Scrapy框架实战爬取网易严选-苹果12手机热评
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy框架实战爬取网易严选-苹果12手机热评相关的知识,希望对你有一定的参考价值。
1. 前言
Iphone13出来了,但是Iphone12依然香啊!
好不好,我们去网易严选看看便知~~



紫色的太可爱了!
所以我们今天的目标就是使用Scrapy抓取网易严选Iphone12评论数据,看看到底值不值得入手!
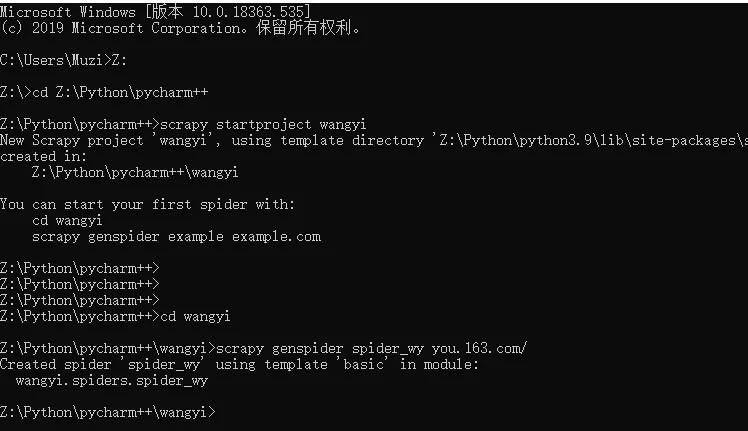
2. Scrapy项目创建
在你想存放项目的路径下,打开终端:
scrapy startproject apple
cd apple
scrapy genspider apple you.163.com
3. 网页分析
找到网页真实请求连接,可以看到数据实际上存储在json格式数据集里面。
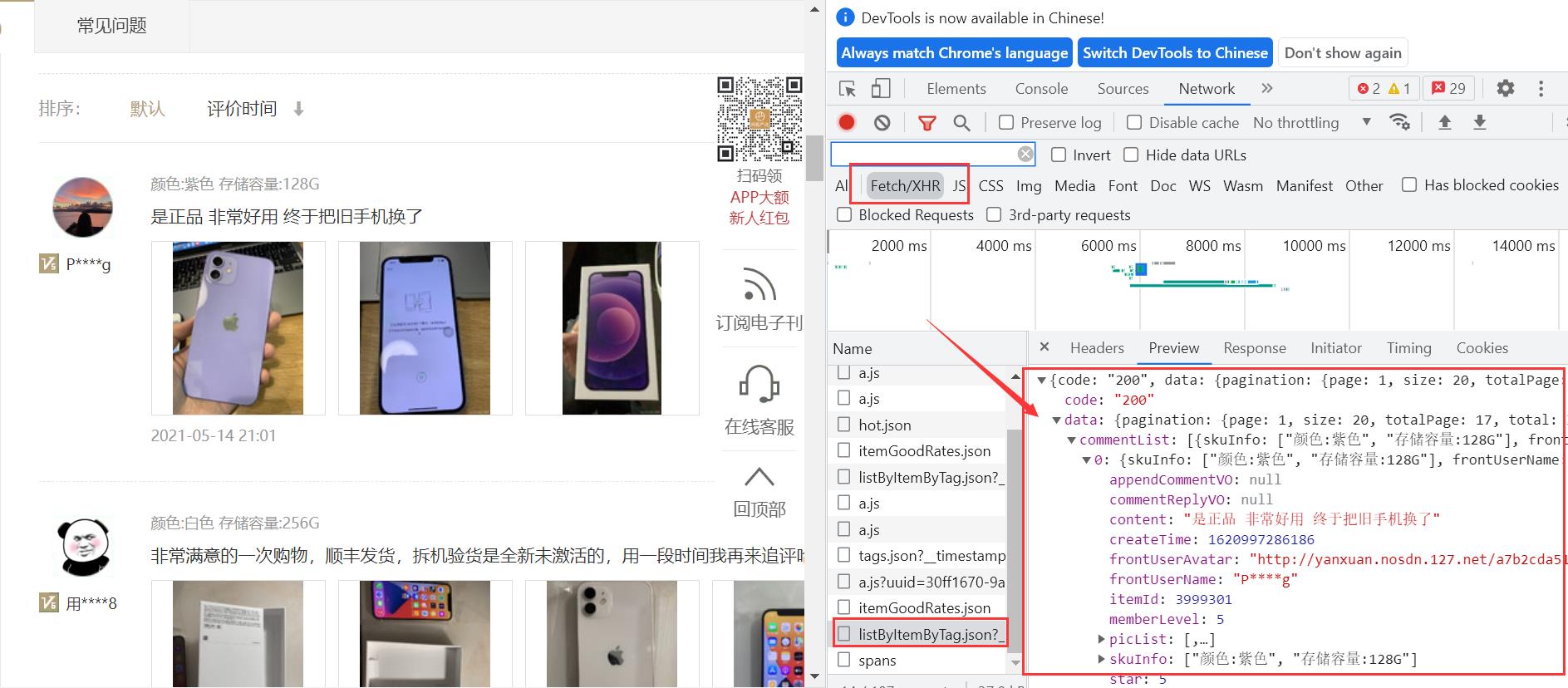
