⚡机器学习⚡慢特征分析(SFA)的项目测试分析
Posted 府学路18号车神
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了⚡机器学习⚡慢特征分析(SFA)的项目测试分析相关的知识,希望对你有一定的参考价值。
还有两天就国庆了,小伙伴们是不是已经按捺不住内心的小鸡冻了呀!!!
有没有人和车神哥一起敲代码,科研报国!!!(虽然菜鸡一个,但是心还是有的)
最近测试了一个关于SFA(之前博客写过的)算法,现在在做实际项目应用,说实话,实际与理论确实有很大的偏差,需要做到很多次的调试与核验,emmmmmmm,最终应用效果咱们另做打算。
项目背景
具体算法咱们就不多说了,可以在这里看看。
简要说下项目背景,这个项目当然是国家自然。。。。。。。。噼里啪啦噼里啪啦的一大堆,哈哈哈哈,没有没有,就一个很简单的模型测试实验,不然咱也不能这么Poster出来吧~
简单说就是有一个地方有很多很多的消耗品(宝物),然而里面现在包含一些其他的杂质(废物),我们并不希望在获取那些宝物的时候也把一些不要的废物给一起揣包里了,需要分辨出哪些是废物,哪些是宝物。然鹅,现在我们有很多很多的表征宝物和废物的特征,但是也不知道什么表征宝物,什么来表征废物,所以说嘛,这里的SFA测试只是第一步,通过过程监控的方式来把他给检测出来,从时间序列上获取稳态和动态信息。目前只需要检测出哪些是宝物哪些是废物,假设废物就是故障,宝物是正常的。
了解了整个背景后,明确一件事,检测出废物,得到宝物。
好!
咱直接上测试
测试
我们一共有很多层的数据集,由此我们单独对每一层的特征数据进行SFA慢特征分析。
按照故障诊断的尿性,必得有正常工况的数据和故障工况的数据,在这,咱只能硬上了。
存在的问题:不知道何为正常工况的数据,建立的模型是否准确,方法是否可行
我们假设以第n层作为正常工况的数据作为训练数据(建模数据),建立模型。然后再用故障数据(同为第n层)进行检测。(检测的话,通过四个统计量 T 2 、 T e 2 、 S 2 、 S e 2 T^2、T_e^2、S^2、S_e^2 T2、Te2、S2、Se2,和之前PCA的统计量类似,只不过是分为了时序的,稳态和动态特征下的检测数据)
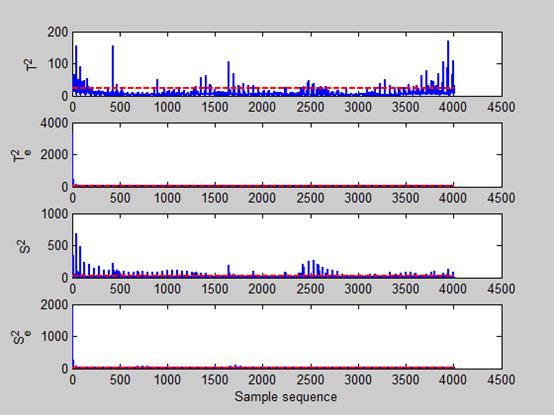
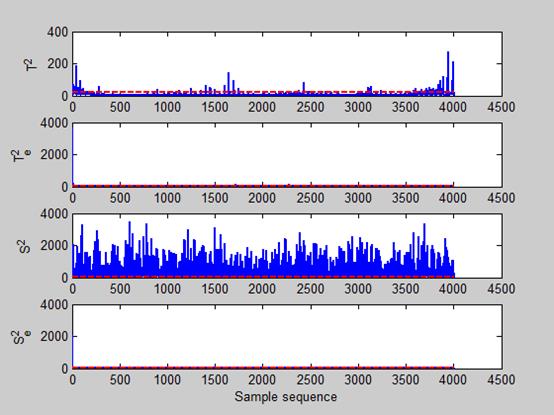
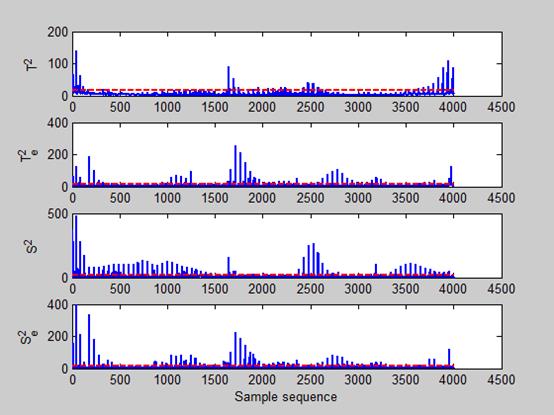
这里我们就先只放三层的数据检测结果,会发现,在前两层的数据中,只有
T
2
、
S
2
T^2、S^2
T2、S2稳态特征的检测结果,在动态特征下的
T
e
2
、
S
e
2
T_e^2、S_e^2
Te2、Se2检测结果是不明显的,后台在查数据的时候发现,其实是有值得,但是非常非常的小,而且阈值限也极为小。然后我们再观测后面第三个图的统计量,什么…神么肥撕,
T
2
、
T
e
2
、
S
2
、
S
e
2
T^2、T_e^2、S^2、S_e^2
T2、Te2、S2、Se2检测值奇异值竟然这么多,难道是数据的问题,不会呀,数据都以同一批数据,但是确实是出现了这么一个问题,奇异值凸起过多。经过我们对比,所有层中,就只有这一层的数据出现了这个问题,好,现在返回我们的项目背景,咱们是要找到废物,把他踢出出来,然后就可以更好的拿到宝物了,难道奇迹已经出现。
可视化干起来!!!
