PCS2021:VVC基于神经网络改进SAO
Posted Dillon2015
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PCS2021:VVC基于神经网络改进SAO相关的知识,希望对你有一定的参考价值。
本文来自PCS2021论文《Revisiting the Sample Adaptive Offset post-filter of VVC with Neural-Networks》

在HEVC中就已经引入SAO来解决振铃效应,VVC中的SAO和HEVC中的基本相同。论文通过神经网络(NN)来改进SAO的性能,其中SAO的基本原理保持不变,但是原先SAO对重建像素的分类方法被替换为NN。通过NN的改进VVC上SAO在RA配置下BD-Rate增益为2.3%,并且和其他基于NN的方法相比复杂度很低。
SAO
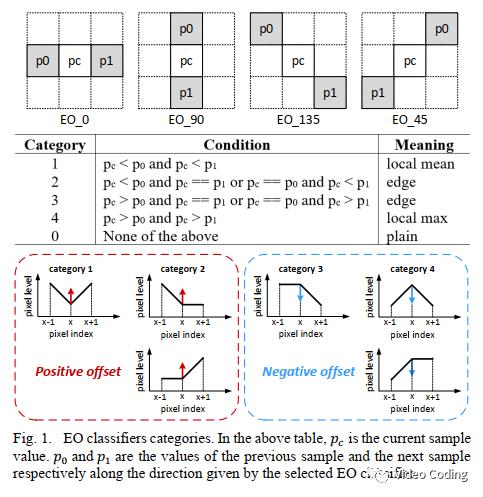
SAO的基本思想是将CTU内的像素划分为不同类别,然后对每个类别内的像素加一个补偿值。根据类别划分方式的不同有两种补偿方式:边界补偿(EO)和边带补偿(BO)。
EO是依据和旁边两个像素的关系将重建像素分为NC=5类,共有4个补偿值(类别0补偿值为0),如Fig.1所示。码流中需要传输这4个补偿值。
BO是将像素按照取值范围(8bit为0...255)分为32个条带。然后选择连续的(NC-1)=4个条带给予补偿值off(n),如Fig.2所示。码流中需要传输这4个补偿值,和选择的第一条边带的位置。

论文方法
算法框架