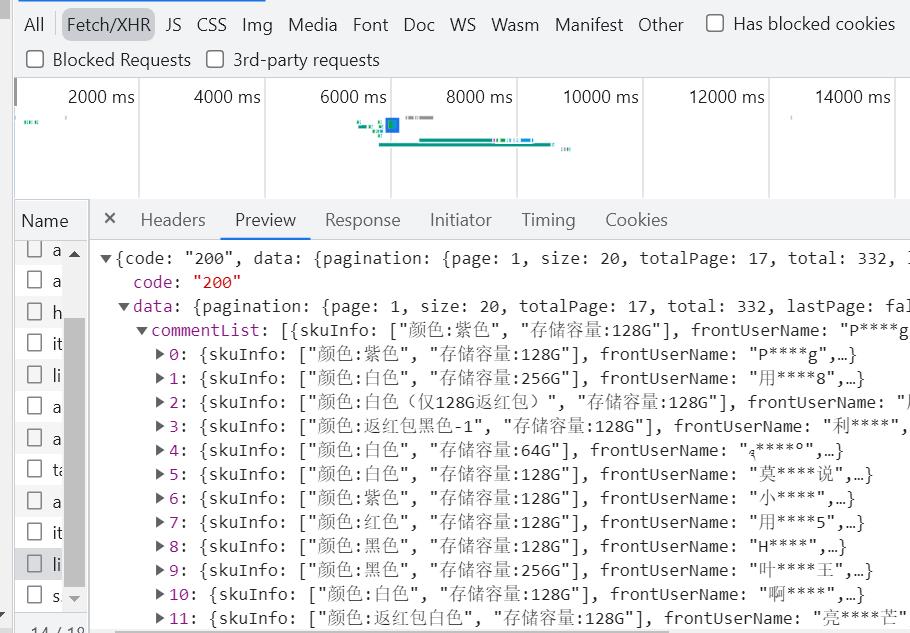
所以我们第一步必须先获取到这一整个json数据集。
网易严选的网站比京东淘宝要容易的多!算是入门练习的首选网站。
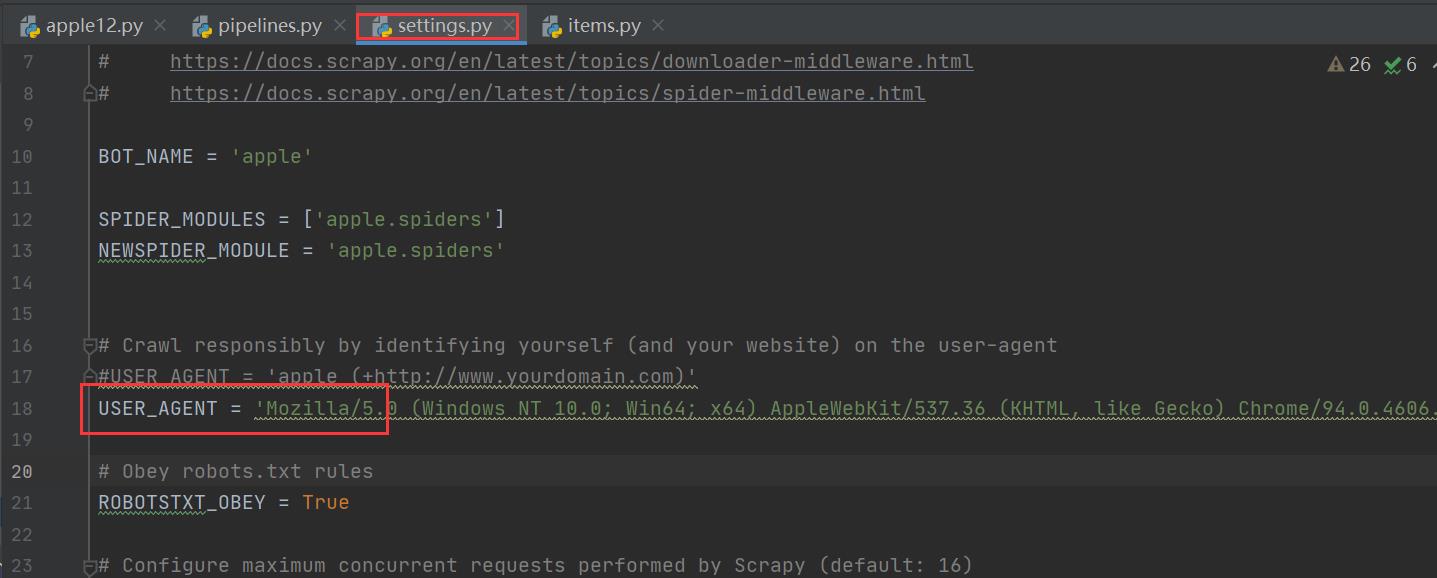
为了防止被网站防爬,我们还需在setting.py加上User-Agent,如下:
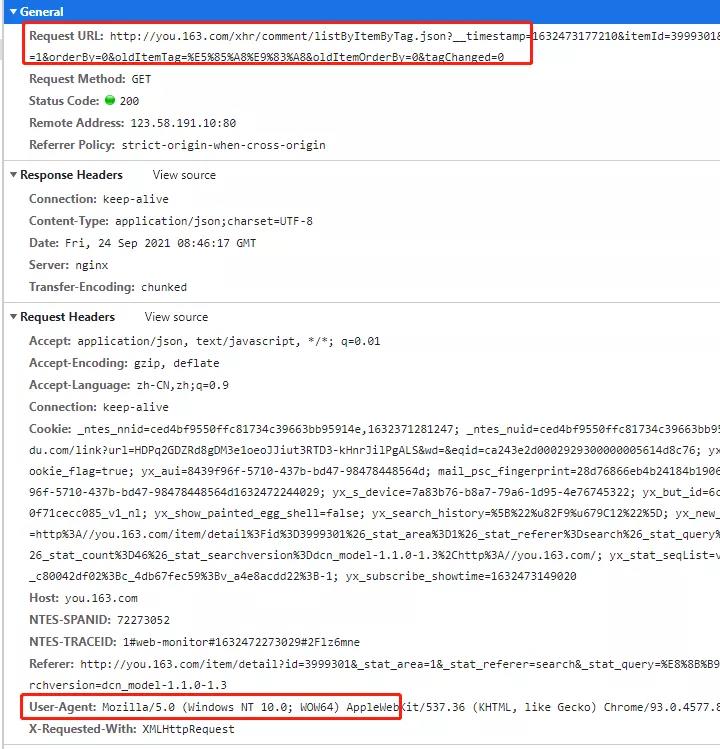
在setting.py配置文件中修改!
