N日一篇——二叉树
Posted 从零开始的智障生活
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了N日一篇——二叉树相关的知识,希望对你有一定的参考价值。
目录
三、实现二叉树+先序遍历+中序遍历+后序遍历+用栈实现先序遍历+用栈实现中序遍历+用栈实现后序遍历+层次遍历+用队列实现层次遍历+用中序遍历和先序遍历确认二叉树

一、用接口实现二叉树的抽象数据类型
import java.util.List;
public interface BinNode {
public Object getElement(); // 返回结点元素
public void setElement(Object ob); // 设置结点元素
public BinNode getLeft(); // 返回左孩子
public void setLeft(BinNode leftnode);// 设置左孩子
public BinNode getRight(); // 返回右孩子
public void setRight(BinNode rightnode); // 设置右孩子
public boolean isLeaf(); // 判断是否叶子结点
// public void preordertraversal(BinNode root);// 先序遍历
// public void preordertraversalwithStack(BinNode root);//栈实现非递归先序遍历
// public void inordertraversal(BinNode node);// 中序遍历
// public void inordertraversalwithStack(BinNode root);//栈实现非递归中序遍历
// public void postordertraversal(BinNode node);// 后序遍历
// public void postordertraversalwithStack(BinNode root);//栈实现非递归后续遍历
// public void leveltraversalwithQueue(BinNode root);// 用队列实现层次遍历
// // 用先序遍历和中序遍历序列创建二叉树。
// public BinNodeImpl createBinTreebyPreandInOrder(List pre,List in);
}二、辅助类
栈(自己编辑的)
// 把索引为0的位置作为栈尾,即栈中所有数据都是有效数据,属于不带头结点,即没有一个无效数据点
// 对于顺序栈而言,不会有线性表的插入删除操作需要花费O(n)的时间复杂度的问题,因为只会在栈顶插入
public class SStackwithoutHead implements SequentialStack{
private final static int DEFAULTSIZE = 10;
private int size; // 栈容量
private Object[] stack;
private int topIndex; // 栈顶位置,从0索引,同时topIndex+1表示栈大小
public SStackwithoutHead() {
setup(DEFAULTSIZE);
}
public SStackwithoutHead(int size) {
setup(size);
}
@Override
public void setup(int sz) { // 初始化链式表
size = sz;
topIndex = -1; // 不带头结点,所以初始化为topIndex为-1
stack = new Object[sz];
}
@Override
public void push(Object ob) {
if(topIndex<size)
stack[++topIndex] = ob;// 先执行++topIndex
}
@Override
public Object pop() {
if(!isEmpty())
return stack[topIndex--];// 先执行stack[topIndex]
else
return null;
}
@Override
public Object topValue() {
if(!isEmpty())
return stack[topIndex];
else
return null;
}
@Override
public boolean isEmpty() {
if(topIndex<0)
return true;
else
return false;
}
}队列(自己编辑的)
// 带头结点的队列
// 这里用头结点来避免逻辑循环数组中队满和队空问题
public class SQueuewithHead implements SequentialQueue{
private static final int DEFAULTSIZE = 4;
private int front;// 队首
private int rear;// 队尾
private int size;// 队列容量
private Object listArray[];// 队列
public SQueuewithHead() {
setup(DEFAULTSIZE);
}
public SQueuewithHead(int sz) {
setup(sz);
}
@Override
public void setup(int sz) {
size = sz+1;// 带一个无效数据头结点
front = 0;
rear = 0;
listArray = new Object[size];
}
@Override
public void enQueue(Object ob) {
// 增加一个新元素到队尾,
// 如果队尾的当前索引是size-1,即数组最后一个元素,那么下一个元素应当是在索引为0这个位置,
// 那么可以用(++rear)%size
// System.out.println(front+" \\t "+rear);
if(front!=(rear+2)%size)// 判断非队满
listArray[(++rear)%size] = ob;
}
@Override
public Object deQueue() {
if(!isEmpty())return listArray[(++front)%size];// 出队一个队头元素
return null;
}
@Override
public Object frontObject() {
