MaxCompute 存储设计
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MaxCompute 存储设计相关的知识,希望对你有一定的参考价值。
简介: 存储策略该怎么设计
写这篇存储规划的文章主要是想告诉大家该如何给存储做一个规划,在关系数据库的时代存储昂贵且珍惜,掰手指头花钱是存储规划的常态。但是到了大数据时代大家又立即就都变成印美元的美国政府了,感觉存储很多可以随意霍霍,但是又不停的求国会再提升政府债务上限。反而造成了一种日子过的还不如关系数据库的感觉,至少是看着人家没有我们这么焦灼和水深火热。怎么就让我们动则以PB计算的大数据产品,日子过的比论GB过日子的关系数据库还惨呢?
公共云费用测算
在公有云,MaxCompute为了吸引新用户去了解和使用产品,实际上做到了1元钱学习MaxCompute和DataWorks的效果,学习使用成本非常低,账户充值10块钱都能随便畅游这两款产品1年。所以,我们要看下真正的用户收费是什么样子的。
l 套餐资源
链接:套餐计费(包年包月) - MaxCompute - 阿里云
套餐包含计算资源和存储资源,如下表所示。
| 无限制,按量付费 |
l 套餐价格
| 0.8 |
l 存储费用测算
根据上表我们做一个简单测算。使用160CU的规格存储为150TB的套餐,超出100TB时每天的费用是0.019元*1000GB*100TB=1900元,每月费用是57000元,大于套餐包价格35000元。
存储爆炸原因
从上面的例子我们可以看到,假设在计算资源够用的情况下,存储的增加带来的成本的上升是难以承受的。而且计算是跟业务需求强关联,如果没有新的业务需求,每天处理数据的量不会大幅变化,但是批量系统每天都会产生新一天的数据。
假设我们使用MaxCompute集成一个大小为100G的交易型系统的数据库,数据加工的时效是T+1,会有两方面因素导致数据存储的膨胀。
1. 快照表。快照表是指MaxCompute的表的每一个分区的数据都是业务系统对应的表的一份镜像。按照集成频次T+1,一个100G的业务系统每天在MaxCompute存储一份快照,一年的存储要求是(365*100G)36.5TB。
2. 分层架构。按照一般数据仓库的分层架构,至少会分为3层,镜像层、中间层、应用层。数据入仓后每上升到一个新的分层,数据都会被复制一份。尤其是到了应用层,不同的应用会多份复制数据进行个性加工。我们暂且拍一个比较保守的比例:1:1:1,那么每年对存储的需求就增加到了36.5*3=100TB。
所以,通过上面的测算我们得到了一个非常简单的换算(合理但是可能不够精确),如果使用MaxCompute集成一个存储规模为100GB的业务系统,采用T+1频次计算,那么我们每年需要的存储空间是源系统的1000倍(也是就说100GB变成了100TB)。
存储设计
通过上面部分的分析,我们知道了快照表的存储模式是导致数据被复制了很多份的最大的原因。1行1年内没有更新的记录使用快照存储,会被复制365份。那么为什么数据仓库ETL过程会大量使用快照表呢?总的来说就是结构简单好用,适合ETL加工。
杜绝快照表是不可能的,那就需要思考如何设计存储。存储优化有两个方向,第一个方向就是压缩,第二个方向是清理。
数据清理
数据清理比较简单,重要的是把不需要的数据及时清理掉。数据清理的方法有:
1. 业务下线。已经不再使用的应用层数据表,是否可以清理下线。
2. 自动回收。利用lifecycle设定分区的失效时间,系统后台自动回收。
ALTER TABLE table_name SET LIFECYCLEDAYS;
