SQL Server 堆heap 非聚集索引 Nonclustered index 行号键查找RID loopup结合执行计划过程详解
Posted ShenLiang2025
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL Server 堆heap 非聚集索引 Nonclustered index 行号键查找RID loopup结合执行计划过程详解相关的知识,希望对你有一定的参考价值。
SQL Server 堆型数据与执行计划使用案例
索引的相关术语
1 堆(Heap)是一种没有指定排序的数据结构,通俗的理解堆就像是按照顺序排放的杂物。在数据库里也即是对应没有聚集索引。
2 聚集索引:一个表只有一个聚集索引且数据存放在聚集索引内。
3 非聚集索:是一个B-树(B-Tree)结构,它包含了索引键和指向数据行的指针。
我们可以在堆或聚集索引类型的表里创建非聚集索引。一个表的非聚集索引最多支持999个。在覆盖索引的应用场景下,可以定义非聚集索引时指定包含(include)其它字段。
4 唯一索引:唯一索引不允许表里的指定的列数据有重复的值,一个表可以有一个或多个唯一索引。
5 主键:主键是一个表里每行记录的唯一标识同时默认情况下也是聚集索引。
6 RID lookup 堆形式的表的执行计划里通过ROW id映射匹配其它非聚集索引字段的操作。
堆的演示案例
建立验证表
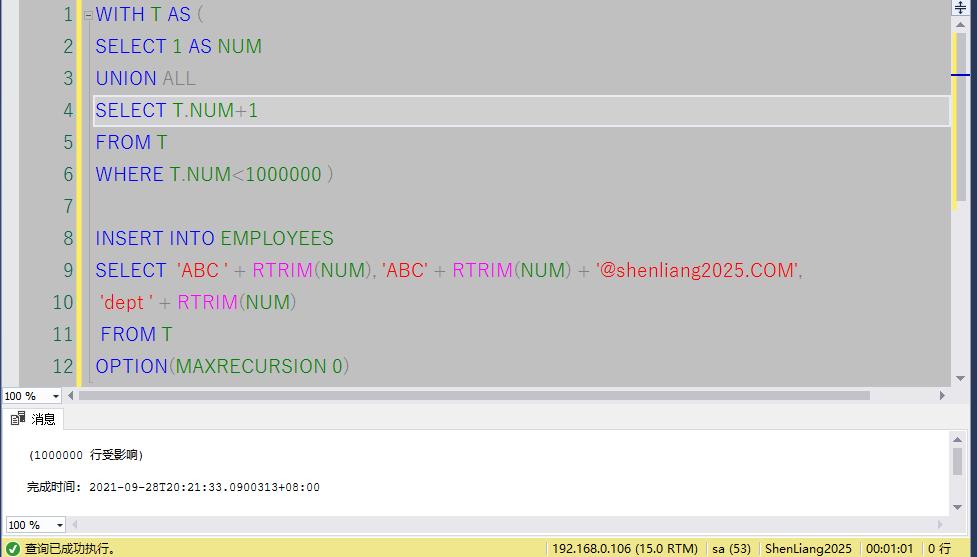
借助CTE插入100万条记录到EMPLOYEES表。