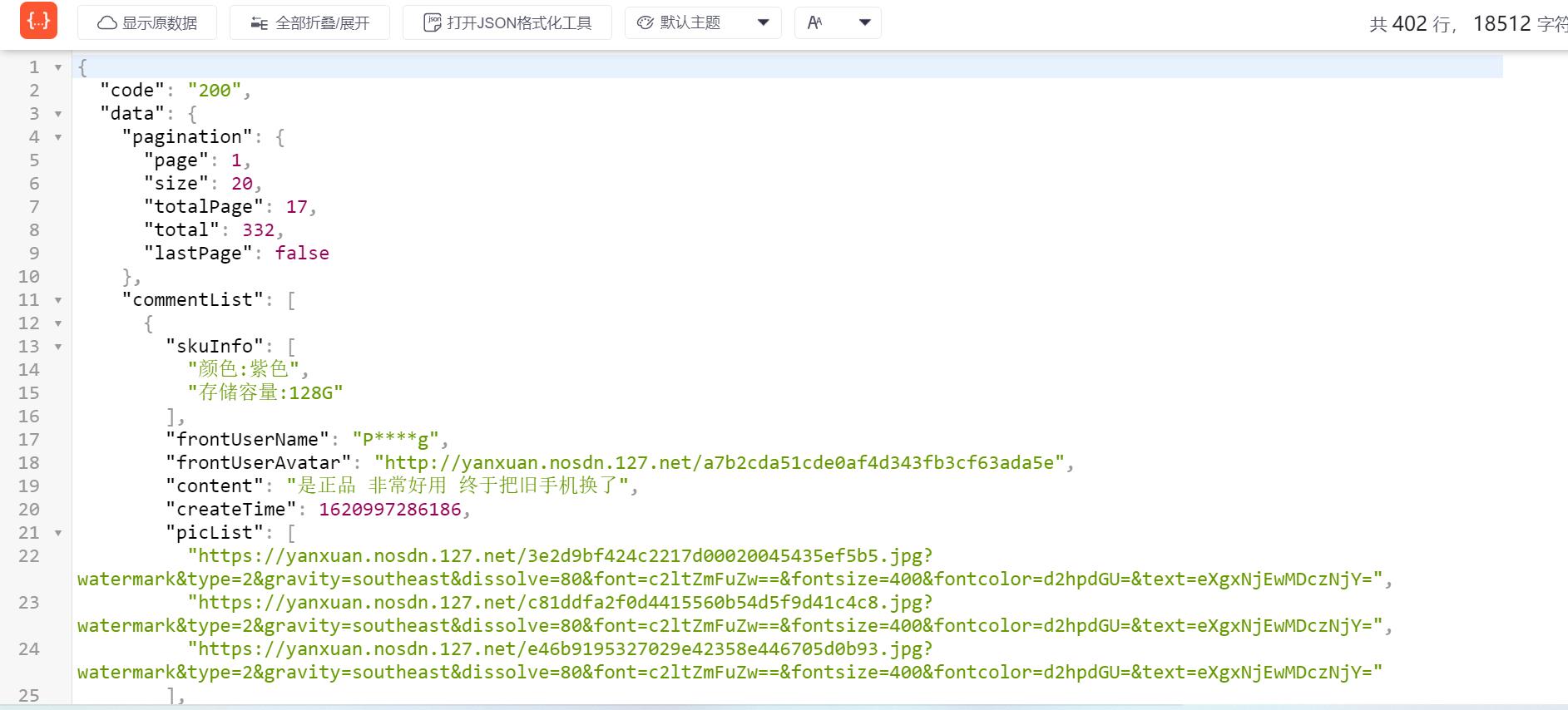
我们使用浏览器打开请求连接可以更加直观的观察数据格式:
4. 发送请求
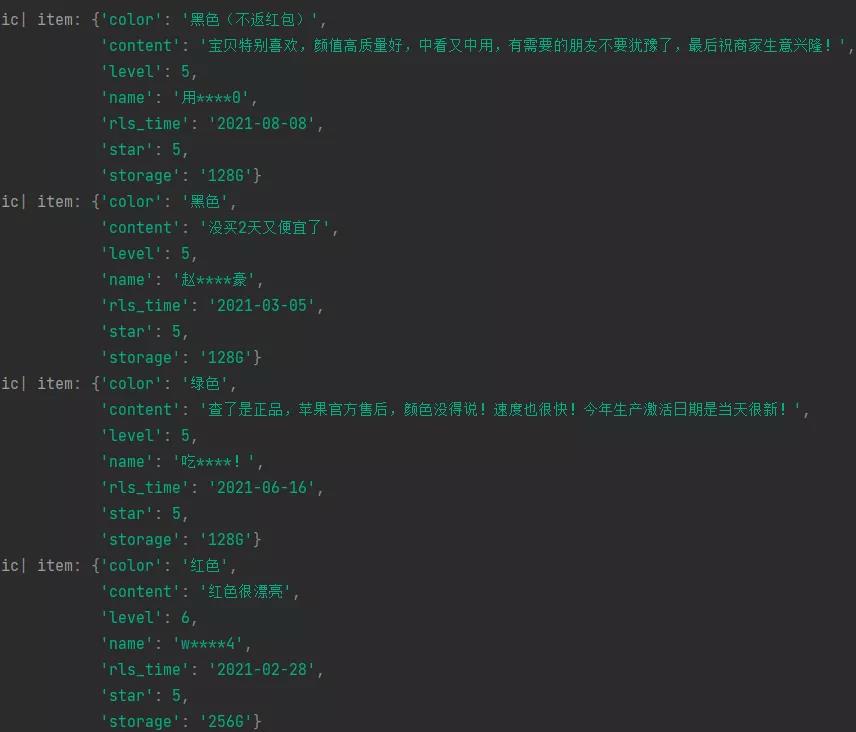
我们要此次要抓取的数据一共有7个,分别如下所示:
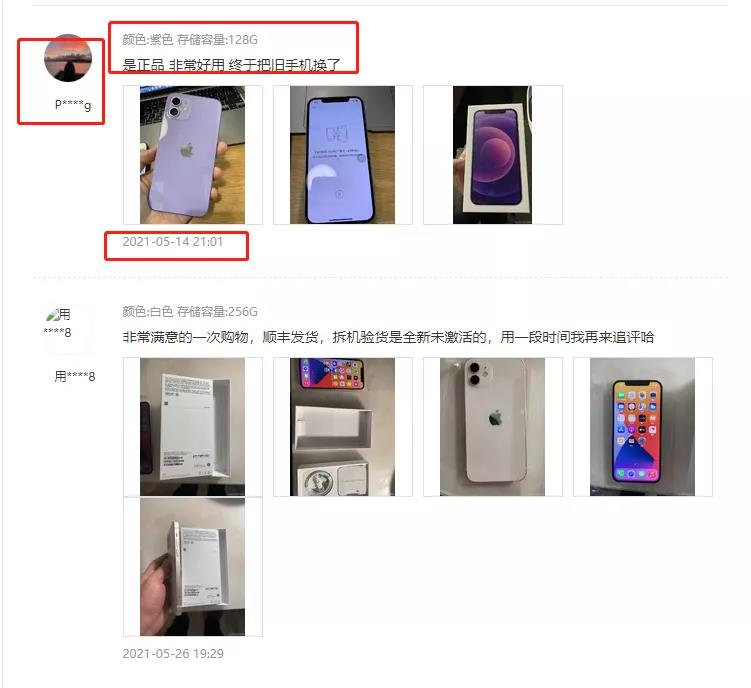
我们先在items中定义好我们要获取的数据:
class AppleItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 名称
name = scrapy.Field()
# 等级
level = scrapy.Field()
# 评分
star = scrapy.Field()
# 时间
rls_time = scrapy.Field()
# 颜色
color = scrapy.Field()
# 内存
storage = scrapy.Field()
# 评论
content = scrapy.Field()
刚才我们已经成功分析出来要获取的数据集合是一个json格式的,scrapy已经帮我们请求好了,我们直接打印or输出到文件中:
with open('wangyi.json', 'w', encoding='utf-8') as f:
# 将字典对象转为JSON字符串
json_data = json.dumps(response.json(), ensure_ascii=False, indent=True) + ',\\n'
# 将数据写入文件
f.write(json_data)
print("写入成功!")
