十三香吗?网易严选-苹果12商品评论数据可视化分析
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十三香吗?网易严选-苹果12商品评论数据可视化分析相关的知识,希望对你有一定的参考价值。
苹果手机评论数据可视化分析
1. 爬取数据
请参考:【Scrapy框架实战】爬取网易严选-苹果12手机热评
2. 准备工作
# 导入科学计算库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ['SimHei']
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
# 设置显示风格
plt.style.use('fivethirtyeight')
3. 数据预处理
data = pd.read_excel('./data/网易严选-苹果12评价数据集.xlsx')
data.head()
| 用户名称 | 会员等级 | 手机评分 | 评论时间 | 手机颜色 | 手机内存 | 评论 | |
|---|---|---|---|---|---|---|---|
| 0 | P****g | 5 | 5 | 2021-05-14 | 紫色 | 128G | 是正品 非常好用 终于把旧手机换了 |
| 1 | 用****8 | 6 | 5 | 2021-05-26 | 白色 | 256G | 非常满意的一次购物,顺丰发货,拆机验货是全新未激活的,用一段时间我再来追评哈 |
| 2 | 用****9 | 5 | 5 | 2021-08-09 | 白色(仅128G返红包) | 128G | 很好的购物体验。 |
| 3 | 利**** | 5 | 5 | 2021-06-21 | 返红包黑色-1 | 128G | 非常的满意,这次活动做的很给力,优惠力度特别大,看中这款好久了,这次终于入手,查了序列号正品... |
| 4 | ༣****° | 6 | 5 | 2021-06-06 | 白色 | 64G | 到货了,速度特别快,而且这次活动价格也特别的给力,买东西,上严选,放心靠谱,好评! |
# 重复数据检测
data[data.duplicated()]
| 用户名称 | 会员等级 | 手机评分 | 评论时间 | 手机颜色 | 手机内存 | 评论 | |
|---|---|---|---|---|---|---|---|
| 42 | 用****5 | 6 | 5 | 2021-06-21 | 返红包黑色-1 | 128G | 618价格非常划算,终于能用苹果手机了,谢谢网易! |
| 93 | 吃**** | 6 | 5 | 2021-09-09 | 白色 | 128G | 宝贝收到了,太惊喜了,质量非常好,性价比很高,真是出乎我的意料! |
| 120 | w****4 | 6 | 5 | 2021-09-04 | 白色 | 128G | 白色其实是最好看的颜色 |
| 176 | 用****8 | 6 | 5 | 2021-06-21 | 返红包蓝色 | 256G | 喜欢 |
| 179 | w****4 | 6 | 5 | 2021-06-19 | 返红包黑色-1 | 128G | 发货速度快良心卖家 |
| 293 | 吃**** | 6 | 5 | 2021-03-07 | 黑色 | 128G | 好 |
| 313 | 善****红 | 6 | 5 | 2021-02-17 | 黑色 | 128G | 东西很好,good |
# 删除重复数据
data = data.drop_duplicates()
# 删除缺失数据
data = data.dropna() # inplace=True:df = df.dropna(inplace=True)因此,这段代码的结果是将把None分配给df。
data.duplicated().any() # 无重复
False
我们在此使用pandas对数据进行读取然后去重复和去除空值处理。
随机抽取五条数据展示如下:
# 抽样展示
data.sample(5)
| 用户名称 | 会员等级 | 手机评分 | 评论时间 | 手机颜色 | 手机内存 | 评论 | |
|---|---|---|---|---|---|---|---|
| 31 | m****3 | 5 | 5 | 2021-07-05 | 返红包白色 | 128G | 是正品,发货挺快,618很实惠,终于可以换新手机咯 |
| 106 | 3****5 | 6 | 5 | 2021-09-12 | 蓝色 | 128G | 666 |
| 209 | 喏**** | 5 | 5 | 2021-03-30 | 红色 | 128G | 查了是正品,虽然比外面贵几百,但相信严选 |
| 100 | 用****3 | 5 | 5 | 2021-06-26 | 返红包黑色-1 | 128G | 用了一段时间才来评价,系统很流畅,反应速度也很快,拍照效果不错,非常清晰,续航能力强,内存大... |
| 61 | 蔡****秀 | 6 | 5 | 2021-06-09 | 绿色 | 256G | 喜欢,漂亮,还要慢慢熟悉使用方法 |
4. 词云可视化
data['评论']
0 是正品 非常好用 终于把旧手机换了
1 非常满意的一次购物,顺丰发货,拆机验货是全新未激活的,用一段时间我再来追评哈
2 很好的购物体验。
3 非常的满意,这次活动做的很给力,优惠力度特别大,看中这款好久了,这次终于入手,查了序列号正品...
