Kafka如何修改分区Leader | 文末送书8本
Posted 石臻臻的杂货铺
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka如何修改分区Leader | 文末送书8本相关的知识,希望对你有一定的参考价值。
🔥《Kafka运维管控平台》🔥 ✏️更强大的管控能力✏️ 🎾更高效的问题定位能力🎾 🌅更便捷的集群运维能力🌅 🎼更专业的资源治理🎼 🌞更友好的运维生态🌞
大家好,我是石臻臻,这是 「kafka专栏」 连载中的第「N」篇文章…
前几天有个群友问我: kafka如何修改优先副本?
他们有个需求是, 想指定某个分区中的其中一个副本为Leader
需求分析
对于这么一个问题,在我们生产环境还是挺常见的,经常有需要修改某个Topic中某分区的Leader
比如 topic1-0这个分区有3个副本[0,1,2], 按照「优先副本」的规则,那么 0 号副本肯定就是Leader了
我们都知道分区中的只有Leader副本才会提供读写副本,其他副本作为备份
假如在某些情况下,「0」 号副本性能资源不够,或者网络不太好,或者IO压力比较大,那么肯定对Topic的整体读写性能有很大影响, 这个时候切换一台压力较小副本作为Leader就显得很重要;
优先副本: 分区中的AR(所有副本)信息, 优先选择排在第一位的副本作为Leader
Leader机制: 分区中只有一个Leader来承担读写,其他副本只是作为备份
那么如何实现这样一个需求呢?
解决方案
知道了原理之后,我们就能想到对应的解决方案了
只要将 分区的 AR 中的第一个位置,替换成你指定副本就行了;
AR = { 0,1,2 } ==> AR = {2,1,0}
一般能够达到这个目的有两种方案,下面我们来分析一下
方案一: 分区副本重分配
之前关于分区副本重分配 我已经写过很多文章了,如果想详细了解 分区副本重分配、数据迁移、副本扩缩容 可以看看链接的文章, 这里我就简单说一下;
一般分区副本重分配主要有三个流程
- 生成推荐的迁移Json文件
- 执行迁移Json文件
- 验证迁移流程是否完成
这里我们主要看第2步骤, 来看看迁移文件一般是什么样子的
{
"version": 1,
"partitions": [{
"topic": "topic1",
"partition": 0,
"replicas": [0,1,2]
}]
}
这个迁移Json意思是, 把topic1的「0」号分区的副本分配成[0,1,2] ,也就是说 topic1-0号分区最终有3个副本分别在 {brokerId-0,brokerId-1,brokerId-2} ; 如果你有看过我之前写的 分区副本重分配原理源码分析 ,那么肯定就知道,不管你之前的分配方式是什么样子的, 最终副本分配都是 [0,1,2] , 之前副本多的,会被删掉,少的会被新增;
那么我们想要实现 我们的需求
是不是把这个Json文件 中的 “replicas”: [0,1,2] 改一下就行了,比如改成 “replicas”: [2,1,0]
改完Json后执行,执行execute, 正式开始重分配流程! 迁移完成之后, 就会发现,Leader已经变成上面的第一个位置的副本「2」 了
优缺点
优点: 实现了需求, 并且主动切换了Leader
缺点: 操作比较复杂容易出错,需要先获取原先的分区分配数据,然后手动修改Json文件,这里比较容易出错,影响会比较大,当然这些都可以通过校验接口来做好限制, 最重要的一点是 副本重分配当前只能有一个任务 !
假如你当前有一个「副本重分配」的任务在,那么这里就不能够执行了, 「副本重分配」是一个比较「重」 了的操作,出错对集群的影响比较大
方案二: 手动修改AR顺序
首先,我们知道分区副本的分配数据是保存在zookeeper中的节点brokers/topics/{topicName} 中; 我们看个Topic1的节点数据例子;
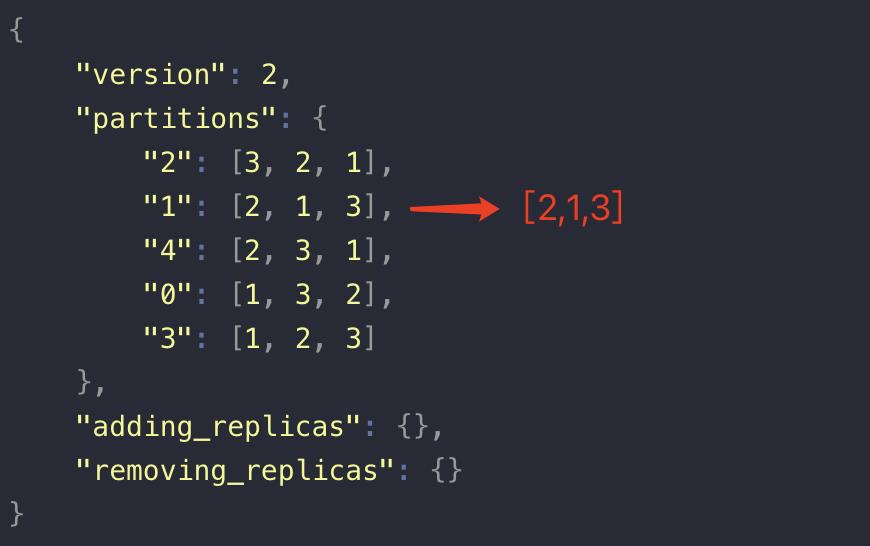
{
"version": 2,
"partitions": {
"2": [3, 2, 1],
"1": [2, 1, 3],
"4": [2, 3, 1],
"0": [1, 3, 2],
"3": [1, 2, 3]
},
"adding_replicas": {},
"removing_replicas": {}
}
数据解释:
version:
版本信息, 现在有 「1」、「2」 两个版本
removing_replicas:
需要删除的副本数据, 在进行分区副本重分配过程中,
多余的副本会在数据迁移快完成的时候被删除掉,删除成功这里的数据会被清除
adding_replicas:
需要新增的副本数据,在进行分区副本重分配过程中,
新增加的副本将会被新增,新增完成这里的数据会清除;
partitions:
Topic的所有分区副本分配方式; 上面表示总共有5个分区,以及对应的副本位置;
知道了这些之后,想要修改优先副本,是不是可以通过直接修改zookeeper中的节点数据就行了; 比如
我们把 「1」号分区的副本位置改成 [2,1,3]
改成这样之后, 还需要 执行 重新进行优先副本选举操作 ,例如通过kafka的命令执行
sh bin/kafka-leader-election.sh --bootstrap-server xxxx:9090 --topic Topic1--election-type PREFERRED --partition 1
--election-type : PREFERRED 这个表示的以优先副本的方式进行重新选举
那么做完这两步之后, 我们的修改优先副本的目的就达成了…吗 ?