浏览器成功响应给我们信息,这样看起来结构一目了然。
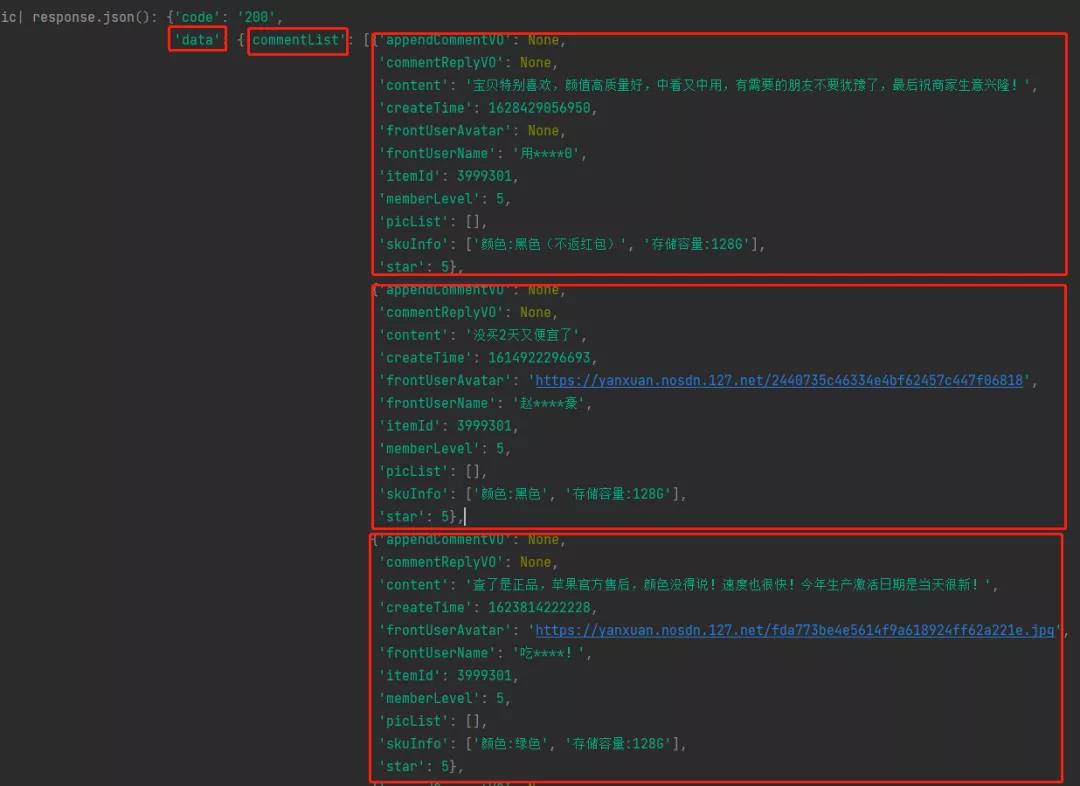

5. 提取信息
接下来我们要做的就是获取json格式中的commentList信息,因为我们需要的信息都在这个里面:
# 获取commentList
commentInfo = response.json()
commentList = commentInfo['data']['commentList']
# 获取商品对象
item = AppleItem()
# 获取所需信息
for comment in commentList:
# 名称
item['name'] = comment['frontUserName']
# 等级
item['level'] = comment['memberLevel']
# 评分
item['star'] = comment['star']
# 时间
rls_time = comment['createTime']
item['rls_time'] = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(rls_time/1000)).split(' ')[0] # 获取年月日
# 颜色
item['color'] = re.match("返红包(.*)|(.*)", comment['skuInfo'][0].split(':')[1]).group()
# 内存
item['storage'] = comment['skuInfo'][1].split(':')[1]
# 评论
item['content'] = comment['content']
yield item
6. 模拟翻页
经过摸金校尉的仔细摸查,发现只有17页的数据,每页20条,太少了吧!
