Spring Cloud Alibaba从入门到精通!
Posted Java小叮当
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring Cloud Alibaba从入门到精通!相关的知识,希望对你有一定的参考价值。
前台
一. 课程介绍
1.1 课程导学
-
什么是SpringCloudAlibaba?
- 阿里巴巴结合自身微服务实践,开源的微服务全家桶
- 在Spring Cloud项目中孵化,很可能成为Spring Cloud第二代标准的实现
- 在业界广泛使用,已有很多成功案例
-
Spring Cloud Alibaba真实应用场景
- 大型复杂的系统,例如大型电商系统
- 高并发系统,例如大型门户,秒杀系统
- 需求不明确,且变更很快的系统,例如初创公司业务系统
-
Spring Cloud Alibaba与Spring Cloud
- 简单来说,SpringCloud Alibaba是SpringCloud的子项目,它是SpringCloud第二代的实现;
- 图示如下:

- 总结来说:
- 组件性能更强
- 良好的可视化界面
- 搭建简单,学习曲线低
- 文档丰富并且是中文
-
阅读本博客你能学到什么?
- SpringCloud Alibaba核心组件的用法及实现原理
- SpringCloud Alibaba结合微信小程序,从“0”学习真正开发中的使用
- 实际工作如何避免踩坑,正确的思考问题方式
- SpringCloud Alibaba的进阶:代码的优化和改善,微服务监控
-
课程进阶会讲那些内容?

-
课程思路:
- 分析并拆解微服务
- 编写代码
- 分析现有架构问题
- 引入微服务组件
- 优化重构
-
SpringCloud Alibaba的重要组件精讲,如图所示:



1.2 项目环境搭建
-
课上用到的软件
- JDK8
- mysql
- Maven安装与配置
- IDEA及一些快捷键
-
安装Maven:
- 我们可以用IDEA自带的Maven,也可以自行下载安装Maven使用
-
安装JDK和MySQL
- 我们可以通过网上搜索相关教程安装
二. SpringBoot基础
2.1 本章概述

2.2 Spring Boot是什么?能做什么?
- 是什么?
- SpringBoot是一个快速开发的脚手架
- 作用?
- 快速创建独立的、生产级的机遇Spring的应用程序
- 特性?
- 无需部署WAR文件
- 提供starter简化配置
- 尽可能自动配置Spring以及第三方库
- 提供“生产就绪”功能,例如指标、健康检查、外部配置等
- 无代码生成&无XML
2.3 编写第一个SpringBoot应用
- 需求:
- 整合Spring MVC
- /test路径,我们成为“端点”
- 使用Spring Initializr快速创建SpringBoot 应用
- 点击Create New Project -> Spring Initializr -> 配置JDK-> 选择Default-> 点击Next,如图所示:

- 根据自己实际配置好Group及Artifact,Type选Maven(若为Gradle项目也可以选Gradle),其他根据实际配置,如图所示:

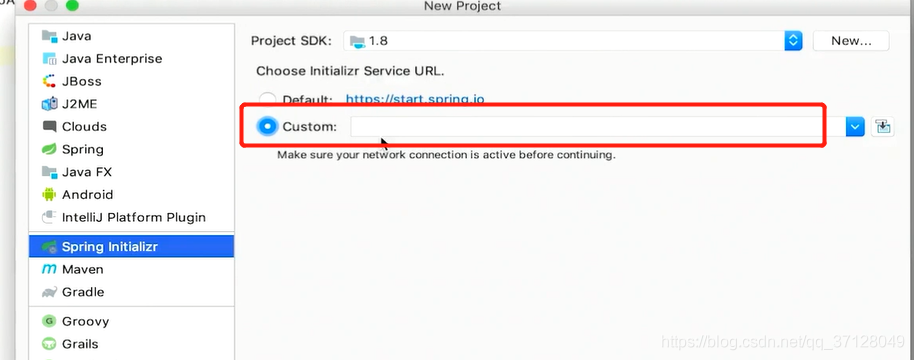
- 选择需要的依赖,同时选择SpringBoot版本,其中如图所示的,除了2.1.5外,上方的都不是正式版,所以我们选择版本为2.1.5,如图所示:

我们可以自己部署一个Costom,结合官方文档和网上文章,当为内王环境时,自己就可以部署一个,如图所示:
复制代码
- 创建接口并启动访问,如图所示:

通过启动启动类,直接就可以运行项目,我们不需要打war包再放到tomcat中了;
2.4 Spring Boot应用组成分析
- 依赖:

- 注解:

- 配置:

- 静态文件:
- resource/static目录
- 模板引擎:
- 支持:Freemarker、Groovy、Thymeleaf、Mustache
- 现在逐渐前后端分离开发,模板引擎用的越来越少了
- resource/templates 目录
2.5 SpringBoot 开发三板斧
- 加依赖(整合什么,就加什么的依赖)
- 官方提供的starter格式: spring-boot-starter-xxx
- 非官方提供的starter格式: xxx-spring-boot-starter
- 写注解:
- 某些需要用到注解的,需要在启动类上或者指定的地方上加上注解
- 写配置:
- 可以是Bean类型的配置类
- 也可以是在resource下的yml&properties&等加配置
2.6 必会 Spring Boot Actuator
| 是什么? |
|---|
- 如何整合?
-
加依赖: org.springframework.boot spring-boot-starter-actuator 复制代码
-
直接启动,访问:ip:端口/actuator
- health: 健康检查
-
我们在application.yml中配置,让健康检查更加详细: management.endpoint.health.show-details=always 复制代码
-
如图所示:
-
- health: 健康检查
-

- status取值:
- UP: 正常
- DOWN: 遇到了问题,不正常
- OUT\\_OF\\_SERVICE: 资源未在使用,或者不该去使用
- UNKNOWN: 不知道
- info:不是用于监控的,我们一般用于描述应用,使用key-value形式去写,如图所示:

- 展示内容如图:

- 提供的监控端点如图(此处列的是常用的,可以去官方文档查看全部的):

- 激活所有的Acttuator端点,在application.yml中添加:

- 激活指定的端点: management.endpoints.web.exposure.include=metrics,health 复制代码
多个以逗号隔开
2.7 必会 Spring Boot 配置管理
-
支持的配置格式:
- application.yml
- application.yaml
- application.properties
properties中的值若为 * ,在yml中则需要改为 “*” yml>yaml>properties 执行顺序,如果有重复内容,则properties为最终的结果
-
环境变量:
- 以 ${xxx} 形式标记变量名,在IDEA中可在 Environment variables 中添加环境变量,如图所示:


- 外部配置文件
- spring-boot能够读取外部的配置文件,将其配置文件放同一路经下即可,且外部的配置文件优先级更高,如图所示:

- 命令行参数:
-
命令行中: java -jar xxx.jar --server.port=8081 复制代码
-
IDEA中:
-

2.8 必会 Profile
- 如何实现不同环境不同配置?
- 方式一:
- 配置如图:
- 方式一:

- 在IDEA中指定要启动的环境:

- 不指定环境配置的时候,就只执行公共部分的配置,我们可以配置默认的环境配置方案,如图所示:

- 方式二:
- 我们也可以创建出多个profile配置文件,然后在配置的时候选择指定的配置文件,如图所示:

2.9 本章总结
- 使用Spring Initialize快速创建应用
- 应用组成分析
- 三板斧
- Actuator
- 配置管理
- Profile
三. 微服务的拆分与编写
3.1 本章概述

3.2 单体应用
- 什么是单体架构?
- 一个归档包(例如War包)包含所有功能的应用程序,我们通常称为单体应用。而架构单体应用的方法论,就是单体应用架构
- 单体架构的优点
- 架构简单
- 开发、测试、部署方便
- 单体架构的缺点:
- 复杂性高
- 部署慢、频率低
- 扩展能力受限(比如IO操作多的,和CPU操作多的,不能物尽其用)
- 阻碍技术创新(更换技术栈不方便)
3.3 微服务
-
微服务定义
- 微服务架构风格是一种将一个单一应用程序开发为一组小型服务的方法,每个服务运行在自己的进程中,服务间通信采用轻量级通信机制(通常用HTTP资源API)。这些服务围绕业务能力构建并且可通过全自动和部署机制独立部署。这些服务共用一个最小型的集中式的管理,服务可用不同的语言开发,使用不同的数据存储技术;
-
微服务的特性:
- 每个微服务可独立运行在自己的进程里
- 一系列独立运行的微服务共同构建起整个系统
- 每个服务为独立的业务开发,一个微服务只关注某个特定的功能,例如订单管理、用户管理等
- 可使用不同的语言与存储技术(契合项目情况与团队实力)
- 微服务之间通过轻量的通信机制进行通信,例如通过REST API进行调用;
- 全自动的部署机制
-
微服务架构图:

-
微服务的优点:
- 单个服务更易于开发、维护
- 单个微服务启动较快
- 局部修改容易部署
- 技术栈不受限
- 按需伸缩
-
微服务的缺点:
- 运维要求高
- 分布式固有的复杂性
- 重复劳动
-
微服务的适用场景
- 大型、复杂的项目
- 服务压力大
- 变更较快的服务
-
微服务不适用的场景
- 业务稳定
- 迭代周期长
3.4 项目效果演示
xxx此处省略
3.5 微服务拆分
- 领域驱动设计(Domain Driven Design)
- 面向对象(by name./ by berb.)根据名词或动词拆分
- 职责划分
- 通用性划分
- 合适的粒度
- 良好地满足业务
- 幸福感
- 增量迭代
- 持续进化
3.6 项目架构图

3.7 数据库设计
- 建模,如图所示:

- 然后导出,将其创建为实际的MySQL表
3.8 API文档
- 写Api文档,提前定义好要写哪些功能需求
- 如图所示:

3.9 如何创建小程序
- 注册账号: https//mp.weixin.qq.com
- 填写信息,申请创建小程序

- 在激活邮箱中点击跳转链接,完善补全如图信息:

- 进入小程序首页,我们可以配置小程序信息等,这里我们点击 **开发设置 **,查看AppId与AppSecret
3.10 前段代码如何使用
-
安装Node.js
- 前往 nodejs.org/en/download… 下载node.js
- 安装说明:
- windows操作系统,参考: jingyan.baidu.com/article/482…
- Cenots系统,参考: www.cnblogs.com/baby123/p/6…
- macOS操作系统,用pkg直接拖动安装即可
- 其他系统,百度nodejs{操作系统名称}安装。
-
假定已有对应nodejs前端项目
-
打包命令: npm install 复制代码
-
打包加速命令: npm --registry https://registry.npm.taobao.org install 复制代码
-
开发环境启动部署: npm run dev 复制代码
-
生产环境构建: npm run build 复制代码
-
-
下载&安装微信开发者工具:
- 前往: developers.weixin.qq.com/miniprogram… 下载开发者工具
- 安装开发者工具
3.11 创建项目-1
- 技术选型:
- Spring Boot(快速开发)
- Spring Mvc(MVC框架)
- Mybatis(持久层框架,操作数据库)+通用Mapper
- Spring Cloud Alibaba(分布式)
- 项目结构规划:

3.12 创建项目-2
- 为项目引入通用Mapper
-
去掉原来的依赖(如果存在) org.mybatis.spring.boot mybatis-spring-boot-starter 复制代码
-
换成通用mapper tk.mybatis mapper-spring-boot-starter 2.1.5 复制代码
-
在启动类上使用MapperScan注解扫描需要的接口 @MapperScan(“xxx”) 复制代码
如图所示:
-

1. application.yml中配置mysql相关信息

通用Mapper专用代码生成器生成的Model会在原有基础上增加@Table,@Id,@Column等注解,方便自动回数据库字段进行映射。运行MBG有多种方法,这里只是介绍两种比较常见的方法。并且有关的内容会针对这样的运行方式进行配置;
1. 使用Java编码方式运行MBG:
- 在Generatr项目测试代码中包含这个例子: https://github.com/abel533/Mapper/blob/master/generator/src/test/java/tk/mybatis/mapper/generator/Generator.java 复制代码
要使用这种方式,需要引入MBG的依赖,同时项目中应该已经有通用Mapper的依赖了。
1. 使用Plugin的方式去运行:
1. 将如图代码引入pom.xml中的对应位置:

maven-compiler-plgin在SpringBoot中提供了,我们可以不用加
1. 在 **resources/generator**目录下创建generatorConfig.xml文件,如图所示:

1. 可以去百度这个文件下的内容,将对应的占位符信息填充即可

1. 如果有外部的config.properties引用,我们需要单独创建一个,将里面引入的比如username,password等信息在config.properties中补充,如图所示:

1. 补充完,并且在generatorConifg.xml中配置好了所有的内容后,点击右侧Maven的插件: mybaits-generator 选择generate即可生成代码,如图所示:

1. 它能生成model,也能生成通用maper的代码,如图所示:


3.13 整合Lombok简化代码编写
- Lombok
-
作用: 简化代码编写,提升开发效率
-
项目主页:([www.prjectlombok.org/)https://w…
-
IDEA中整合Lombok:
-

- 在IDEA中安装好了插件后,引入下方依赖(也可以自行百度最新版本)
org.projectlombok lombok 1.18.8 provided 复制代码
- 使用@Getter,@Setter,@ToString,@EqualsAndHashCode可以自动生成getter,setter,tostring等方法,如图所示:

- 注解说明:
- 使用@Data就相当于使用上面这几个注解,它内部聚合了这几个注解;
- @RequiredArgsConstructor是为标记为final的属性生成构造方法;
- @Builder使用了建造者模式,可以以这种方式去创建对象并且同时赋值;
- @Sl4j 注解,可以直接使用log功能
- 稳定功能和实验室功能,具体的可以在官网查看功能说明及示例;
- lombok与代码生成器:
- Lombok增加model代码生成时,可以直接生成lombok的@Getter@Setter@ToString@Accessors(chain=true)四类注解
- 使用者在插件配置项中增加 即可生成对应包含注解的model类
3.14 解决IDEA的红色警告
- 当我们引入mapper的时候,会暴露这样的警告:

可以看到 userMapper 下有一个红色警告。虽然代码本身没有问题,能正常运行,但有个警告总归有点恶心。本文分析原因,并列出解决该警告的集中方案;
- 原因:
- 众所周知,IDEA是非常智能的,它可以理解Spring的上下文。然而UserMapper这个接口是Mybatis的,IDEA理解不了。
- 而
@Autowired默认情况下要求依赖对象(也就是userMapper)必须存在。而IDEA认为注射个对象的实例/代理是个null,所以就友好的给个提示。
- 解决方案:
- 方法一:为@Autowired注解设置required= false,允许null值就不会有警告了。如图所示:

- 方法二:用 `@Resource`替换 `@Autowired`

- 方法三: 在Mapper接口上加上@Repository注解
- 方法四: 使用Lombok的注解,使用构造方法注入的方式;
- 直接在类上面使用此注解即可: @RequiredArgsConstructor() 复制代码
- 也可以使用此方式,更推荐: @RequiredArgsConstructor(onConstructor = @\\_\\_(@Autowired)) 复制代码
- 如图所示:

- 总结: 此种方式最为推荐,原因有2:
1. Spring官方并不建议直接在类的field上使用@Autowired注解,原因详见 《Why field injection is evil》,用本方法可将field注入编程构造方法注入,Spring是比较推荐的。
2. 体现了Lombok的优势,简化了你的代码。而且你也不用在每个field上都加上@Autowired注解了。
不过这种方式也有缺点: 那就是如果你类之间的依赖比较复杂,特别是存在循环依赖(A引用B,B引用A,或者间接引用时),引用将会启动不起来…这其实是构造方法注入方式的缺点;
- 方式五: 把IDEA的警告关闭掉
- 方式六: 安装Mybatis plugin插件(如图所示:)

3.18 现有架构存在的问题
- 地址发生变化了怎么办?
- 如何实现负载均衡?
- 用户中心挂掉了怎么办?
四. Spring Cloud Alibaba介绍
4.1 Spring Cloud Alibaba是什么
- 快速构建分布式系统的工具集(主要功能如图所示:)

- 部分子项目如图:

- 常用子项目如图:

- 什么是SpringCloudAlibaba?
- 它是Spring Cloud的子项目
- 致力于提供微服务开发的一站式解决方案
- 包含微服务开发的必备组件
- 机遇Spring Cloud,符合Spring Cloud标准
- 阿里的微服务解决方案
- SpringCloud Alibaba的功能描述:

- 我们整理后如图所示:

4.2 版本与兼容性
- 我们平时的版本是语义化的版本控制,在version中的版本号描述了此版本的大致情况,如图所示:

- SpringCloud很多项目是以字母排序命名的,因为它容易与它的一些子依赖的版本号起歧义,所以干脆不用数字了。

- 版本释义:

- SpringCloud发布生命周期
- 版本发布计划:(github.com/spring-clou…
- 版本发布记录:(github.com/spring-clou…
- 版本终止声明:(spring.io/projects/sp…
- 版本兼容性:

- 未来版本兼容性(如果SpringCloudAlibaba进入第二代后:)

- 生产环境如何选用版本?
- 坚决不用非稳定版本/end-of-life版本
- 尽量用最新一代
- xxx.RELEASE版本缓一缓
- SR2之后一般可大规模使用
4.3 为项目整合SpringCloudAlibaba
- 整合SpringCloudAlibaba
- 整合SpringCloud
- 引入依赖,如图所示:
- 整合SpringCloud

- 整合SpringCloudAlibaba
- 如果使用的是Greenwich版本,则使用如图依赖:

- 如果使用的是Finchley版本,则使用如图依赖:

- 第一种方式整合cloud以及Alibaba如图所示:

使用了如图所示内容后,我们在引入Cloud中的其他组件时,可以不指定版本,它会自动配置对应的版本。如果没有使用如图内容可能会导致依赖冲突,依赖不一致的情况;
五. 服务发现-Nacos
5.1 服务提供者与服务消费者
- 服务提供者:服务的被调用方(即:为其他微服务提供接口的微服务)
- 服务消费者:服务的调用方(即:调用其他微服务接口的微服务)
5.2 大白话剖析服务发现原理
- 问题:如果用户地址发生变化,怎么办?
- 服务发现机制就是通过一个中间件去记录服务提供者的ip地址,服务名以及心跳等数据(比如用mysql去存储这些信息),然后服务消费者会去这个中间平台去查询相关信息,然后再去访问对应的地址,这就是服务注册和服务发现。
- 当用户地址发生了变化也没有影响,因为服务提供方修改了用户地址,在中间件中会被更新,当服务消费方去访问中间件时就能及时获取最新的用户地址,就不会出现用户地址发生变化导致服务找不到
5.3 什么是Nacos?
- (官方文档:hptps://nacos.io/zh-cn/docs/what-is-nacos.html)[]
- 微服务全景架构图:

- 引入Nacos后的架构演进图:

5.4 搭建Nacos Server
-
下载Nacos Server
- (下载地址)[github.com/alibaba/nac…]
-
搭建Nacos Server
- (参考文档)[nacos.io/zh-cn/docs/…]
-
启动服务器:
-
Linux/Unix/Mac: sh startup.sh -m standalone 复制代码
-
Windows: cmd startup.md 复制代码
此处启动命令为单机模式,非集群模式
-
5.5 将应用注册到Nacos
- 目标:
- 用户中心注册到Nacos
- 内容中心注册到Nacos
- 测试: 内容中心总能找到用户中心
- 用户中心注册到Nacos
-
加依赖: org.springframework.cloud spring-cloud-starter-alibaba-nacos-discovery 复制代码
在SpringCloud中的依赖规则与SpringBoot类似。官方项目是以此作为结构:spring-cloud-starter-{spring cloud子项目的名称}-{模块名称},比如feign可以这样:spring-cloud-starter-openfeign,而sentinel可以这样:spring-cloud-starter-alibaba-sentinel,当没有模块的时候,就不用加模块了,比如feign就没有 -
加注解:
- 早期在启动类上需要加上 @EnableDiscoveryClient注解,现在已经可以不需要加了
-
加配置: spring: cloud: discovery: server-addr: localhost:8848 #指定nacos server的地址 application: name: 服务名称 # 比如 user-center,服务名称尽量用- ,不要用_ 复制代码
-
5.6 为内容中心引入服务发现
- 内容中心引入参照 章节5.5,其他服务也如此,服务名称相应变化一下;
- 注册成功如图所示:

使用DiscoverClient的相关Api可以在代码中获取Nacos提供的微服务的一些信息,调用方法如图:

复制代码
5.7 Nacos服务发现的领域模型
- 如图所示:

- 不同namespace是隔离的,使用Group可以进行管理(比如多个机房多个服务,可以将同机房的服务分一个组),Cluster是同一个Cluster下会尽量调用自己的Cluster服务;
- 各个关键字释义如下:
- Namespace: 实现隔离,默认public
- Group: 不同服务可以分到一个组,默认DEFAULT_GROUP
- Service: 微服务
- Cluster: 对指定微服务的一个虚拟划分,默认DEFAULT
- Instance: 微服务实例
- 指定方法,代码如图:
- 首先在Nacos中配置NameSpace:

- 然后在代码中添加字段:

5.8 Nacos元数据
- 什么是元数据?(Metadata)
- Nacos数据(如配置和服务)描述信息,如服务版本、权重、容灾策略、负载均衡策略、鉴权配置、各种自定义标签(label),从作用范围来看,分为服务级别的元信息、集群的元信息及实例的元信息。
- 应用(Application)
- 用于标识服务提供方的服务的属性
- 服务分组(Service Group)
- 不同的服务可以归类到同一分组
- 虚拟集群(Virtual Cluster)
- 同一个服务下的所有服务实例组成一个默认集群,集群可以被进一步按需求划分,划分的单位可以是虚拟集群;

- 元数据是什么?
- (官方描述)[nacos.io/zh-cn/docs/…]
- 级别: [服务级别、集群级别、实例级别]
- 元数据作用:
- 提供描述信息
- 让微服务调用更加灵活: 例如微服务版本控制
- 元数据操作方式:
- 如上图中可以在Nacos Server中进行 集群、服务、实例各级别的元数据控制
- 在application.yml中进行配置,如图所示:

六. 实现负载均衡
6.1 负载均衡的两种方式
- 服务器端负载均衡:

- 客户端负载均衡:

6.2 手写一个客户端侧负载均衡器
- 手写负载均衡器部分代码如图:

手写负载均衡器主要原理就是获取到此服务的所有url,然后以轮询、随机等方式进行调用指定的url
6.3 使用Ribbon实现负载均衡
- Ribbon是什么?
- Ribbon为我们提供了丰富的负载均衡算法;
- 引入Ribbon:
- 加依赖: 此步骤省略,因为Nacos已经结合了Ribbon
- 写注解:
- 在RestTemplate的Bean上加@LoadBalanced,如图所示: @Bean @LoadBalanced public RestTemplate restTemplate{ return new RestTemplate() } 复制代码

- 使用RestTemplate:

6.4 Ribbon组成
- Ribbon的组成如图,若不合适自己的,可以进行重写

6.5 Ribbon内置的负载均衡规则
- 负载均衡规则如图:

6.6 细粒度配置自定义01-Java代码
- 用Java代码配置
-
在与启动类包下创建: @RibonClient(name = “服务名称”, configuration=RibbonConfiguration.class) public class XXXRibbonConfiguration{ } 复制代码
-
如图所示:
-

- 在与启动类包不同路径下创建: @Configuration public class RibbonConfiguration{ @Bean public IRule ribbonRule(){ // 随机 return new RandomRule(); } } 复制代码
- 如图所示:

Ribbon的启动类不能被启动类扫描到,不然容易发生父子上下文重叠,出现各种bug问题;
6.7 细粒度配置自定义02-父子上下文
- 官方描述如图,父子上下文重叠会变成全局共享,所有服务都是这个配置;

6.8 细粒度配置自定义03-配置属性
-
在resource目录下的application.yml中添加配置: xxx服务名称: ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 想要的规则的类的所在全路径 复制代码
-
如图所示:

6.9 细粒度配置自定义04-两种方式
- 对比如图所示:

属性配置方式优先级更高。
6.10 细粒度配置自定义05-最佳实践
- 尽量使用属性配置,属性方式实现不了的情况下再考虑用代码配置
- 在同一个微服务内尽量保持单一性,比如统一使用属性配置,不要两种方式混用,增加定位代码的复杂性;
6.11 全局配置
- 让父子上下文重叠(强烈不建议使用,因为可能会导致项目无法启动,同时也不是科学的解决方案)
- 在我们定义的XXXRibbonConfiguration中,把configuration改为defaultConfiguration即可,代码如图所示:

6.12 支持的配置项
- 如图的每一项都支持,方式就是定义一个Bean,去返回它的实现类。如果配置实现类,则给指定的key值,value值为实现类的全路径地址;
- 配置规则如图:

- 代码配置如图所示:

- 配置属性方式如图所示:

代码配置和属性配置与之前上面的自定义配置一样;
6.13 饥饿加载
- 在使用RestTemplate的时候,用Rabbon时会进行懒加载,头一次的访问会比较慢。我们可以通过改变加载模式,将懒加载改为饥饿加载,这样第一次请求就不会慢了,在
application.yml中进行配置: ribbon: eager-load enabled: true clients: xxx服务名 # 多个服务,以,号分割 复制代码
此处为开启饥饿加载
6.14 扩展Ribbon-支持Nacos权重
- 因为Spring中的子项目没有对权重进行定义规范,所以它不支持权重,而Nacos是支持的;
- 扩展Ribbon支持权重的三种方式: hppts://www.imooc.com/article/288…
- 操作如图:
- 定义一个类去继承另外一个类
AbstractLoadBalancerRule并实现方法,如图所示:
- 定义一个类去继承另外一个类

- 补全代码:

- 定义Bean替换默认的:

- 在Nacos中编辑权重:

6.15 扩展Ribbon-同一集群优先调用
- 服务发现的领域模型:

- 使用Cluster可以非常方便的实现统一集群优先调用的办法,具体可百度
6.16 扩展Ribbon-基于元数据的版本
- 多版本共存的时候,某些接口只对指定的版本生效,我们可以扩展Ribbon,使用Nacos元数据来解决这个问题;
- 元数据解决办法,文档跳转:使用元数据解决数据共存问题
6.17 深入理解Nacos的NameSpace
- NameSpace是命名空间。处于不同命名空间的服务,它们之间是隔离的,通过这个特点,我们可以多个环境同时注册Nacos,通过处于不同的命名空间,去区分dev/test/prod等不同环境
- 代码如图:

6.18 现有架构存在的问题
- 远程调用代码不可读,url过长,不能准确区分出服务,复杂的url难以维护
- 微服务适应于快速迭代,就目前而言,难以响应需求的变化
- 编程体验不统一
七. 声明式HTTP客户端: Feign
7.1 使用Feign实现远程Http调用
-
Feign是NetFlix的一款声明式远程调用HTTP客户端;
-
整合办法:
-
pom.xml中引入依赖 org.springframework.cloud spring-cloud-starter-openfeign 复制代码
-
写注解,启动类上加上
@EnableFeignClients注解 -
写配置,暂时没有
-
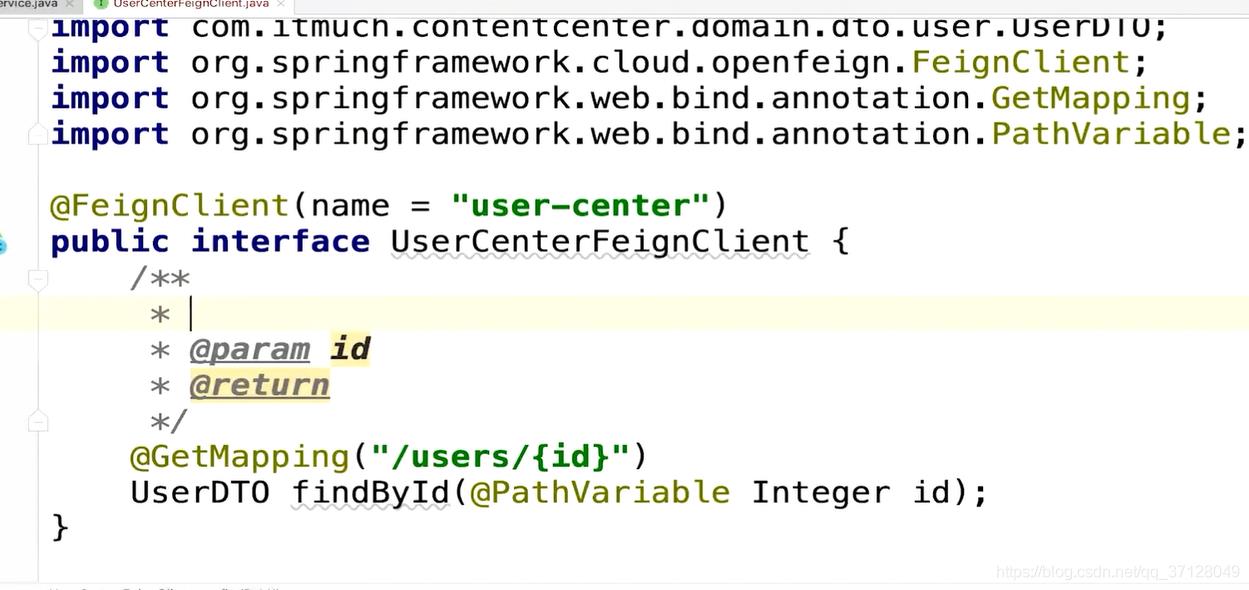
写一个Feign示例: @FeignClient(name=“xxx服务名称”) public interface xxxFeignCLient{ /** * 这是一个Feign的失恋了 * * / @GetMapping(“xxx/xxx”) XXX findById(xxx xxx) } 复制代码
类似于如图所示:
 复制代码
复制代码 -
-
Feign与Ribbon也可以一起整合,可以参考Feign的整合方式
7.2 Feign的组成
- 组成如图所示:

使用RequestInterceptor可以进行拦截,我们可以加上通用逻辑,比如为每个Feign的方法在调用的时候,都加上Header,Header里可以统一带上AuthToken
7.3 细粒度配置自定义-01-Java代码
- Feign的日志级别:

Feign的日志级别与通用的日志级别不同,它自己定义了四种日志级别
- 用Java代码配置如图:


在配置类中,不能加@Configuration,如果加了必须在启动类能扫描的地方以外,否则会发生父子上下文异常,导致全局共享这个配置类
7.4 细粒度配置自定义-02-配置属性
- 在resource/appilcation.yml中进行配置: feign: client: config: # 想要调用的微服务名称 user-center: loggerLevel: full 复制代码
7.5 全局配置-01-Java代码方式
- 让父子上下文重叠(不建议,这是以不正规的方式实现的)
- 唯一正确的途径: 在启动类中的 @EnableFeignClients(defaultConfiguration=xxx.class)

7.6 全局配置-02-配置属性方式
- 在resource/application.yml中进行设置

7.7 支持的配置项
- 代码方式,如图所示:

- 属性方式,如图所示:

7.8 配置最佳实践总结
- 概述:
- Rinnbon配置 vs Feign配置
- Feign代码方式 vs 属性方式
- 最佳实践总结
- 对比图如图:

- Feign代码方式 Vs 属性方式:

- 最佳实践:
- 尽量使用属性配置,属性方式实现不了的情况下再考虑用代码配置
- 在同一个微服务内尽量保持单一性,比如统一使用属性配置,不要两种方式混用
7.9 Feign的继承
- 当我们有一些服务存在一些相同的Feign远程调用时,我们可以将这些通用的Feign独立出来,然后写在外部的一些地方然后引用进来,直接继承。这样就可以一次修改,处处生效,同时遵循契约写法。
- 官方不建议使用,因为这样会导致多个微服务紧耦合。实际上很多公司在采用这种方式,个人可以权衡利弊。
7.10 GetMapping如何发送Feign请求
- 使用@GetMapping请求方式的Feign调用,它仍然会发送Post请求,所以会导致请求异常;
- 解决办法如下:
-
使用@SpringQueryMap 推荐,如图所示: @FeignClient(“xxxx-xx”) public interface UserFeignClient{ @GetMapping("/get") public User get0(@SpringQueryMap User user); } 复制代码
-
方法二:Url中有几个参数,Feign接口中的方法就有几个参数。使用@RequestParam注解指定请求的参数是什么 @FeignClient(“xxxx-xx”) public interface UserFeignClient{ @GetMapping("/get") public User get0(@RequestParam(“id”)Long id,@RequestParam(“username”)String str); } 复制代码
-
多参数的Url也可以使用Map来进行构建。当目标Url参数非常多的时候,可使用这种方式简化Feign接口的编写: @FeignClient(“xxxx-xx”) public interface UserFeignClient{ @GetMapping("/get") public User get0(@RequestParam Map<String,Object>map); } 复制代码
调用时可以使用类似如图代码:
-

7.11 Feign脱离Ribbon使用
- 脱离Ribbon使用就是不直接指定服务名去调用,而是直接填入url地址:
- 代码如图所示:

- Feign支持占位符,如图所示:

在早期的Spring Cloud版本中,无需提供name属性,从Brixton版开始,@FeignClient必须提供name属性,否则应用将无法正常启动;
7.12 RestTemplate VS Feign
- 对比如图:

-
如何选择?
- 原则:尽量使用Feign,杜绝使用RestTemplate
- 事无绝对,合理选择,就是如果Feign解决不了的,只有RestTemplate才能的情形
7.13 Feign常见性能优化
-
配置连接池(提升15%左右)
- okHtpp HttpClient都支持连接池
-
配置HttpClient:
-
引入依赖: io.github.openfeign feign-httpclient 复制代码
-
application.yml中进行配置: feign: client: config: #全局配置 default: loggerLevel: full httpclient: # 让Feign使用 apache httpclient做请求,而不是默认的urlHttp enabled: true # feign的最大连接数 max-connections:200 # feign单个路径的最大连接数 max-connections-per-route: 50 复制代码
如图所示:
-
 复制代码
复制代码
-
也可以使用OkHttp:
-
引入依赖: io.github.openfeign feign-okhttp 10.1.0 复制代码
-
在application.yml中增加配置:
-

- 还有一个优化是降低日志级别,越低的日志级别,打印的日志越少,同时性能就越高
八. 服务容错
8.1 雪崩效应
- 在我们的系统中,当一个服务宕机后,其他服务如果需要来访问这个服务时,就会得不到结果,然后会一直等待此服务返回结果,直至调用超时。每个一个访问请求都是一个线程资源,当服务的调用次数过多,就会导致大量的资源得不到释放,可能就会导致消费服务方也宕机,这样类推会导致雪崩效应,就是由一个服务宕机导致其他服务系统资源被持续占用消耗得不到释放,从而引发一连串的级联失败。
8.2 常见容错方案
- 设置超时时间
- 设置限流
- 仓壁模式:

比如这个船,里面每个船舱都是独立的,当一个船舱进水了,也不会导致所有的船舱进水,从而使船沉没。每个Controller作为一个“船舱”
- 断路器
- 参考我们日常中的电闸,当用电量超过阀值时,就会跳闸;
- 短路器的三态转换:

8.3 使用Sentinel实现容错
- Sentinel是什么?
- 它是一个轻量级容错的库
- 引入:
-
引入依赖:
org.springframework.cloud spring-cloud-starter-alibaba-sentinel 复制代码 -
引入actuator
org.springframework.boot spring-boot-starter-actuator 复制代码 -
application.yml 加入配置,暴露端点:
-

1. 访问 localhost:服务端口号/actuator/sentinel,出现如下图所示画面,即为配置完成:

8.4 Sentinel控制台
- 搭建控制台:
- (地址)[github.com/alibaba/Sen…]
- 版本选择: 根据我们的依赖版本或者使用最新的也可以,如果用在生产环境,最好是依赖与控制台版本相同;
- 使用方
以上是关于Spring Cloud Alibaba从入门到精通!的主要内容,如果未能解决你的问题,请参考以下文章