4 到货了,速度特别快,而且这次活动价格也特别的给力,买东西,上严选,放心靠谱,好评!
...
327 很好
328 高质量的评价在这儿了
329 很不错的,可以。
330 流程有点长
331 好好好好好好好好好好好好好好好好好好好好好好好好好好好好好好好好好好好好好好好好茅台来两瓶
Name: 评论, Length: 320, dtype: object
# 导入绘制词云的工具包
from wordcloud import WordCloud
# from scipy.msc import imread
def get_word_cloud(keywords_list):
# 实例化绘制词云的类, 其中参数font_path是字体路径, 为了能够显示中文,
# max_words指词云图像最多显示多少个词, background_color为背景颜色
# mk=imread('data\\chinamap.jpg')
mk = plt.imread('data/apple1.jpg')
wordcloud = WordCloud(font_path="simhei.ttf", max_words=200, background_color="white", mask=mk, random_state=200)
# 将传入的列表转化成词云生成器需要的字符串形式
keywords_string = " ".join(keywords_list)
# 生成词云
wordcloud.generate(keywords_string)
# c.to_file("pywordcloud.png") # 输出词云文件
# 绘制图像并显示
plt.figure(figsize=(15, 8), dpi=200)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
allSentence = ' '.join(list(data['评论'].values))
# 停用词
stopwords = [',', '。', '\\n', '\\xa0', '-', '(', ')', '!', '.', ' ']
# jieba分词
import jieba
import logging
# 关闭jieba log输出
jieba.setLogLevel(logging.INFO)
word_cuted = jieba.lcut(allSentence)
# 数据处理
pureWord = [word for word in word_cuted if len(word) > 1 and word not in stopwords]
pureWord
['正品',
'非常',
'好用',
'方法',
'好评',
'好看',
'紫色',
'漂亮',
...]
get_word_cloud(pureWord)


get_word_cloud(pureWord)


词云图展示如下:看来Iphone12依旧还是很香的,虽然13出来了但是依旧值得入手!
5. 词频可视化
我们提取网易手机评论前十大高频词汇如下:
from collections import Counter
# 统计词频
wordcount = Counter(pureWord).most_common(10)
wordcount
[('非常', 65),
('不错', 48),
('手机', 45),
('好好', 33),
('发货', 32),
('很快', 32),
('喜欢', 31),
('正品', 30),
('速度', 29),
('物流', 29)]
cnt_dict = {word[0]:word[1] for word in wordcount}
cnt_dict
{'非常': 65,
'不错': 48,
'手机': 45,
'好好': 33,
'发货': 32,
'很快': 32,
'喜欢': 31,
'正品': 30,
'速度': 29,
'物流': 29}
list(cnt_dict.keys())
['非常', '不错', '手机', '好好', '发货', '很快', '喜欢', '正品', '速度', '物流']
list(cnt_dict.values())
[65, 48, 45, 33, 32, 32, 31, 30, 29, 29]
使用pyecharts绘制可视化大屏图展示如下:
这里pyecharts还不会用,暂且matplotlib绘制!