USE ShenLiang2025
GO
CREATE TABLE EMPLOYEES
(
id INT IDENTITY,
name NVARCHAR(50),
email NVARCHAR(50),
dept NVARCHAR(50)
)
GO
WITH T AS (
SELECT 1 AS NUM
UNION ALL
SELECT T.NUM+1
FROM T
WHERE T.NUM<1000000 )
INSERT INTO EMPLOYEES
SELECT 'ABC ' + RTRIM(NUM), 'ABC' + RTRIM(NUM) + '@shenliang2025.COM',
'dept ' + RTRIM(NUM)
FROM T
OPTION(MAXRECURSION 0)
系统表查看当前表的类型
SELECT * FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.EMPLOYEES') 
无索引下WHERE查询
--查询名字是ABC 874000的员工信息。
-- 执行时点击SSMS里的“包括实际的执行计划按钮”菜单(或者用CTRL+M快捷键)。
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'
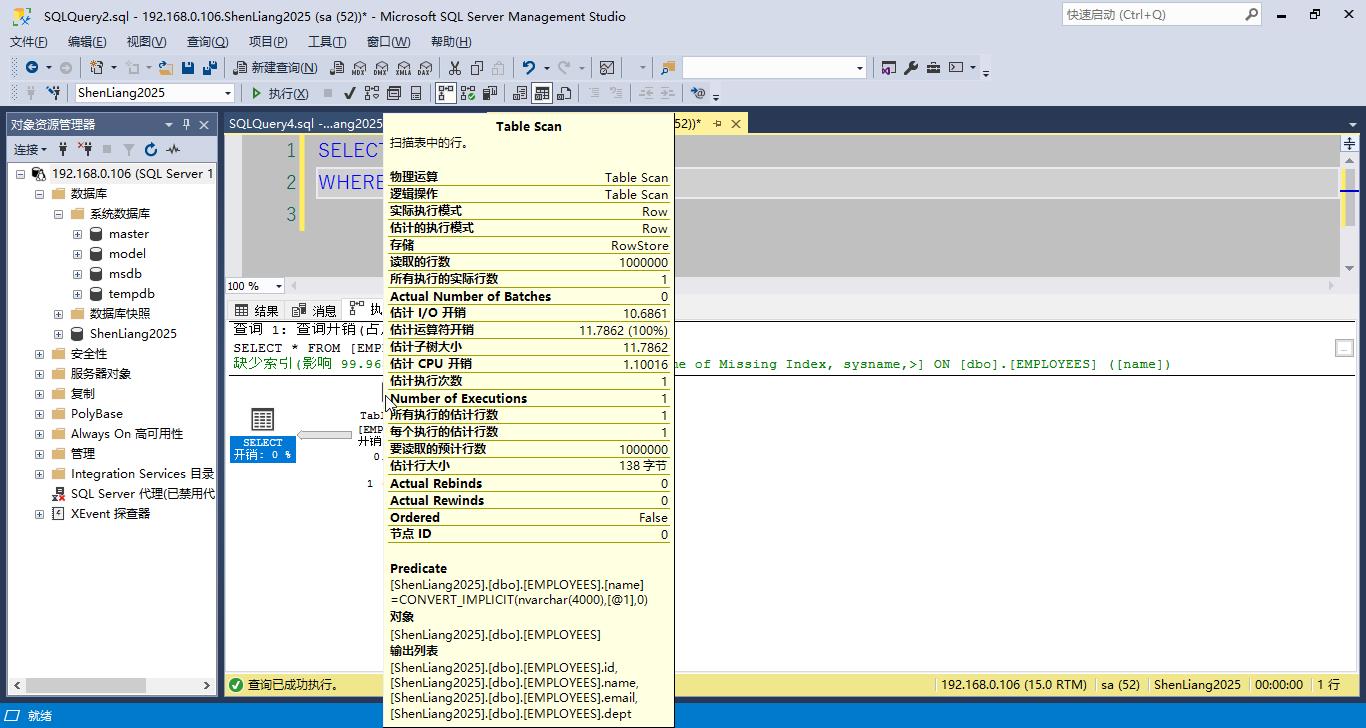
通过分析实际的执行计划不难发现,在堆情况下的表里应用WHERE查询1条记录时需要遍历表里所有的所有记录(这里是100万条)。
非聚集索引下WHERE查询