if(!isEmpty())return listArray[(front+1)%size];// 返回一个队头元素
return null;
}
public Object rearObject() {
if(!isEmpty())return listArray[rear];// 返回一个队尾元素
return null;
}
@Override
public boolean isEmpty() {
if(front == rear) return true;
return false;
}
}
ArrayList(JavaAPI的)
三、实现二叉树+先序遍历+中序遍历+后序遍历+用栈实现先序遍历+用栈实现中序遍历+用栈实现后序遍历+层次遍历+用队列实现层次遍历+用中序遍历和先序遍历确认二叉树
import java.util.List;
import com.zyx.queue.sequentialqueue.SQueuewithHead;
import com.zyx.stack.squentialstack.SStackwithoutHead;
public class BinNodeImpl implements BinNode{
private Object element;
private BinNode left;
private BinNode right;
public BinNodeImpl() {
element = null;
left = null;
right =null;
}
public BinNodeImpl(Object ob) {
element = ob;
left = null;
right = null;
}
public BinNodeImpl(Object ob,BinNode leftnode,BinNode rightnode) {
element = ob;
left = leftnode;
right = rightnode;
}
@Override
public Object getElement() {
return element;
}
@Override
public void setElement(Object ob) {
element = ob;
}
@Override
public BinNode getLeft() {
return left;
}
@Override
public void setLeft(BinNode leftnode) {
left = leftnode;
}
@Override
public BinNode getRight() {
return right;
}
@Override
public void setRight(BinNode rightnode) {
right = rightnode;
}
@Override
public boolean isLeaf() {
return (left==null)&&(right==null);
}
public void visit(Object ob) {
System.out.print(ob);
}
// 先序遍历,先访问根,再依次遍历左子树,再遍历右子树
public void preordertraversal(BinNode root) {
if(root!=null) {
visit(root.getElement());
preordertraversal(root.getLeft());
preordertraversal(root.getRight());
}
}
//栈实现非递归先序遍历
public void preordertraversalwithStack(BinNode root){
SStackwithoutHead stack = new SStackwithoutHead();
BinNode node = root;
// 当二叉树非空,压栈二叉树,并访问当前节点,开始遍历并访问左子树
while(node!=null || !stack.isEmpty()) {
if(node!=null) {
stack.push(node);// 压栈
visit(node.getElement());// 访问当前节点
node = node.getLeft();// 开始向左遍历
}
else {//当左子树为空,出栈当前节点,并遍历右子树,如果右子树非空,压栈并访问右子树
node = (BinNode) stack.pop();
node = node.getRight();
}
}
}
// 中序遍历,先遍历左子树,访问结点,再依次遍历右子树
public void inordertraversal(BinNode node) {
if(node!=null) {
inordertraversal(node.getLeft());
visit(node.getElement());
inordertraversal(node.getRight());
}
}
// 用栈实现非递归中序遍历。
public void inordertraversalwithStack(BinNode root) {
// 新建一个栈
SStackwithoutHead stack = new SStackwithoutHead(10);
BinNode node = root;// 指向下一个可能的栈顶元素
while(node!=null || !stack.isEmpty()) {
// 当二叉树非空,压栈二叉树,优先遍历左子树,即压栈左子树
if (node!=null) {
stack.push(node); // 压栈左子树
node = node.getLeft();
}
// 当左子树为空,出栈并访问当前节点,遍历右子树,如果右子树非空,压栈右子树
else {
// 出栈并访问该节点
node = (BinNode) stack.pop();// 当左子树为空,出栈该节点
visit(node.getElement());// 访问该节点
node = node.getRight();// 遍历右子树
}
}
}
// 后续遍历,先遍历左子树,再遍历右子树,最后访问根
public void postordertraversal(BinNode node) {
if(node!=null) {
postordertraversal(node.getLeft());
postordertraversal(node.getRight());
visit(node.getElement());
}
}
// 用栈实现非递归后续遍历
// 这个比较复杂,如何在遍历到右子树为空后,然后出栈,出栈的可能是其左子树,也可能是当前节点,
// 如何保证出栈以后,不会被再次压入?
