Pandas中数据去重
Posted JasonLiu1919
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas中数据去重相关的知识,希望对你有一定的参考价值。
背景
在数据处理过程中常常会遇到重复的问题,这里简要介绍遇到过的数据重复问题及其如何根据具体的需求进行处理。
筛选出指定字段存在重复的数据
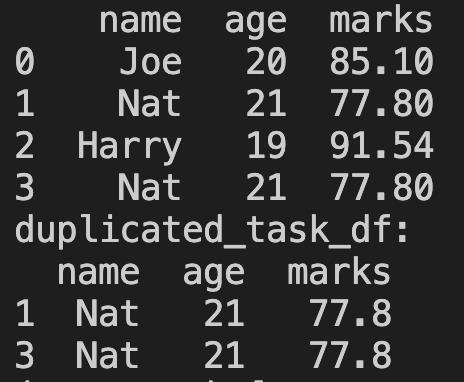
import pandas as pd
student_dict = {"name": ["Joe", "Nat", "Harry", "Nat"], "age": [20, 21, 19, 21], "marks": [85.10, 77.80, 91.54, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print(student_df)
duplicated_task_df = student_df[student_df.duplicated(subset=["age"], keep=False)]
print("duplicated_task_df:")
print(duplicated_task_df)
运行结果如下:
一旦重复即全部删除
一旦出现重复,则相同数据全部删除,一般出现在文本相同,但是标签不一致的场景:
import pandas as pd
student_dict = {"name": ["Joe", "Nat", "Harry", "Nat"], "age": [20, 21, 19, 21], "marks": [85.10, 77.80, 91.54, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print(student_df)
# drop all duplicate rows
student_df = student_df.drop_duplicates(keep=False)
print("drop all duplicate rows:")
print(student_df)
运行结果如下:
name age marks
0 Joe 20 85.10
1 Nat 21 77.80
2 Harry 19 91.54
3 Nat 21 77.80
drop all duplicate rows:
name age marks
0 Joe 20 85.10
2 Harry 19 91.54
原地操作
上述的去重操作结果是以一个copy出来的新DataFrame,这也是DataFrame.drop_duplicates的默认行为。如果想要直接在现有的DataFrame上进行修改,设置inplace=True即可。
import pandas as pd
student_dict = {"name": ["Joe", "Nat", "Harry", "Joe", "Nat"], "age": [20, 21, 19, 20, 21],
"marks": [85.10, 77.80, 91.54, 85.10, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print(student_df)
# drop duplicate rows
student_df.drop_duplicates(inplace=True)
print("drop duplicate rows with inplace=True:")
print(student_df)
运行结果如下:
name age marks
0 Joe 20 85.10
1 Nat 21 77.80
2 Harry 19 91.54
3 Joe 20 85.10
4 Nat 21 77.80
drop duplicate rows with inplace=True:
name age marks
0 Joe 20 85.10
1 Nat 21 77.80
2 Harry 19 91.54
根据指定字段去重后,并重置index
DataFrame.drop_duplicates 默认情况下是保留原始的row index,但是有时候我们需要根据0-N这种等差递增的index做其他操作时候,则需要重置index。
当 ignore_index=True, 重置行index为 0, 1, …, n – 1.
当 ignore_index=False, 则保留原始的行index, 这是默认操作
示例如下:
import pandas as pd
student_dict = {"name": ["Joe", "Nat", "Harry", "Nat"], "age": [20, 21, 19, 21], "marks": [85.10, 77.80, 91.54, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict, index=['a', 'b', 'c', 'd'])
print(student_df)
# drop duplicate rows
student_df0 = student_df.drop_duplicates(keep=False)
print("drop duplicate rows with ignore_index=False:")
print(student_df0)
# drop duplicate rows
student_df1 = student_df.drop_duplicates(keep=False, ignore_index=True)
print("drop duplicate rows with ignore_index=True:")
print(student_df1)
运行结果如下:
name age marks
a Joe 20 85.10
b Nat 21 77.80
c Harry 19 91.54
d Nat 21 77.80
drop duplicate rows with ignore_index=False:
name age marks
a Joe 20 85.10
c Harry 19 91.54
drop duplicate rows with ignore_index=True:
name age marks
0 Joe 20 85.10
1 Harry 19 91.54
以上是关于Pandas中数据去重的主要内容,如果未能解决你的问题,请参考以下文章