Java集合源码剖析——基于JDK1.8中LinkedList的实现原理
Posted 张起灵-小哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java集合源码剖析——基于JDK1.8中LinkedList的实现原理相关的知识,希望对你有一定的参考价值。
文章目录:
3.10 获取元素的get、getFirst、getLast方法
3.12 push、peek、peekFirst、peekLast方法
3.13 pop、poll、pollFirst、pollLast方法
1.看看关于LinkedList源码开头的注释
* Doubly-linked list implementation of the {@code List} and {@code Deque} * interfaces. Implements all optional list operations, and permits all * elements (including {@code null}). * * <p>All of the operations perform as could be expected for a doubly-linked * list. Operations that index into the list will traverse the list from * the beginning or the end, whichever is closer to the specified index. * * <p><strong>Note that this implementation is not synchronized.</strong> * If multiple threads access a linked list concurrently, and at least * one of the threads modifies the list structurally, it <i>must</i> be * synchronized externally. (A structural modification is any operation * that adds or deletes one or more elements; merely setting the value of * an element is not a structural modification.) This is typically * accomplished by synchronizing on some object that naturally * encapsulates the list.从这段注释中,我们可以得知 LinkedList 是通过一个双向链表来实现的,它允许插入所有元素,包括 null,同时,它是线程不同步的。
- LinkedList集合底层结构是带头尾指针的双向链表。
- LinkedList是非线程安全的。
- LinkedList集合中存储元素的特点:有序可重复,元素带有下标,从0开始,以1递增。
- LinkedList集合的优点:在指定位置插入/删除元素的效率较高;缺点:查找元素的效率不如ArrayList。
如果对双向链表这个 数据结构很熟悉的话,学习 LinkedList 就没什么难度了。下面是双向链表的结构:
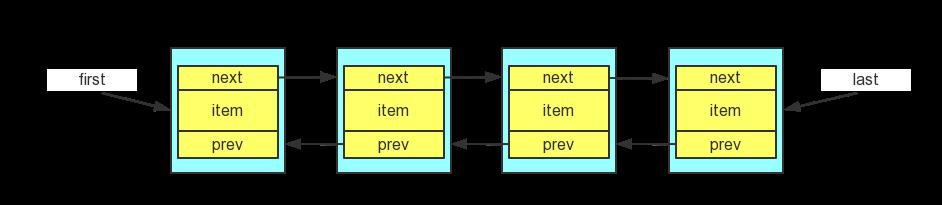
双向链表每个结点除了数据域之外,还有一个前指针和后指针,分别指向前驱结点和后继结点(如果有前驱/后继的话)。另外,双向链表还有一个 first 指针,指向头节点;和 last 指针,指向尾节点。
2.LinkedList中的属性
//双向链表中结点个数
transient int size = 0;
//指向头结点的指针
transient Node<E> first;
//指向尾结点的指针
transient Node<E> last;关于LinkedList中的Node节点结构,它其实是在 LinkedList 里定义的一个静态内部类,它表示链表每个节点的结构,包括一个数据域 item,一个后置指针 next,一个前置指针 prev。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}3.LinkedList中的方法
3.1 push、offer方法
push、offer方法内部都是调用的相应的add方法,所以直接看下面的add方法源码解析。
public void push(E e) {
addFirst(e);
}
public boolean offer(E e) {
return add(e);
}
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
public boolean offerLast(E e) {
addLast(e);
return true;
}3.2 添加元素的一系列add方法
在LinkedList集合源码中,添加元素很多时候都会用到 add、addFirst、addLast 这几个,而查看源码发现,这几个方法的内部实际上都调用了 linkFirst、linkLast 、linkBefore 这三个方法。
public boolean add(E e) {
linkLast(e);
return true;
}
public void addFirst(E e) {
linkFirst(e);
}
public void addLast(E e) {
linkLast(e);
}所以下面着重来说一下 linkFirst、linkLast 、linkBefore 这三个方法。
3.3 linkFirst方法
对于链表这种数据结构来说,添加元素的操作无非就是在表头/表尾插入元素,又或者是在指定位置插入元素。因为 LinkedList 有头指针和尾指针,所以在表头或表尾进行插入元素只需要 O(1) 的时间,而在指定位置插入元素则需要先遍历一下链表,所以复杂度为 O(n)。