// 只要确保,四种情形出栈:一左空或右空时;二:左空右已出栈;三右空左已出栈
// 对于栈而言,同一个元素不会被入栈两次。
// 1.当结点第一次入栈时,设定其值为0,
// 2.遍历左子树,
// 3.当左子树为空或遍历结束时,将栈顶(分叉点)值设为1;
// 4.遍历右子树,
// 5.若右子树根节点非空,跳到步骤1;
// 6.若右子树为空,栈顶值一定是1,开始进行出栈操作,直道最上层的分叉点,意味着这个分叉点的左子树遍历结束,
// 7.跳转到3
public void postordertraversalwithStack(BinNode root) {
SStackwithoutHead stack1 = new SStackwithoutHead();
SStackwithoutHead stack2 = new SStackwithoutHead();
BinNode node = root;
while(node != null || !stack1.isEmpty()) {
while(node!=null) {
stack1.push(node);
stack2.push(0);
node = node.getLeft();
}
while(!stack1.isEmpty() && (int)stack2.topValue()==1) {
visit(((BinNode) stack1.pop()).getElement());
stack2.pop();
}
if(!stack1.isEmpty()) {
stack2.pop();
stack2.push(1);
node =((BinNode) stack1.topValue()).getRight();
}
}
}
// 层次遍历:从第一层开始由左向右遍历,可以用一个队列来实现,将每一层的最左边作为队头,最右边作为队尾,队头先出队
// 第一层:既是队头又是队尾,入队又出队
// 1.如果
public void leveltraversalwithQueue(BinNode root) {
BinNode node = root;
SQueuewithHead queue = new SQueuewithHead();
queue.enQueue(node);
while(!queue.isEmpty()) {
node = (BinNode) queue.deQueue();
visit(node.getElement());
if(node.getLeft()!=null) {
queue.enQueue(node.getLeft());
}
if(node.getRight()!=null) {
queue.enQueue(node.getRight());
}
}
}
/**
* 由一种遍历序列无法构造唯一的二叉树
* 1)(后)先序遍历和中序遍历可以确定一棵二叉树;
* 2)后序遍历序列和先序遍历序列不可以确定一棵二叉树;
* 3)层次遍历序列和中序遍历序列也可以构造出一个二叉树。
*/
/**
* 在先序遍历中,第一个结点是根节点
* 在中序遍历中,根节点将二叉树分成两部分,左边是左子树,右边是右子树
* 对于中序遍历的左子树,先序遍历会有一个匹配的串,而先序遍历的串的第一个结点就是左子树的根节点,则右边就是右子树的串,
* 我们不需要匹配串,只要通过长度来匹配就行了。如:长度为n的中序遍历中,根节点索引为j,左子树:0->j-1,右子树:j+1->n-1
* 则左子树大小为j,右子树大小为n-j-1则先序遍历中左子树的位置在1->j,右子树的位置在j+1->n-j-1
* 如果左子树非空,则先序遍历中根节点后面的结点一定是左子树的根节点
* 如果右子树非空,则先序遍历中左子树遍历结束后的那个结点一定是右子树的根节点
* 如果左子树为空且右子树为空,则此结点,若在左边则是父节点的左子节点,若在右边则是父节点右子节点。
* 然后递归过程
*/
/**
*
* 当中序遍历序列为空时,结束遍历
* 当中序遍历序列长度为1时,返回结果。
* 当中序遍历序列长度为2时,则必定至少有一个是父节点,一个是子节点,在左为左,在右为右
*
*/
public BinNodeImpl createBinTreebyPreandInOrder(List pre,List in) {
// 当中序遍历序列为空时,结束遍历
if(in.isEmpty()) {
return null;
}
// 当中序遍历序列长度为1时,返回结果。
if(in.size()==1) {
return (new BinNodeImpl(in.get(0)));
}
BinNodeImpl node=new BinNodeImpl(pre.get(0));// 获取根节点
BinNodeImpl ltemp;
BinNodeImpl rtemp;
if(in.size()>1) {
int j = 0;
// 找到中序遍历根节点,索引为j,左子树:0->j-1,右子树j+1->in.size()-1
// 先序遍历,左子树:1->j,右子树:j+1->pre.size()-1
while (in.get(j)!=pre.get(0)) {
j++;
}
ltemp = createBinTreebyPreandInOrder(pre.subList(1,j+1),in.subList(0,j));
