王喆-深度学习推荐系统实战基础架构篇-(task1)DL推荐系统架构
Posted 奇跡の山
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了王喆-深度学习推荐系统实战基础架构篇-(task1)DL推荐系统架构相关的知识,希望对你有一定的参考价值。
学习心得
- 通过task1的学习在脑海里建立DL背景的推荐系统架构:为了解决【在“信息过载”情况下,用户怎么高效获取感兴趣的信息】的问题,并且构建更好的拟合数据和表达能力的模型,深度学习上场了。其中DL推荐模型 = 召回层 + 排序层 + 补充策略与算法层 ,这里的模型指模型服务过程。
- 推荐系统的逻辑架构:对于某个用户U(User),在特定场景C(Context)下,针对海量的“物品”构建一个函数 ,预测用户对特定候选物品I(Item)的喜好程度的过程。
- 深度学习中 Embedding 技术在召回层的应用,做相关物品的快速召回,已经是业界非常主流的解决方案。排序层(也称精排层)是影响推荐效果的重中之重,也是深度学习模型大展拳脚的领域,因为深度学习模型灵活性高,表达能力强(因此非常适合于大数据量下的精确排序)。
PS:深度学习的发展,也推动着推荐系统数据流部分的革命(就是平时说的大数据开发岗了),让它能够更快、更强地处理推荐系统相关的数据。

回顾:
文章目录
当学习一个全新领域,王喆大佬最想搞明白的是2个问题:
(1)这个领域能解决什么问题?
(2)这个领域有没有一个非常高角度的思维导图,让自己能了解该领域有哪些技术?
(3)针对深度学习,还有第三个问题:深度学习对推荐系统带来啥革命性变革?