而linkFirst表面上翻译就是 链表首位,也就是在表头添加元素,其源码及添加元素分析过程如下:
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}当我们向双向链表的表头插入一个结点 e 时,这个结点的前驱指针肯定是 null,那么在插入之后,这个 e 结点的后继指针是什么呢?(在e插入之前,原先的表头结点就是表头结点,在e插入到原表头的前面成为了新的表头之后,此时原表头结点不就是当前e结点的后继结点了吗?所以e结点的后继指针自然也就指向了原表头结点,所以这里e的后继指针就是最初链表的头指针first),所以要在插入之前先获取到头指针 f = first,然后将头指针对应的结点修改为新插入的结点e(newNode),对应源码的前三行。
而这个if判断的是:如果在插入之前链表的头指针为空(换句话说,当前链表中没有元素,e结点插入之后只有这一个元素),那么此时e结点肯定既是头结点、也是尾结点啊,所以这里将 last 尾结点修改为刚刚插入的 e 结点。
下面的else是说:当前链表中有多个元素了话,当你在某个结点x之前新插入一个结点e,那么结点x的后继部分肯定没有变化,变化的是它的前驱部分,前驱指针所指内容就变成了 新插入的结点e,即 f.prev = newNode。

3.4 linkLast方法
这个方法和 linkFirst 差不多的,无非是一个在表头插入元素,一个在表尾插入元素。
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}首先插入之前,先获取一下原表尾结点的内容(l = last),然后插入新的结点e,这个结点e的后继指针肯定是 null(因为此时它成了链表的表尾结点),而它的前驱指针指向的就应该是上一个表尾结点 l,所以新表尾结点e的内容就是(l,e,null)。然后更新双向链表的尾指针 last 为新插入的结点newNode。
下面的if判断的是:如果在插入之前获取的尾指针 l 为空(也就是说当前链表中没有元素),那么新插入一个元素之后,这个元素肯定既是头结点、也是尾结点,所以这里将它的头指针也更新为 newNode。
else说的是:当插入之前链表中有多个元素,那么在表尾新插入一个元素之后,还要最终修改一下原表尾结点的后继指针,让它指向新的表尾结点。

3.5 linkBefore方法
上面两个方法分别都是在表头、表尾插入元素,那么现在该说一下在中间某个随机位置插入元素的方法了,源码如下:
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}对应源码来说,这里要插入的结点就是 e,e要插入到 succ 结点的前面,同时位于 pred 结点的后面,而在插入之前(succ的前驱就是pred),所以先获取到这个前驱结点 pred,然后修改e结点的内容(pred,e,succ),那么此时 succ 的前驱就变成了 e,所以更新 succ 的前驱指针指向 newNode。
if判断的是:如果插入之前succ结点的前驱指针pred为空,也就是说此时succ是表头结点,那么e插入之后,它就成了新的表头结点,所以这里让first头指针指向newNode。
else则是说插入之前链表中有多个元素,那么在succ指定结点的前面插入新的结点之后,还要修改succ原前驱节点pred的后继指针,使其指向刚插入的e结点newNode。

3.6 移除元素的一系列remove方法
在LinkedList集合源码中,移除元素很多时候都会用到 remove、removeFirst、removeLast 这几个,而查看源码发现,这几个方法的内部实际上都调用了 unlinkFirst、unlinkLast 、unlink 这三个方法。unlink方法中的node方法是对链表进行遍历的。
public E remove() {
return removeFirst();
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}所以下面着重来说一下 unlinkFirst、unlinkLast 、unlink 这三个方法。
3.7 unlinkFirst方法
删除操作与添加操作大同小异,需要把当前节点的前驱节点的后继修改为当前节点的后继,以及当前节点的后继结点的前驱修改为当前节点的前驱。
unlinkFirst方法是在表头进行元素的删除,首先做的是将要删除元素的item值保存到一个临时变量element中,最终返回。同时将要删除元素的后继指针保存到next临时指针中。然后将元素删除(即 f.item=null,f.next=null,因为删除元素位于表头,所以 f.prev 本身就是 null),删除之后链表中的第二个元素就成为了新的表头,所以修改 first 头指针使其指向之前保存的 next 临时指针(头指针指向后一个结点)。
if判断的是:如果next为空,意思是说所删除元素的后继指针如果为空(又因为该方法是在表头进行元素删除),所以此时链表中仅存的这个结点被删除了,那么整个链表就清空了,所以尾指针 last 就为空了。
else说的是:删除之前链表中存在多个元素,那么当头结点被删除之后,原先头结点之后的那个结点就成了新的头结点,所以这个新的头结点的头指针肯定是null,所以 next.prev=null。
最终返回的是被删除元素的item值。
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}3.8 unlinkLast方法
这个方法和上面的差不多,上面的是在表头进行元素的删除,这个是在表尾进行元素的删除。
同样是先保存这个表尾结点的 item 值、prev前驱指针(因为后继指针本身为 null 无需保存),之后将 item、prev 置为 null。当前表尾结点被删除之后,它前面的那个结点就成了新的表尾结点,所以需要将链表的 last 尾指针指向原表尾结点的前驱结点(last=prev)。