5.1 绘制柱状图
plt.barh(list(cnt_dict.keys()), list(cnt_dict.values()))
for y, x in enumerate(list(cnt_dict.values())): # 显示对应数据
plt.text(x+0.3, y-0.2, "%s" %x, fontsize=14)
plt.show()

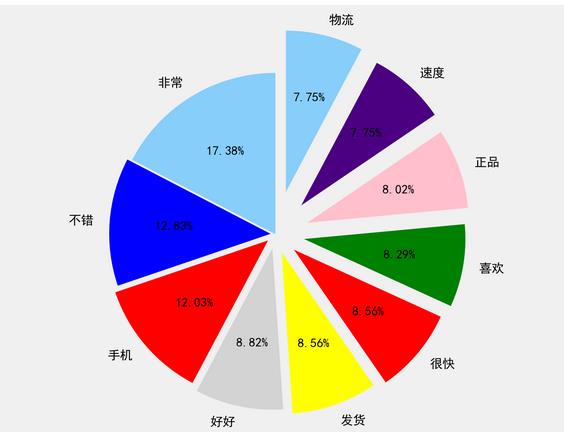
5.2 绘制饼图
# 绘制饼图
plt.figure(figsize=(20,8), dpi=200) #调节图形大小
colors_list = ['lightskyblue','blue','red','lightgrey','yellow','red','green','pink','indigo','lightskyblue']
items_count = len(list(cnt_dict.keys()))
colors = colors_list[:items_count]
explode=[0]*items_count #将某一块分割出来,值越大分割出来的间隙越大
for i in range(items_count):
explode[i]=i*0.03
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)
# plt.rcParams['font.sans-serif'] = ['SongTi SC'] # ios系统
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
# patches饼图的返回值,texts1饼图外label的文本,texts2饼图内部的文本
patches,text1,text2 = plt.pie(list(cnt_dict.values()),
explode=explode,
labels= list(cnt_dict.keys()),
colors=colors,
autopct = '%3.2f%%', #数值保留固定小数位
shadow=False,#无阴影设置
startangle=90,#逆时针起始角度设置
pctdistance=0.6)#数值距圆心半径倍数距离
plt.axis('equal') # x,y轴刻度设置一致,保证饼图为圆形
plt.show()
6. 评分可视化
我们使用pandas提取手机评分数据以及频率,数据可视化展示如下:
从图中可以非常直观的看出苹果12的受欢迎程度。
data.head()
| 用户名称 | 会员等级 | 手机评分 | 评论时间 | 手机颜色 | 手机内存 | 评论 | |
|---|---|---|---|---|---|---|---|
| 0 | P****g | 5 | 5 | 2021-05-14 | 紫色 | 128G | 是正品 非常好用 终于把旧手机换了 |
| 1 | 用****8 | 6 | 5 | 2021-05-26 | 白色 | 256G | 非常满意的一次购物,顺丰发货,拆机验货是全新未激活的,用一段时间我再来追评哈 |
| 2 | 用****9 | 5 | 5 | 2021-08-09 | 白色(仅128G返红包) | 128G | 很好的购物体验。 |
| 3 | 利**** | 5 | 5 | 2021-06-21 | 返红包黑色-1 | 128G | 非常的满意,这次活动做的很给力,优惠力度特别大,看中这款好久了,这次终于入手,查了序列号正品... |
| 4 | ༣****° | 6 | 5 | 2021-06-06 | 白色 | 64G | 到货了,速度特别快,而且这次活动价格也特别的给力,买东西,上严选,放心靠谱,好评! |
# 划分评分区间,0-1,1-2,2-5,根据评分划分等级
pd.cut(data['手机评分'], [0, 1, 2, 5], labels=['差评', '中评', '好评'])
0 好评
1 好评
2 好评
3 好评
4 好评
..