一、推荐系统要解决的根本问题
无论什么推荐系统场景,如商品推荐、视频推荐、新闻推荐这些推荐场景,都有共同的逻辑框架,而推荐系统是“浩如烟海的互联网信息”和“用户兴趣点”之间的桥梁,我们的推荐系统要解决的就是在“信息过载”的情况下,用户如何高效获得感兴趣的信息。
二、推荐系统的逻辑架构
推荐系统要解决“人”与“商品信息”之间的关系。
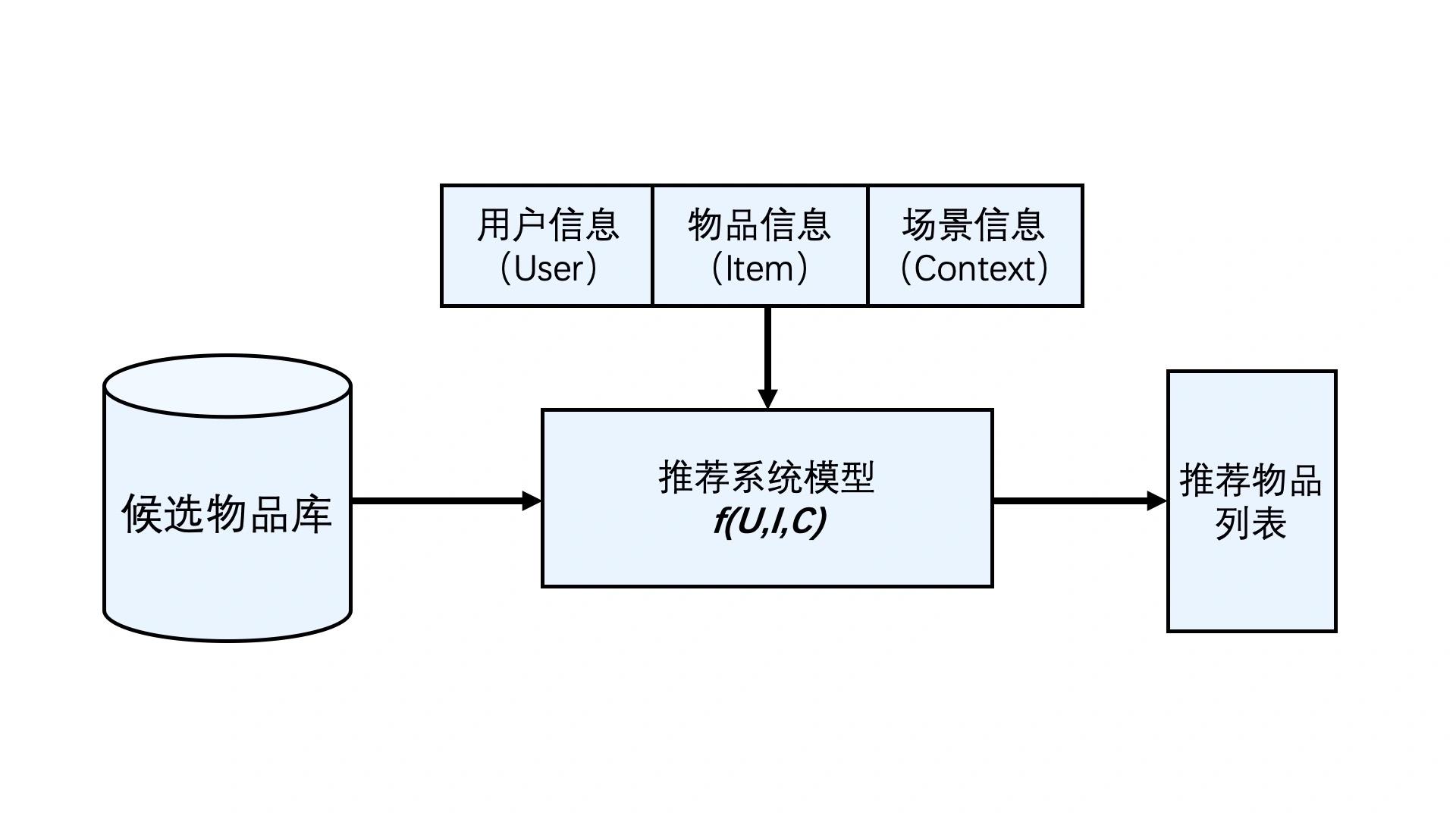
2.1 三大信息
- 用户信息:而从“人”角度看,为了精准推测出“人”的兴趣点,推荐系统需要利用大量与“人”相关的信息,即历史行为、人口属性、关系网络等,它们可以被统称为“用户信息”。
- “场景信息”或“上下文信息”:在具体的推荐场景中,用户的最终选择一般会受时间、地点、用户的状态等一系列环境信息的影响。
- “物品信息”:比如说,在商品推荐中指的是“商品信息”,在视频推荐中指的是“视频信息”,在新闻推荐中指的是“新闻信息”。
2.2 推荐系统要处理的问题:
结合上图:
(1)对于某个用户U(User),在特定场景C(Context)下,针对海量的“物品”信息构建一个函数 ;
(2)该函数预测用户对特定候选物品I(Item)的喜好程度;
(3)再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题。
三、深度学习对推荐系统的革命
在上面图一的推荐系统逻辑架构图中,中间的函数 f ( U , I , C ) f(U,I,C) f(U,I,C)(一般称为推荐系统模型,后面直接说“推荐模型”)