if判断的是:如果要删除的表尾结点的前驱为null,则说明此时链表中只有这一个结点,删除之后,链表清空,所以将链表的头指针修改为 null。
else说的是:删除之前链表中有多个元素,将当前表尾结点删除之后,那么它前面的那个结点成了新的表尾结点,所以这个新的表尾结点的后继指针肯定为 null,即 prev.next=null。
最终返回的是被删除元素的item值。
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}3.9 unlink方法
上面两个方法分别是在表头、表尾删除,这个方法则是在链表中的任何一个位置进行元素的删除。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}首先还是先获取要删除元素的item值、next后继指针、prev前驱指针,保存到三个局部变量中。
第一个 if/else:如果前驱指针为null,那么意味着删除的是表头结点,删除之后,新的表头结点为原表头结点的next后继结点,所以将链表的头指针修改指向原表头结点的next后继指针。如果前驱指针不为 null,意味着在链表中间某个位置进行删除操作,需要先修改一下被删除结点的前驱节点的后继指针,使其指向被删除结点的后继指针;之后避免指针冲突,将被删除结点的前驱指针置为null(切断被删除结点的前驱指针这条线)。
第二个 if/else:如果后继指针为null,那么意味着删除的是表尾结点,删除之后,新的表尾结点为原表尾结点的prev前驱结点,所以将链表的尾指针修改指向原表尾结点的prev前驱指针。如果后继指针不为 null,意味着在链表中间某个位置进行删除操作,第一个if/else已经切断了被删除结点的前驱线路,这里还需要修改一下被删除结点的后继节点的前驱指针,使其指向被删除结点的前驱指针;之后避免指针冲突,将被删除结点的后继指针置为null(切断被删除结点的后继指针这条线)。最后将被删除结点的item值也置为null。
最终返回的是被删除元素的item值。

3.10 获取元素的get、getFirst、getLast方法
在LinkedList集合源码中,获取元素很多时候都会用到 get、getFirst、getLast 这几个。
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}getFirst方法:获取双向链表中的第一个元素。首先就是拿到当前链表的头指针所指向的头结点,如果为空,则抛出没有这个元素异常;不为空直接就返回表头结点的item值。
getLast方法:获取双向链表中的最后一个元素。首先就是拿到当前链表的尾指针所指向的尾结点,如果为空,则抛出没有这个元素异常;不为空直接就返回表尾结点的item值。
而在get方法的源码中,第一行所做的是进行集合下标是否越界的判断,这里不再多说了。主要是它第二行调用了一个node方法,源码如下:👇👇👇
因为get方法是随机的获取链表中的一个元素,下标为index,那么这个node方法就是帮助get方法完成了对链表的遍历过程。如果获取元素的索引下标小于链表长度/2,则从表头开始遍历,每遍历一次就修改一下当前结点的后继指针,直到遍历到指定元素为止;反之则从表尾开始遍历,每遍历一次就修改一下当前结点的前驱指针,直到遍历到指定元素为止。
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}3.11 size方法
返回双向链表的大小(元素个数)。
public int size() {
return size;
}3.12 push、peek、peekFirst、peekLast方法
这三个方法就是获取双向链表中的第一个元素、最后一个元素。(这源码分析好理解,我就不再多说了)
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}3.13 pop、poll、pollFirst、pollLast方法
pop方法内部调用了removeFirst方法,而removeFirst方法内部调用了unlinkFirst方法。
这三个方法poll、pollFirst、pollLast就是移除双向链表中的第一个元素、最后一个元素。它们的方法内部实际上就是调用了unlinkFirst、unlinkLast方法,上面已经说过了。
public E pop() {
return removeFirst();
}
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
3.14 set方法
这个方法非常简单,就是替换指定索引下标位置的元素的item值,同时返回它的旧值。
首先还是进行链表下标是否越界的判断,然后调用node方法对链表进行遍历(查找到要替换的那个元素结点),找到之后将该结点的item值保存一下,然后替换,最后返回该结点的旧值。
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}3.15 contains方法
判断集合中是否包含某个元素,如果包含在indexOf方法中返回对应的索引下标,在contains方法中返回相应的布尔值。
public boolean contains(Object o) {
return indexOf(o) != -1;
}public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}3.16 clear方法
清空集合中的全部元素。从双向链表的头指针开始遍历,每遍历一次,首先获取当前结点的后继指针指向的结点,然后将当前结点的三要素(前驱、值、后继)置为null,然后更新遍历中心元素为下一个结点next,直至遍历结束。最后链表清空,就将头指针first、尾指针last修改为null,长度size清零。
public void clear() {
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}以上是关于Java集合源码剖析——基于JDK1.8中LinkedList的实现原理的主要内容,如果未能解决你的问题,请参考以下文章