rtemp = createBinTreebyPreandInOrder(pre.subList(j+1,pre.size()),in.subList(j+1,in.size()));
node.setLeft(ltemp);
node.setRight(rtemp);
return node;
}
return null;
}
public BinNode createBinTreebyPostandInOrder(List pre,List list) {
return (new BinNodeImpl());
}
}
四、测试结果
import java.util.ArrayList;
public class TestBinNode{
public static void main(String[] args) {
BinNodeImpl root =new BinNodeImpl('A');
root.setLeft(new BinNodeImpl('B'));
root.getLeft().setRight(new BinNodeImpl('D'));
root.setRight(new BinNodeImpl('C'));
root.getRight().setLeft(new BinNodeImpl('E'));
root.getRight().setRight(new BinNodeImpl('F'));
root.getRight().getLeft().setLeft(new BinNodeImpl('G'));
root.getRight().getRight().setLeft(new BinNodeImpl('H'));
root.getRight().getRight().setRight(new BinNodeImpl('I'));
System.out.println("\\n中序遍历");
root.inordertraversal(root);
System.out.println("\\n用栈实现非递归中序遍历");
root.inordertraversalwithStack(root);
System.out.println("\\n后续遍历");
root.postordertraversal(root);
System.out.println("\\n用栈实现非递归后序遍历");
root.postordertraversalwithStack(root);
System.out.println("\\n先序遍历");
root.preordertraversal(root);
System.out.println("\\n用栈实现非递归中序遍历");
root.preordertraversalwithStack(root);
System.out.println("\\n用队列实现层次遍历");
root.leveltraversalwithQueue(root);
@SuppressWarnings("rawtypes")
ArrayList pre = new ArrayList();
ArrayList in = new ArrayList();
char pres[] = {'A','B','D','C','E','G','F','H','I'};
char ins[] = {'B','D','A','G','E','C','H','F','I'};
for(char c:pres) pre.add(c);
for(char c:ins) in.add(c);
System.out.println("\\n用先序遍历+中序遍历,确定二叉树。");
BinNodeImpl node = (new BinNodeImpl()).createBinTreebyPreandInOrder(pre, in);
System.out.println("\\n先序");
root.preordertraversal(node);
System.out.println("\\n中续");
root.inordertraversal(node);
System.out.println("\\n后续");
root.postordertraversal(node);
System.out.println("\\n层次");
root.leveltraversalwithQueue(node);
}
}
运行结果:
中序遍历
BDAGECHFI
用栈实现非递归中序遍历
BDAGECHFI
后续遍历
DBGEHIFCA
用栈实现非递归后序遍历
DBGEHIFCA
先序遍历
ABDCEGFHI
用栈实现非递归中序遍历
ABDCEGFHI
用队列实现层次遍历
ABCDEFGHI
用先序遍历+中序遍历,确定二叉树。先序
ABDCEGFHI
中续
BDAGECHFI
后续
DBGEHIFCA
层次
ABCDEFGHI
五、二叉树的应用
有一些特殊的应用(如线索二叉树)会增加一个指向父节点的指针,以便于向上搜索。增加一个父指针有点像在双链表中增加的指向前一节点的指针prev。实际上,父指针通常是不必要的,并且增加了许多结构性开销。
在利用指针实现的二叉树中,叶结点与分支结点是否使用相同的类定义十分重要。有一些应用只需要用叶节点存储数据。还有一些应用要求分支结点与叶节点存储不同类型的数据。根据二叉树的定义,只有分支结点有非空子节点。因此,分别定义分支结点与叶结点将节省存储空间。