3.1 传统的推荐模型
传统的推荐模型叠加了很多层,模型较为复杂,只能拟合出推荐函数的近似形式,而深度学习模型能最大程度的接近该最优形式。
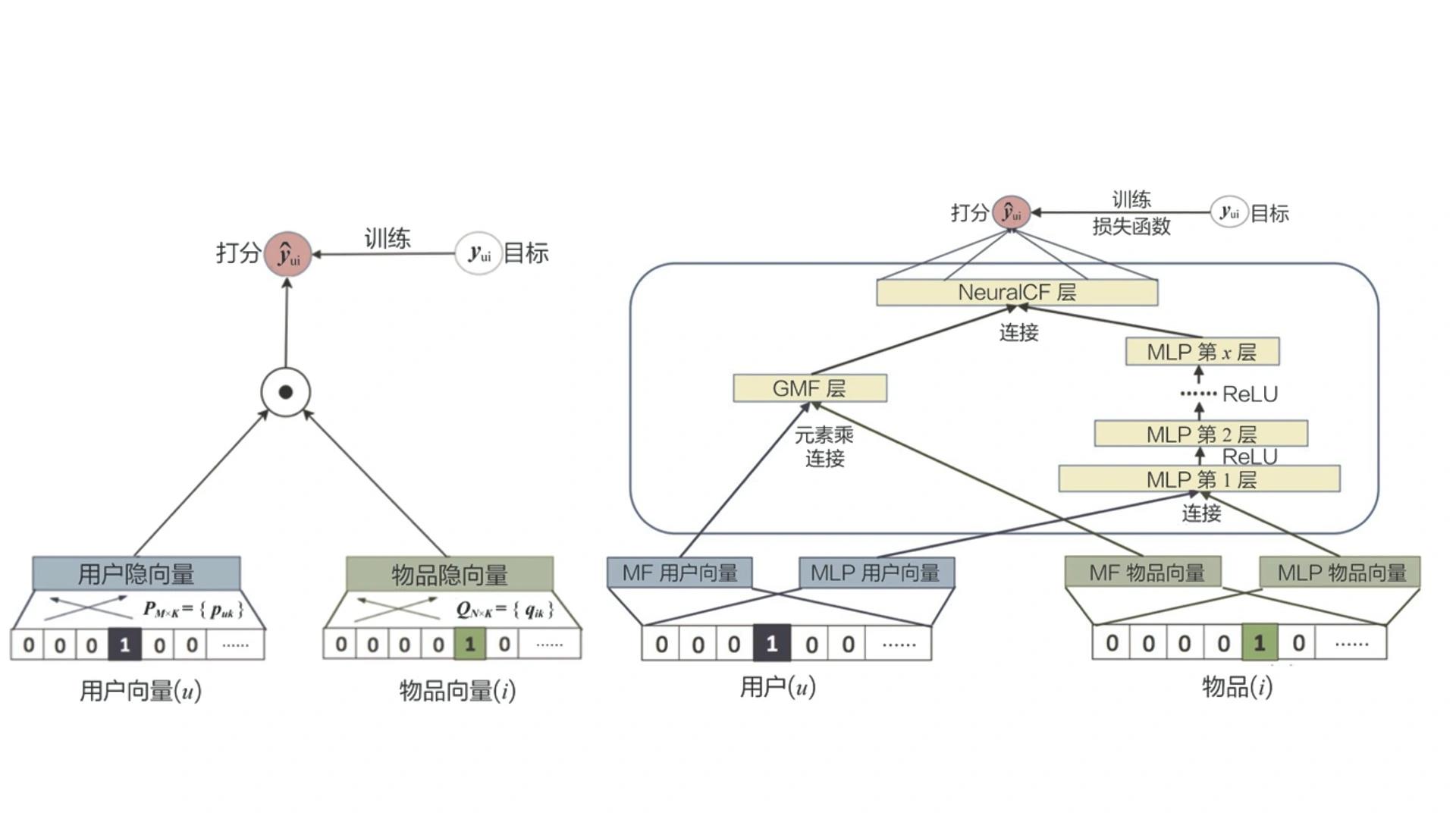
3.2 深度学习推荐系统
- 深度学习复杂的模型结构应用于推荐系统,能够极大地增强推荐模型的拟合能力和表达能力,即使得推荐函数具有最优的表达形式。
- 深度学习模型的神经网络模拟很多用户兴趣的变迁过程,甚至用户做出决定的思考过程。比如阿里巴巴的深度学习模型——深度兴趣进化网络(如下图),它利用了三层序列模型的结构,模拟了用户在购买商品时兴趣进化的过程,如此强大的数据拟合能力和对用户行为的理解能力,是传统机器学习模型不具备的。

四、深度学习推荐系统的技术架构
深度学习推荐系统不是完全创新搞一个技术架构出来,而是对以前的架构模块修改,使得能支持深度学习的应用(类似的应用思想可以想在其他领域,如智能金融,医疗病例NLP应用等blabla的)。
在实际的推荐系统中,工程师需要着重解决的问题有两类:
- 与数据和信息相关,即“用户信息”“物品信息”“场景信息”分别是什么?如何存储、更新和处理数据?——数据和信息部分逐渐发展为推荐系统中融合了数据离线批处理、实时流处理的数据流框架。
- 与推荐系统算法和模型相关,即推荐系统模型如何训练、预测,以及如何达成更好的推荐效果?——算法和模型部分则进一步细化为推荐系统中,集训练(Training)、评估(Evaluation)、部署(Deployment)、线上推断(Online Inference)为一体的模型框架。