网易严选确实我没用过!要不是作为练习,我可能就不知道Ta
分析请求参数:
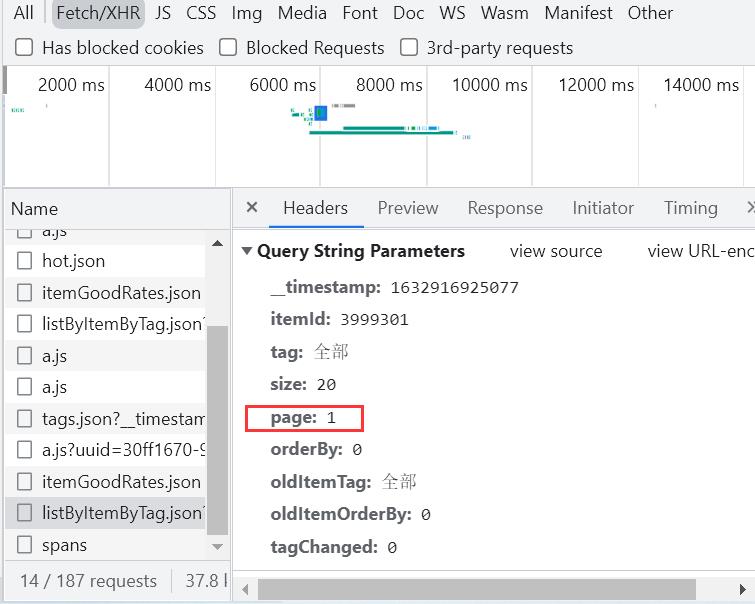
http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1632916925077&itemId=3999301&tag=全部&size=20&page=1&orderBy=0&oldItemTag=全部&oldItemOrderBy=0&tagChanged=0
http://you.163.com/xhr/comment/listByItemByTag.json
?__timestamp=1632916925077
&itemId=3999301
&tag=全部
&size=20
&page=1
&orderBy=0
&oldItemTag=全部
&oldItemOrderBy=0
&tagChanged=0
接着仔细看看URL会发现决定因素有&page=1&,因此考虑改变URL进行循环翻页!
Scrapy模拟翻页:
# 模拟翻页
global startNum
startNum += 1
start_urls = f'http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1632882219409&itemId=3999301&tag=全部&size=20&page={startNum}&orderBy=0&oldItemTag=全部&oldItemOrderBy=0&tagChanged=0'
print(startNum, "----", pagenum)
# 判断终止条件
if startNum <= pagenum:
# 构建请求对象,并且返回引擎
yield scrapy.Request(
url=start_urls,
callback=self.parse, # 对应的url由谁来解析(默认parse方法)
)
数据成功获取到,最后我们把它扔给Pipeline,让他自己去下载好,你可以选择自己想要保存的格式。
7. 数据保存
一般为了后续的数据分析和可视化专门写了一个可以直接保存在excel的函数,模板代码如下:
class ApplePipeline:
def open_spider(self, spider):
"""
初始化存储数据的对象
"""
self.wb = openpyxl.Workbook()
self.ws = self.wb.active
self.ws.append(['用户名称', '会员等级', '手机评分', '评论时间', '手机颜色', '手机内存', '评论'])
self.ws.title = '评论数据'
print('开启pipelines')
def process_item(self, item, spider):
item = dict(item) # 强转为字典
# print('---->', list(item.values()))
self.ws.append(list(item.values()))
print('一条数据添加成功!')
return item
def close_spider(self, spider):
"""程序终止默认执行方法"""
self.wb.save("./网易严选-苹果12评价数据集.xlsx")
print('数据保存成功!')