如表达式二叉树。如下图表示的 。页结点与分支结点是不同的,分支节点存储元素数目很少的操作符集合中的一个操作符,因此分支结点可以存储这个操作符的代码或者用一个字符存储其图形符号。叶结点则存储不同的变量或数值,所以叶节点必须有足够大的数据区来存储各种可能的值。同时,叶节点不必存储子节点指针(因为其就算有,也都是空指针)。
。页结点与分支结点是不同的,分支节点存储元素数目很少的操作符集合中的一个操作符,因此分支结点可以存储这个操作符的代码或者用一个字符存储其图形符号。叶结点则存储不同的变量或数值,所以叶节点必须有足够大的数据区来存储各种可能的值。同时,叶节点不必存储子节点指针(因为其就算有,也都是空指针)。
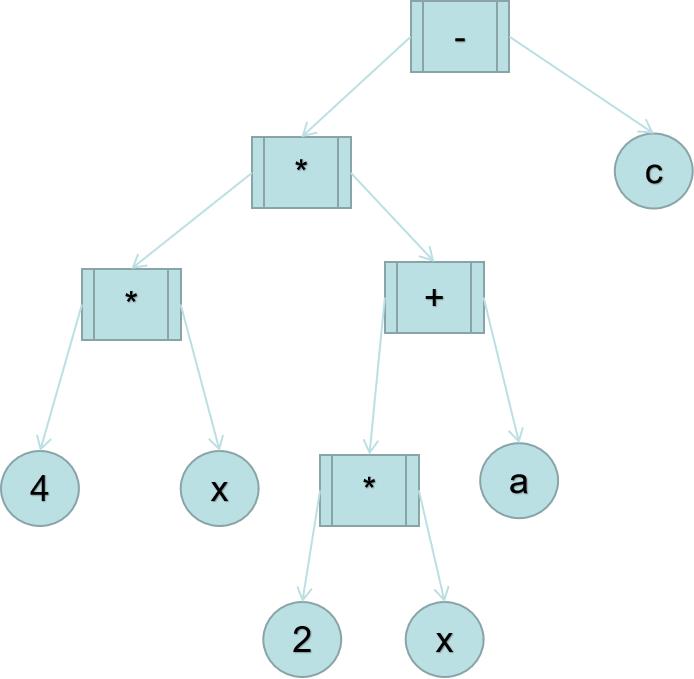
分支结点
public class BranchNode implements BinNode{
private BinNode left; // 左子节点
private BinNode right;// 右子节点
private Character opx; // 操作符
public BranchNode(Character operator,BinNode leftNode,BinNode rightNode) {
opx = operator;left=leftNode;right=rightNode;
}
@Override
public Object getElement() {return opx;}
@Override
public void setElement(Object ob) {opx=(Character)ob;}
@Override
public BinNode getLeft() {return left;}
@Override
public void setLeft(BinNode leftnode) {left = leftnode;}
@Override
public BinNode getRight() {return right;}
@Override
public void setRight(BinNode rightnode) {}
@Override
public boolean isLeaf() {return false;}
}叶节点
public class LeafNode implements BinNode{
public String var;
public LeafNode(String val) {
var=val;
}
@Override
public Object getElement() {return var;}
@Override
public void setElement(Object ob) {var=(String)ob;}
@Override
public BinNode getLeft() {return null;}
@Override
public void setLeft(BinNode leftnode) {}
@Override
public BinNode getRight() {return null;}
@Override
public void setRight(BinNode rightnode) {}
@Override
public boolean isLeaf() {return true;}
}测试遍历:用中序遍历可以形式上实现运算。
public class TestBranchandLeaf {
public static void traverse(BinNode node) {
if(node==null)return;
// 通过node.isLeaf()判断结点的类型,从而给出真正的结点类型。
if(node.isLeaf())System.out.print(node.getElement());
else {
traverse(node.getLeft());
System.out.print(node.getElement());
traverse(node.getRight());
}
}
public static void main(String[] args) {
LeafNode leaf1 = new LeafNode("4");
LeafNode leaf2 = new LeafNode("x");
BranchNode node1 = new BranchNode('*', leaf1, leaf2);
LeafNode leaf3 = new LeafNode("2");
LeafNode leaf4 = new LeafNode("x");
BranchNode node2 = new BranchNode('*', leaf3, leaf4);
LeafNode leaf5 = new LeafNode("a");
BranchNode node3 = new BranchNode('+',node2, leaf5);
BranchNode node4 = new BranchNode('*', node1, node3);
LeafNode leaf6 = new LeafNode("c");
BranchNode node5 = new BranchNode('-', node4, leaf6);
traverse(node5);
}
}运行结果:
4*x*2*x+a-c
以上是关于N日一篇——二叉树的主要内容,如果未能解决你的问题,请参考以下文章