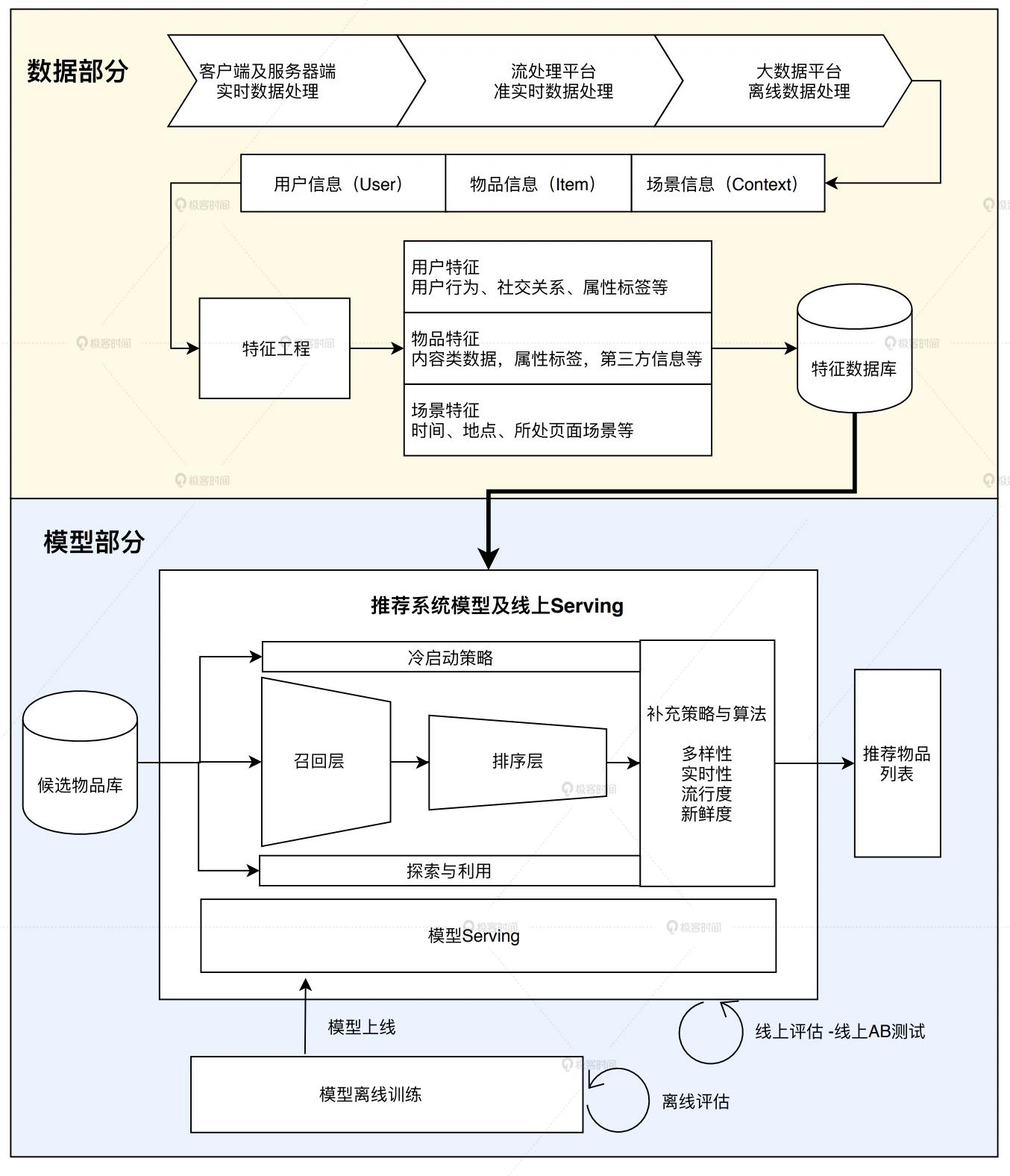
4.1 数据部分
推荐系统的“数据部分”主要负责的是“用户”“物品”“场景”信息的收集与处理。根据处理数据量和处理实时性的不同,我们会用到三种不同的数据处理方式,按照实时性的强弱排序的话,它们依次:客户端与服务器端实时数据处理、流处理平台准实时数据处理、大数据平台离线数据处理。
在实时性由强到弱递减的同时,三种平台的海量数据处理能力则由弱到强。因此,一个成熟推荐系统的数据流系统会将三者取长补短,配合使用。后面会提到具体的例子,比如使用 Spark 进行离线数据处理,使用 Flink 进行准实时数据处理等等。
大数据计算平台通过对推荐系统日志,物品和用户的元数据等信息的处理,获得了推荐模型的训练数据、特征数据、统计数据等。那这些数据都有什么用呢?具体说来,大数据平台加工后的数据出口主要有 3 个:
- 生成推荐系统模型所需的样本数据,用于算法模型的训练和评估。
- 生成推荐系统模型服务(Model Serving)所需的“用户特征”,“物品特征”和一部分“场景特征”,用于推荐系统的线上推断。
- 生成系统监控、商业智能(Business Intelligence,BI)系统所需的统计型数据。
推荐系统的数据部分是整个推荐系统的“水源”:
- 首先是水量要大,只有这样才能保证我们训练出的深度学习模型能够尽快收敛;
- 其次是“水流”要快,让数据能够尽快地流到模型更新训练的模块,这样才能够让模型实时的抓住用户兴趣变化的趋势,这就推动了大数据引擎 Spark,以及流计算平台 Flink 的发展和应用。