我们对应的数据集是空间上的,所谓的层数只是在Z坐标轴方向上进行检测,所以咱们把每一层的检测值给叠加起来,看看效果!!!
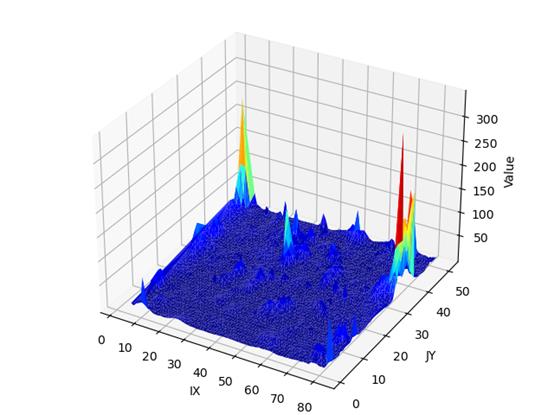
上图为 T 2 T^2 T2的三维图
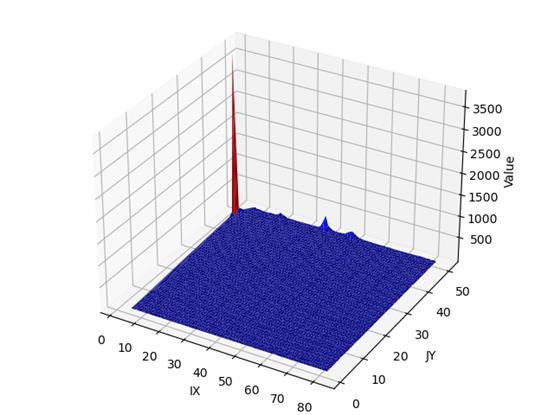
此为 T e 2 T^2_e Te2的三维图,可以看出来很多的地方都是没什么变化的,只有红色的点为奇异值,但是,对比专家的结果来看,好像是有那么亿点点问题!!!
我们再看看 S 2 、 S e 2 S^2、S_e^2 S2、Se2三维叠加图
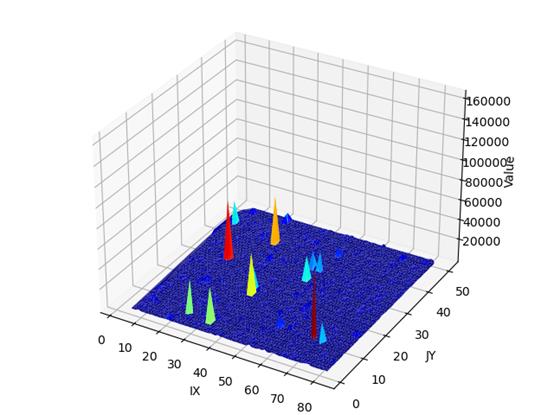
上为 S 2 S^2 S2三维图
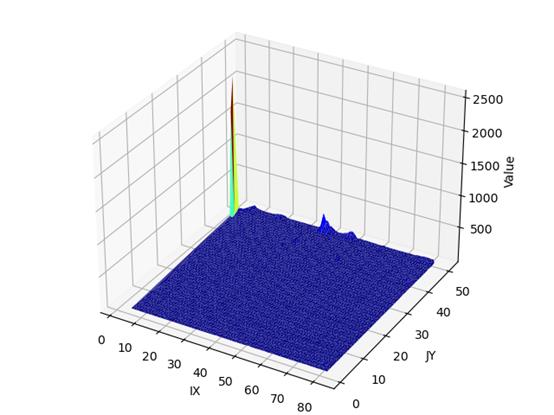
上为 S e 2 S_e^2 Se2三维图
从 S 2 、 S e 2 S^2、S_e^2 S2、Se2的三维叠加图来看,和 T 2 、 T e 2 T^2、T_e^2 T2、Te2类似。
回过来看,最重要的一点是找到废物,只拿宝物。
具体验证过程过于鸡米,不便展示。
总结下,SFA在时序特征提取方面还是很有用的,具体落在项目应用上,还得结合更加专业的结合,纯数据驱动很难解释其中的物理意义,解决这一块,我相信数据驱动的相关邻域只是会大力的发展,并会连锁反应带动更多的其他邻域的进步!!!
加油!!!
为了不受限于人!!!
淦!!!
❤坚持读Paper,坚持做笔记,坚持学习❤!!!
⚡To Be No.1⚡⚡哈哈哈哈
学习DeepLearning坚持!30天计划!!!
打卡 第 6 /30 Day!!!
⚡创作不易⚡,过路能❤关注、收藏、点个赞❤三连就最好不过了
ღ( ´・ᴗ・` )
❤
『
困难只能吓到懦夫懒汉,而胜利永远属于干预攀登科学高峰的人。
』
以上是关于⚡机器学习⚡慢特征分析(SFA)的项目测试分析的主要内容,如果未能解决你的问题,请参考以下文章