--在NAME字段上建立非聚集索引。
CREATE NONCLUSTERED INDEX IX_EMP_NAME ON EMPLOYEES(NAME)
-- 再次执行WHERE查询并含实际执行计划。
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'
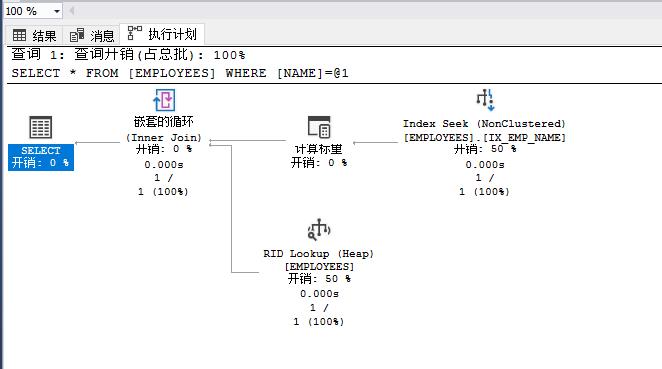
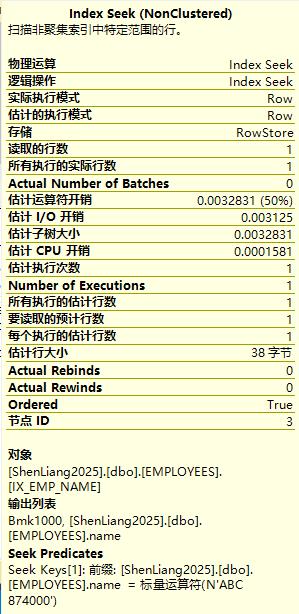
可见在index seek下读取的行数和所实际执行的行数都是1,而且估计子树大小为0.0032831相对于上例的11改进巨大。
RID映射查找
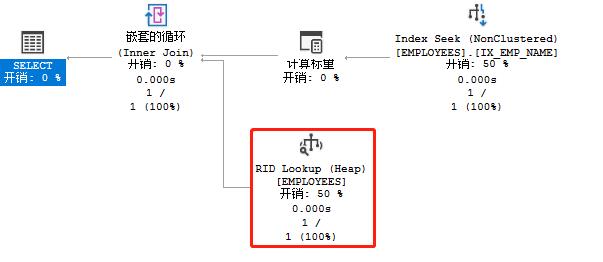
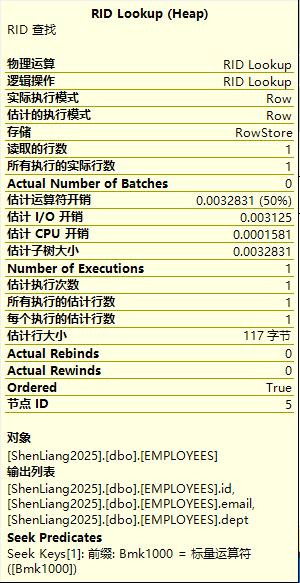
上例的执行计划中我们可以看到RID lookup过程,这个映射查找出现的原因是我们的查询里name字段虽然可以在非聚集索引IX_EMP_NAME上直接获取到,但id、email、dept而这些信息则需要通过Row ID来映射匹配到。
注:非聚集索引在建立时已经有name字段和Row ID的匹配信息。
RID lookup示意
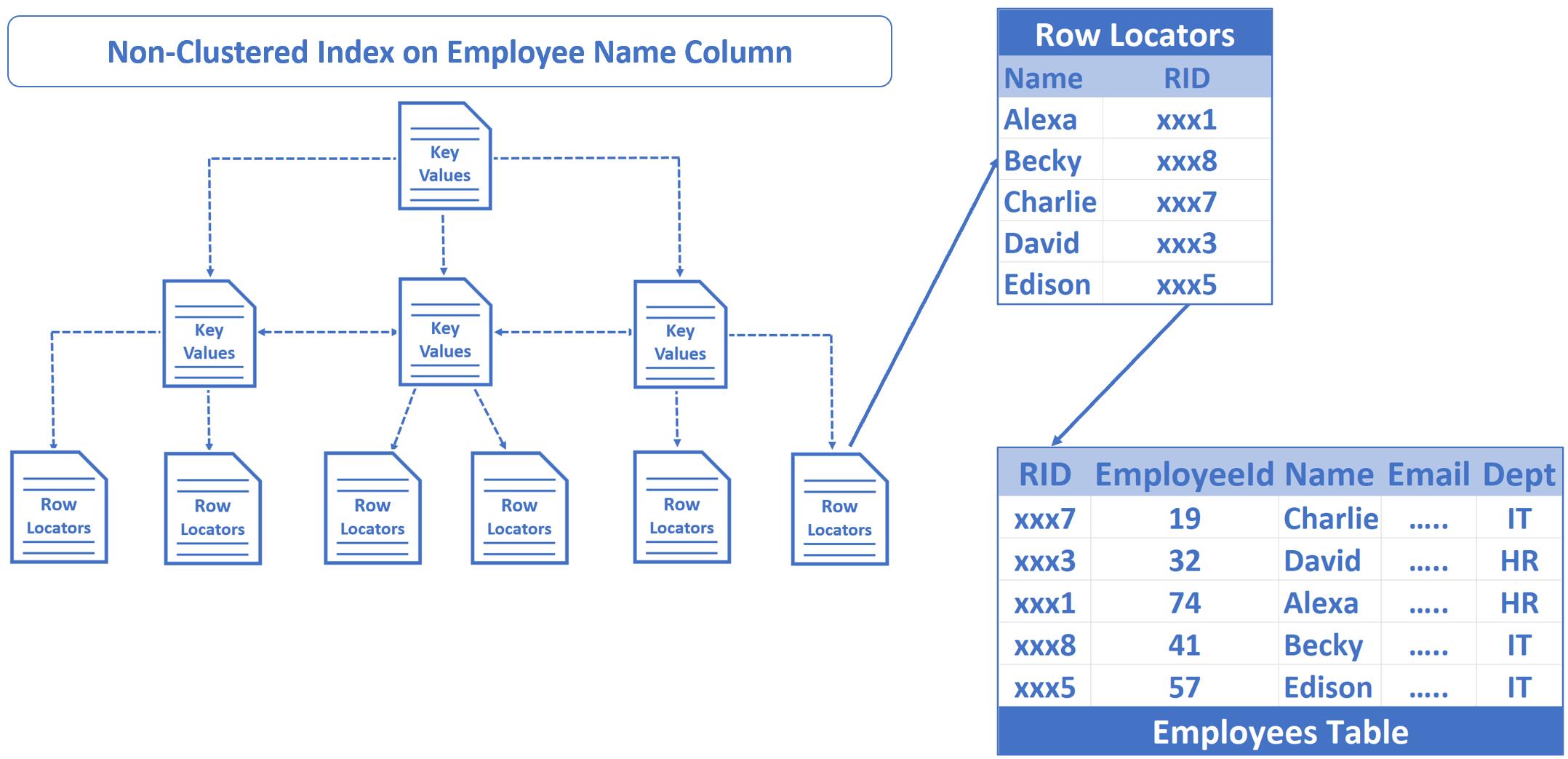
以上是关于SQL Server 堆heap 非聚集索引 Nonclustered index 行号键查找RID loopup结合执行计划过程详解的主要内容,如果未能解决你的问题,请参考以下文章