327 好评
328 好评
329 好评
330 好评
331 好评
Name: 手机评分, Length: 320, dtype: category
Categories (3, object): ['差评' < '中评' < '好评']
data['手机评价'] = pd.cut(data['手机评分'], [0, 1, 2, 5], labels=['差评', '中评', '好评'])
data.head()
| 用户名称 | 会员等级 | 手机评分 | 评论时间 | 手机颜色 | 手机内存 | 评论 | 手机评价 | |
|---|---|---|---|---|---|---|---|---|
| 0 | P****g | 5 | 5 | 2021-05-14 | 紫色 | 128G | 是正品 非常好用 终于把旧手机换了 | 好评 |
| 1 | 用****8 | 6 | 5 | 2021-05-26 | 白色 | 256G | 非常满意的一次购物,顺丰发货,拆机验货是全新未激活的,用一段时间我再来追评哈 | 好评 |
| 2 | 用****9 | 5 | 5 | 2021-08-09 | 白色(仅128G返红包) | 128G | 很好的购物体验。 | 好评 |
| 3 | 利**** | 5 | 5 | 2021-06-21 | 返红包黑色-1 | 128G | 非常的满意,这次活动做的很给力,优惠力度特别大,看中这款好久了,这次终于入手,查了序列号正品... | 好评 |
| 4 | ༣****° | 6 | 5 | 2021-06-06 | 白色 | 64G | 到货了,速度特别快,而且这次活动价格也特别的给力,买东西,上严选,放心靠谱,好评! | 好评 |
# 统计数量
starts = data['手机评价'].value_counts()
starts
好评 308
差评 9
中评 2
Name: 手机评价, dtype: int64
start1 = starts.index.tolist() # 人气值分类
starts.tolist()
[308, 9, 2]
start2 = starts.tolist()
6.1 柱状图
plt.bar(start1, start2)
for x, y in enumerate(start2): # 显示对应数据
plt.text(x-0.1, y+6, "%s" %y, fontsize=18)
plt.show()

6.2 环形图
fig, ax = plt.subplots(figsize=(15, 8), subplot_kw=dict(aspect="equal"))
# 类别名
recipe = start1
data1 = start2
# startangle 设置方向
wedges, texts = ax.pie(data1, wedgeprops=dict(width=0.5), startangle=-40)
# 每一类别说明框
# boxstyle框的类型,fc填充颜色,ec边框颜色,lw边框宽度
bbox_props = dict(boxstyle="square,pad=0.3", fc='white', ec="black", lw=0.72)
# 设置框引出方式
kw = dict(arrowprops=dict(arrowstyle="-"),
bbox=bbox_props, zorder=0, va="center")
# 添加标签
for i, p in enumerate(wedges):
ang = (p.theta2 - p.theta1)/2. + p.theta1
y = np.sin(np.deg2rad(ang))
x = np.cos(np.deg2rad(ang))
# 设置方向
horizontalalignment = {-1: "right", 1: "left"}[int(np.sign(x))]
connectionstyle = "angle,angleA=0,angleB={}".format(ang)
kw["arrowprops"].update({"connectionstyle": connectionstyle})
# 设置标注
ax.annotate(recipe[i], xy=(x, y), xytext=(1.35*np.sign(x), 1.4*y),
horizontalalignment=horizontalalignment,color='black', **kw)
ax.set_title("苹果12评价环形图")
plt.show()

6.3 折线图
plt.plot(start2, 'or-', alpha=0.6)
# 折线图显示数据text()
for x, y in enumerate(start2): # l对应每一个数据的x轴坐标,price对应y轴坐标
plt.text(x, y+7, "%s" %y, fontsize=15, c='b')
plt.show()

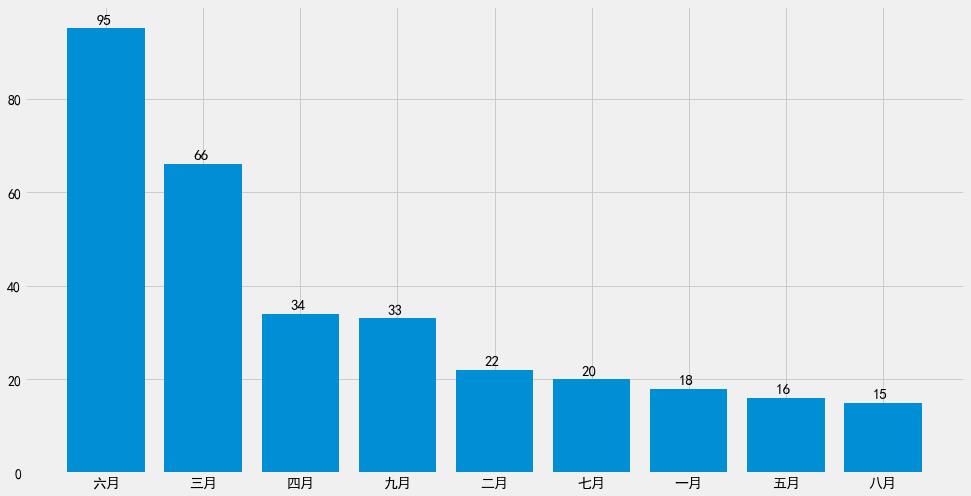
7. 购机时间可视化
我们爬取的数据都是在2021年,接下来我们提取事件中的月份数据,
来看看大家普遍的下单时间集中在哪几个月份?