4.2 模型部分
推荐系统的“模型部分”是推荐系统的主体。模型的结构一般由“召回层”、“排序层”以及“补充策略与算法层”组成。
模型服务过程:推荐系统模型接收所有候选物品集,到最后产生推荐列表。
通过模型的训练确定模型结构、结构中不同参数权重值,以及模型相关算法和策略中的参数取值。

(1)模型的结构组成
- “召回层”一般由高效的召回规则、算法或简单的模型组成,这让推荐系统能快速从海量的候选集中召回用户可能感兴趣的物品。
- “排序层”则是利用排序模型对初筛的候选集进行精排序。
- “补充策略与算法层”,也被称为“再排序层”( r e r a n k rerank rerank),是在返回给用户推荐列表之前,为兼顾结果的“多样性”“流行度”“新鲜度”等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表。
为了评估推荐系统模型的效果,以及模型的迭代优化,推荐系统的模型部分还包括“离线评估”和“线上 A/B 测试”等多种评估模块,用来得出线下和线上评估指标,指导下一步的模型迭代优化。
(2)模型训练方法的分类
根据环境的不同,可以分为“离线训练”和“在线更新”两部分。
- 离线训练的特点是可以利用全量样本和特征,使模型逼近全局最优点。PS:可以看做是在线更新的预训练模型。
- 在线更新则可以准实时地“消化”新的数据样本,更快地反应新的数据变化趋势,满足模型实时性的需求。
(3)三点总结
- 深度学习中 Embedding 技术在召回层的应用。作为深度学习中非常核心的 Embedding 技术,将它应用在推荐系统的召回层中,做相关物品的快速召回,已经是业界非常主流的解决方案了。
