,其实我们的评论数据中有一些表情包是无法显示的,而且他们在源代码的数据也是不一的,比如视频的图标在源代码是L,所以针对这些数据呢,我们也可以进行适当的处理,不过这就是根据需求来写代码了
-
其实吧,还有一点,微博的安全中心呢,实际上也会对你进行检测,但是你也不用担心,只是一段时间,你访问的时候只能在首页而已,大概过一分钟吧,就可以又访问了,所以呢,其实还是不会封你号的。(还有我发现,我中午下午爬的时候,都是没有被发现的,只有凌晨的时候被发现了,说明有一个问题,在晚上人流量少的时候,可能容易被安全中心发现,但是当人流量多的时候呢,安全中心就很难检测到我们了哈哈,所以如果怕,可以找中午下午这种时间来爬取哈哈)、

刘华强卖瓜 的爬虫结果
由于数据有点少,所以我就对2021.1.1到2021.9.29进行爬取,看看微博有多少关于刘华强卖瓜的数据,总共也就924条也不多哈哈

我开水果的能卖给你生瓜蛋子啊!

以上是关于微博数据爬取 之 “保熟”的爬虫的主要内容,如果未能解决你的问题,请参考以下文章