实则并没有, 因为这里仅仅只是修改了 zookeeper节点的数据, 而bin/kafka-leader-election.sh 重选举的操作是Controller来进行的; 如果你对Controller的作用和源码足够了解, 肯定知道Controller里面保存了每个Topic的分区副本信息, 是保存在JVM内存中的, 然后我们手动修改Zookeeper中的节点,并没有触发 Controller更新自身的内存
也就是说 就算我们执行了kafka-leader-election.sh, 它也不会有任何变化,因为优先副本没有被感知到修改了;
解决这个问题也很简单,让Controller感知到数据的变更就行了
最简单的方法, 让Controller发生重新选举, 数据重新加载!
总结
- 手动修改zookeeper中的「AR」顺序
- Controller 重新选举
- 执行 分区副本重选举操作(优先副本策略)
简单代码
当然上面功能,肯定是要集成到LogiKM中的咯; 简单代码如下
// 这里转换成HashMap类型,切勿自定义类型,以防kafka节点数据后续新增数据节点,导致数据丢失
HashMap partitionMap = zkConfig.get(ZkPathUtil.getBrokerTopicRoot(topicName), HashMap.class);
JSONObject partitionJson = (JSONObject)partitionMap.get("partitions");
JSONArray partitions = (JSONArray)partitionJson.get(partition);
//部分代码省略
//调换序列 优先副本
Integer first = partitions.getInteger(0);
partitions.set(0,targetBroker);
partitions.set(index,first);
zkUtils = ZookeeperUtils.getKafkaZkUtils(clusterDO.getZookeeper());
String json = JSON.toJSONString(partitionMap);
zkUtils.updatePersistentPath(ZkPathUtil.getBrokerTopicRoot(topicName), json,null);
//写入成功之后触发一下 异步去优先副本选举
new Thread(()->{
try {
// 1. 先让Controller重新选举 (不然上面修改的还没有生效) (TODO.. 待优化 -> 频繁的Controller重选举对集群性能会有影响)
zkConfig.deletePath(ZkPathUtil.CONTROLLER_ROOT_NODE);
// 等待 Controller 选举一下
Thread.sleep(1000);
//2. 然后再发起副本重新选举
preferredReplicalElectCommand.preferredReplicaElection(clusterId,topicName,partition,"");
} catch (ConfigException | InterruptedException e) {
LOGGER.error("重新选举异常.e:{}",e);
e.printStackTrace();
}
}).start();
优缺点
优点: 实现了目标需求, 简单, 操作方便
缺点: 频繁的Controller重选举对生产环境来说会有一些影响;
优化与改进
第二种方案中,需要Controller 重选举, 频繁的选举肯定是对生产环境有影响的;
Controller承担了非常多的责任,比如分区副本重分配、删除topic、Leader选举 等等还有很多都是它在干
那么如何不进行Controller的重选举,也能达到我们的需求呢?
我们的需求是,当我们 修改了zookeeper中的节点数据的时候,能够迅速的让Controller感知到,并更新自己的内存数据就行了;
对于这个问题,我会在下一期文章中介绍
问题
看完这篇文章,提几个相关的问题给大家思考一下;
- 如果我在修改zk中的「AR」信息时候不仅仅是调换顺序,而是有新增或者删除副本会发生什么情况呢?
- 如果手动修改
brokers/topics/{topicName}/partitions/{分区号}/state节点里面的leader信息,能不能直接更新Leader? - 副本选举的整个流程是什么样子的?
大家可以思考一下, 问题答案我会在后面的文章中一一讲解!
点个关注, 推送更多 干货 内容, 一起进 【滴滴技术答疑群 】 跟众多技术专家交流技术吧!
从上周五开始决定送书到现在,已经送出去 「 30 」本书了, 又快到周五啦,接着搞, 本周五一口气送
「 8 」本, 提供3款书任选,其中一本是 《分布式一致性算法开发实战》 ,
参与方式:
- 给本文「一键三连」 支持博主
- 扫描下面二维码关注博主,在公众号里面回复 「66」参与抽奖
【编辑推荐】
1.系统:选举、日志和多个高级主题逐步深入讲解。
2.详尽:通过3万行源码和测试,详细分析设计细节及实现难点。
3.生产级:基于Netty的生产级异步IO实现。
4.完整:包含交互式客户端的简易分布式KV服务。

以下三选一

以上是关于Kafka如何修改分区Leader | 文末送书8本的主要内容,如果未能解决你的问题,请参考以下文章