- 不同结构的深度学习模型在排序层的应用。排序层(也称精排层)是影响推荐效果的重中之重,也是深度学习模型大展拳脚的领域。深度学习模型灵活性高,表达能力强(因此非常适合于大数据量下的精确排序)。工业界和学业界都在不断投入和迭代深度学习排序模型。
- 增强学习在模型更新、工程模型一体化方向上的应用,它让推荐系统可以在实时性层面更强。
PS:推荐系统的模型(策略层)一般分三个阶段,召回层(Embeding技术)、排序层(精排-深度模型)、增强学习。
五、作业
下面是 Netflix(一家流媒体公司) 的推荐系统的经典架构图,结合所学的推荐系统技术架构,问:哪些是数据部分,哪些是模型部分。
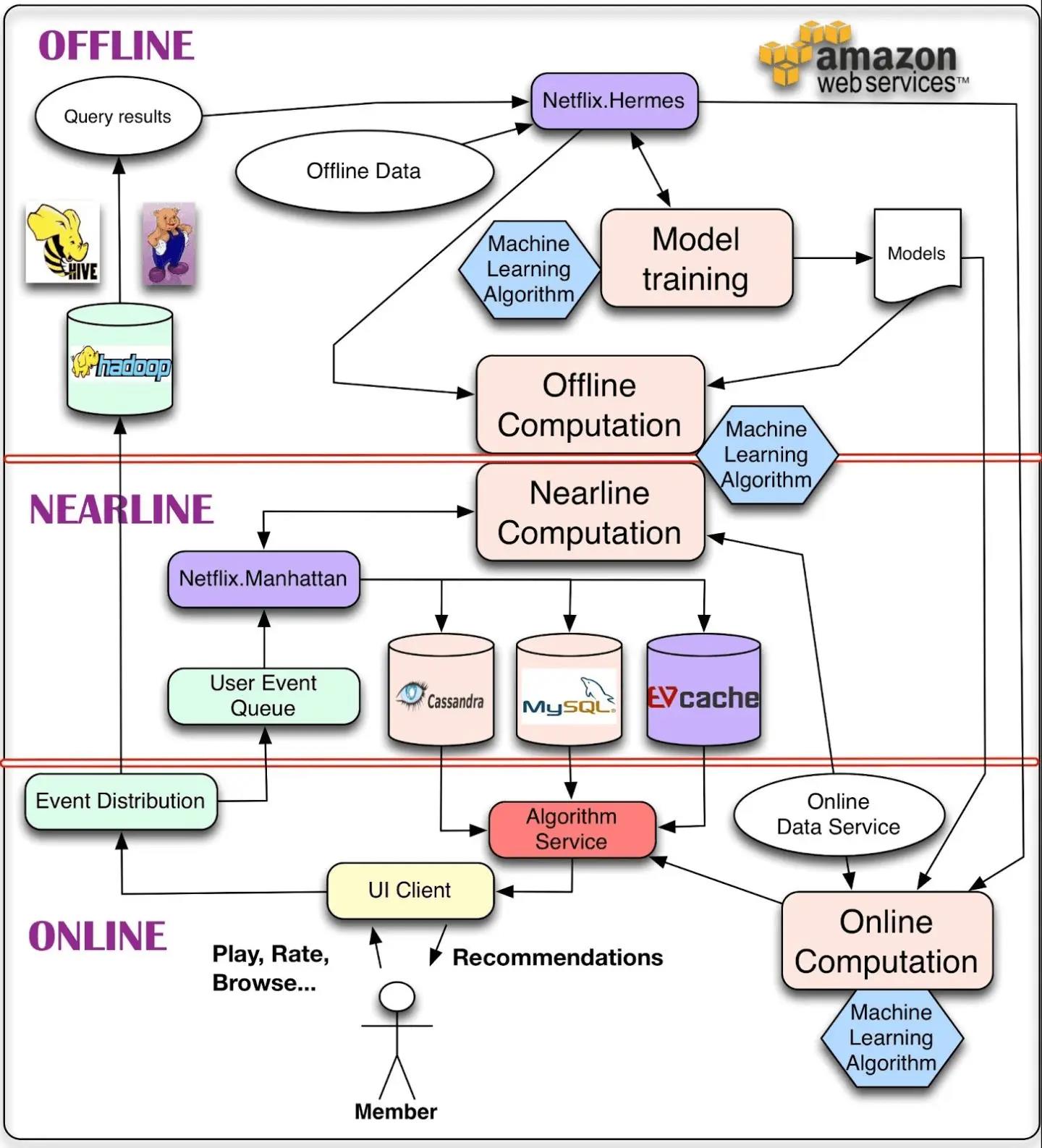
数据部分:event distribution, hadoop, query results, netflex.hermes, user event queue, netflix.manhattan.
模型部分:model training, models, online computation, online service, algorithm service.
nearline computation也属于数据部分,正中央的evcache等几个数据库可以看作数据部分和模型部分的接口。
Reference
《深度学习推荐系统实战》——王喆
以上是关于王喆-深度学习推荐系统实战基础架构篇-(task1)DL推荐系统架构的主要内容,如果未能解决你的问题,请参考以下文章