论文的整体框架SAO-CNN如Fig.3所示。它保留了SAO的主要原理,但是对于像素的分类选择使用K个CNN。分类器将重建像素分为NC个类别,其中每个CNN为每个像素s输出权重w(s)。这将产生比SAO更多的类别,因为CNN的不同输出可能会被认为是不同类别。
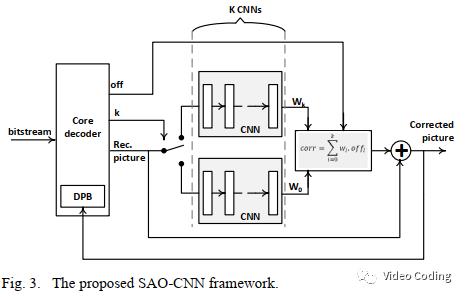
和SAO类似,有一个补偿值off_i和当前CTU使用的CNN(i)相关,
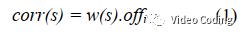
由于CNN的输出包含隐式的分类结果,所以不同的corr数量可能会远多于SAO的4个补偿值。需要将CNN的M个输出聚合,
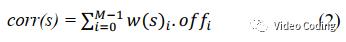
语法元素
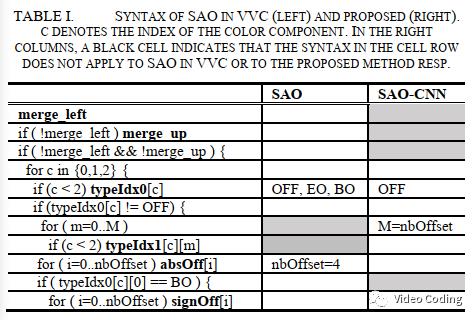
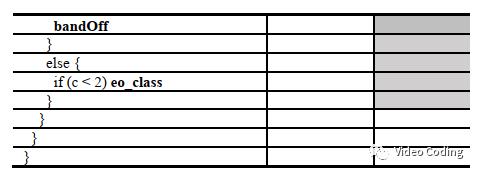
typeIdx用于编码CNN的索引。absOff和signOff用于编码补偿值off。由于低码率时corr的数量会增加且和区域的相关性有关,off_i的值可以从相邻CTU预测。
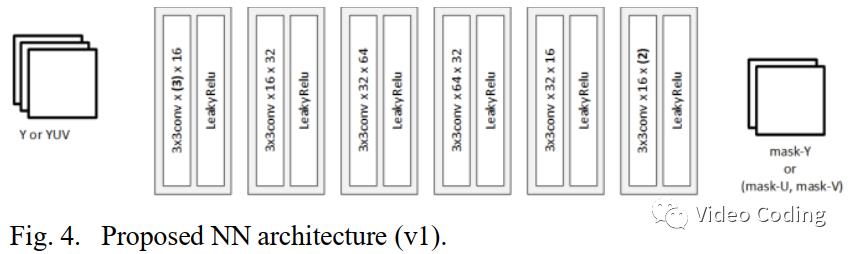
网络结构
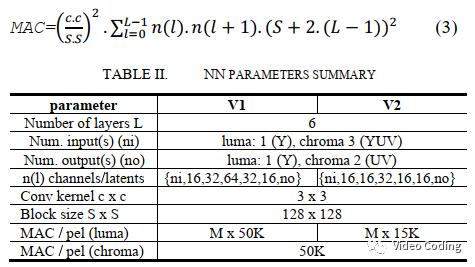
网络结构通过最小化每个像素的操作数(MAC)和参数数量来降低整体复杂度。CNN只包含6层,每层通道数16到32或64。有两个版本,其中v2比v1计算复杂度稍低,如表2。
网络架构如Fig.4,
假设CTU尺寸为SxS,对于尺寸为cxc的卷积核,每个像素的MAC为,
实验结果
训练