注意:一定要在setting中打开管道流pipeline的配置。
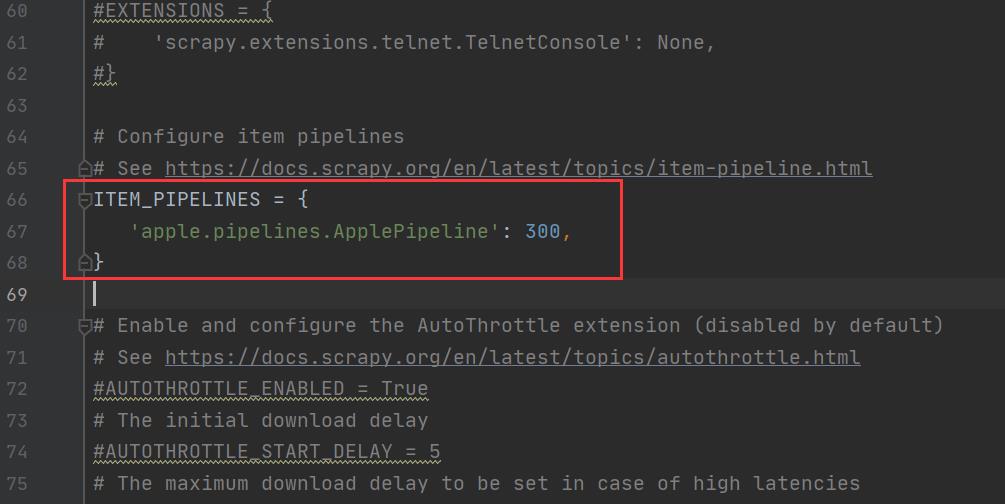
8. 结果展示
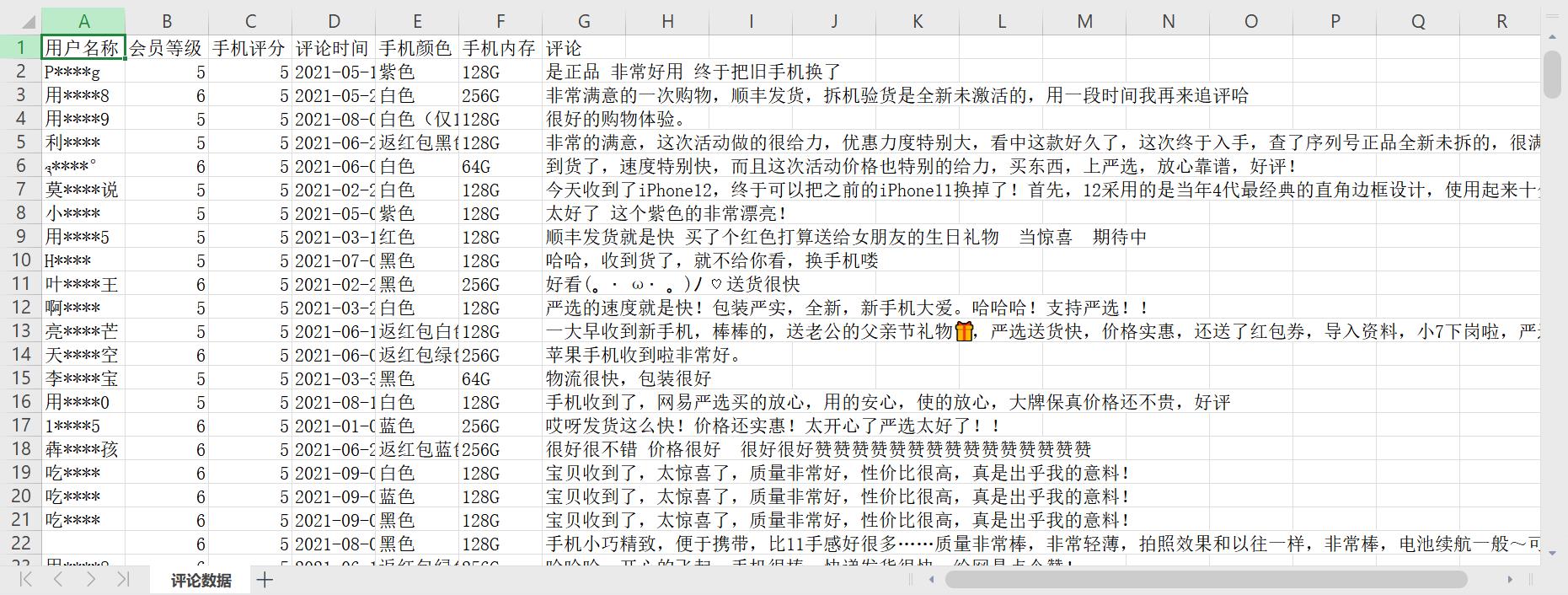
直接运行数据就会保存在我们本地啦!(部分数据如下)
9. 数据分析
请参考:【十三香吗?】网易严选-苹果12商品评论数据可视化分析
致谢:https://mp.weixin.qq.com/s/q0nIR-16aDdbID1OiNr5eQ
加油!
感谢!
努力!
以上是关于Scrapy框架实战爬取网易严选-苹果12手机热评的主要内容,如果未能解决你的问题,请参考以下文章