# 获取时间月份
data['评论时间'].tail()
327 2021-01-21
328 2021-01-20
329 2021-01-09
330 2021-01-06
331 2021-06-18
Name: 评论时间, dtype: object
data['评论时间'].map(lambda x: x.split('-')[1])
0 05
1 05
2 08
3 06
4 06
..
327 01
328 01
329 01
330 01
331 06
Name: 评论时间, Length: 320, dtype: object
data['评论月份'] = data['评论时间'].map(lambda x: x.split('-')[1])
# 数据分类
pd.cut(data['评论月份'], ['00', '01', '02', '03', '04', '05', '06', '07', '08', '09'], labels=['一月', '二月', '三月', '四月', '五月', '六月', '七月', '八月', '九月'])
0 五月
1 五月
2 八月
3 六月
4 六月
..
327 一月
328 一月
329 一月
330 一月
331 六月
Name: 评论月份, Length: 320, dtype: category
Categories (9, object): ['一月' < '二月' < '三月' < '四月' ... '六月' < '七月' < '八月' < '九月']
data['评论月份'] = pd.cut(data['评论月份'], ['00', '01', '02', '03', '04', '05', '06', '07', '08', '09'], labels=['一月', '二月', '三月', '四月', '五月', '六月', '七月', '八月', '九月'])
# 统计数据
data['评论月份'].value_counts()
六月 95
三月 66
四月 34
九月 33
二月 22
七月 20
一月 18
五月 16
八月 15
Name: 评论月份, dtype: int64
date = data['评论月份'].value_counts()
date.index.to_list()
['六月', '三月', '四月', '九月', '二月', '七月', '一月', '五月', '八月']
date.to_list()
[95, 66, 34, 33, 22, 20, 18, 16, 15]
date1 = date.index.to_list() # 月份分类
date2 = date.to_list() # 月份对应的数据
7.1 绘制柱状图
plt.figure(figsize=(15, 8))
plt.bar(date1, date2)
for x, y in enumerate(date2): # 显示对应数据
plt.text(x-0.1, y+1, "%s" %y, fontsize=15)
plt.show()
7.2 绘制环形图
fig, ax = plt.subplots(figsize=(15, 8), subplot_kw=dict(aspect="equal"))
# 类别名
recipe = date1
data1 = date2
# startangle 设置方向
wedges, texts = ax.pie(data1, wedgeprops=dict(width=0.5), startangle=-40)
# 每一类别说明框
# boxstyle框的类型,fc填充颜色,ec边框颜色,lw边框宽度
bbox_props = dict(boxstyle="square,pad=0.3", fc='white', ec="black", lw=0.72)
# 设置框引出方式
kw = dict(arrowprops=dict(arrowstyle="-"),
bbox=bbox_props, zorder=0以上是关于十三香吗?网易严选-苹果12商品评论数据可视化分析的主要内容,如果未能解决你的问题,请参考以下文章
用 Python 爬取网易严选妹子内衣信息,探究妹纸们的偏好