实验使用BVI-DVC数据集中的800个序列构建训练集,每个序列包含64帧,10bit,YCbCr420格式,从270p到2160p四种分辨率。这些序列使用VTM编码,使用RA和AI配置,QP={22,27,32,37}。在编码和解码过程中,启动传统的环路滤波。对每个QP,随机选择在SAO处理前的压缩视频帧和对应的原始视频帧,分成128x128的块并转换成YCbCr444格式。
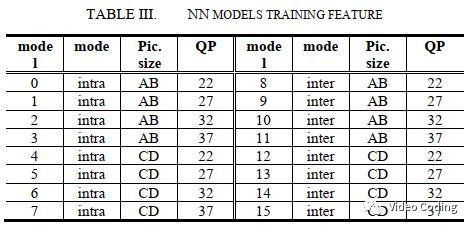
CNN的训练使用Tensorflow框架,训练参数为:l2损失函数,Adam优化器,batch size=20,训练130轮。共训练了16个模型,如表3。
VTM中实现
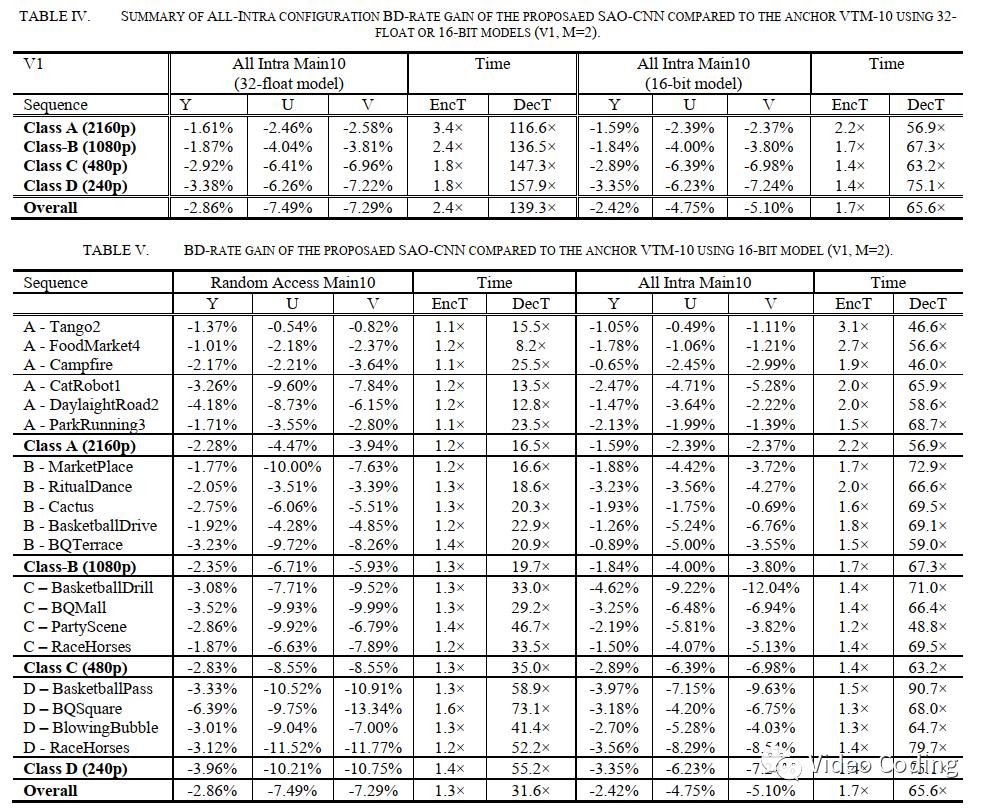
本文使用SAO-CNN框架替换VTM10.0中的SAO。CNN推理模型使用C++实现,使用32位浮点或16位量化权重。对于后者,会将32位的NN的权重量化为16位以使所有计算都可以使用整数完成。还可以使用SIMD加速,编码器和解码器相比32位浮点模型的加速比分别为1.4和2.1,而BD-Rate几乎不变,如表4。除了加速,整数计算还可以保证编码器和解码器的计算精度相同,不会在重建帧中出现漂移误差。
结果
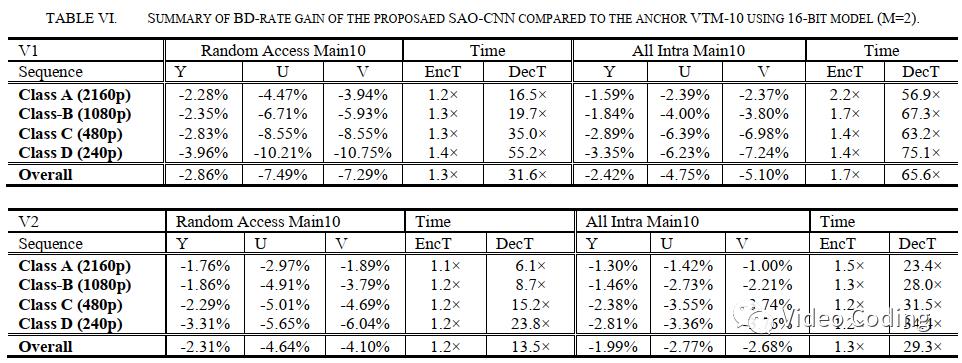
表5和表6是实验结果,对应v1模型在亮度分量上RA和AI配置的BD-Rate分别为-2.86%和-2.42%,色度分别为-7%和-5%。
编码和解码时间比是在没有GPU的单核处理器上测的,相比于VTM10,对于v2模型编码器复杂度低于1.3x,解码时间在6x到32x间。
感兴趣的请关注微信公众号Video Coding

以上是关于PCS2021:VVC基于神经网络改进SAO的主要内容,如果未能解决你的问题,请参考以下文章