ALTER TABLE table_name partition[partition_spec]ENABLE|DISABLE LIFECYCLE;
3. 主动管理。一般用于生产环境管控,不同的层次采取不同的策略,例如存储最近N天+月末时点快照。主动管理使用自定义脚本的方法定时清理不需要的数据分区。还有主动管理可以对开发环境或者一些项目空间设置存储上限,引导开发人员去设计和管理存储。要求临时表使用完就立即释放。
4. 重复存储。一些数据表只是一个中间结果集,并没有长期存储的必要,可以建议开发人员使用视图或者临时表替代或者减少不必要的历史存储周期。
数据清理会删除一部分分区的数据,这也代表着一部分时间的快照的状态被从历史中清除了。T+1的批量会记录每行数据每天的最后一个状态,但是如果保留策略是月末+最近N天,那么最后我们能从历史数据中获取到的数据状态就是每月的最后一个状态。
这种情况下,历史数据清理到什么程度,是需要一个业务指导。还有建议在数仓分层架构的最下面的层次对历史数据进行保留。
以清理策略为“保留月末+最近10天”的数据存储需求为例,一年的存储需求从100TB裁剪到100GB*(12个月+最近10天)*3层=6.6TB,变成了原来策略的1/15。原来160CU规格的存储150TB,可以让存储为100GB业务系统的数据存储1.5年,现在则变成了20年。
数据压缩
数据压缩是指利用产品自带的存储压缩特性,或者利用拉链表结构压缩存储。
l 在当前表上进行压缩
1. 归档。将存储比从1:3提高到1:1.5,可以节省一半的物理空间,同时也采用了更高压缩比的压缩算法。
alter table my_log partition(ds='20170101') archive;
如果启用归档策略,对历史数据进行归档。我们可以看到存储会在原有基础上缩小一半。可以让每年100TB存储需求,减少为50TB。
l 备份到另外一张表
1. 分区合并。对于一些数据量非常小的表,历史数据的备份存储可以采用把一个区间内所有数据合并到一个分区的方法来优化存储(主要还是优化小文件)。
2. 拉链表。拉链表是传统数仓得以运转的核心数据存储方法,在MaxCompute上仍然可以使用这个方法。拉链算法的核心是让每条记录的每个状态变化都保存为1行记录,而不是快照表的N份,这种方法能大量节约存储资源。
如果启用拉链表策略,数据存储可以认为与源系统基本持平,只是需要计算分层复制。一年的存储需求从100TB裁剪到100GB*1天*3层=0.3TB,变成了原来策略的1/300。原来160CU规格的存储150TB,可以让存储为100GB业务系统的数据存储1.5年,现在则变成了500年。(这个计算过于理想化,因为ETL过程都主要使用快照表来实施,所以,只能对暂时不需要使用的历史数据备份)。
备份就相当于表结构与原来不一致了,会发生变化。所以,访问历史数据需要使用与快照表不一样的方法。
拉链表链接:基于MaxCompute的拉链表设计-阿里云开发者社区
压缩对比
快照表与拉链表
拉链表与快照表比较起来有更低和更合理的存储特性。
快照表与拉链表结构对比如下:
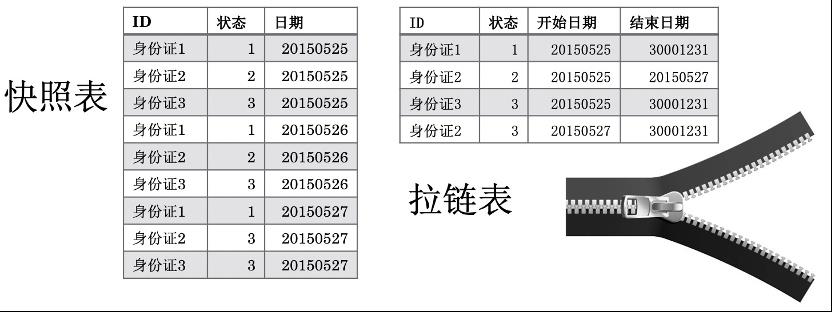
• 拉链表的每个主键在存储周期的所有时点,一个状态只存储了一行数据。
• 快照表的每个主键在存储周期的所有时点,每个时点都会存储一行数据。
从上面的比较可以看出来,使用快照表存储数据,每个MaxCompute的数据分区都会存储一份数据,而拉链表只存储了一份数据。看起来存储大小对比是N:1,N就是快照表的分区个数,而1就是1个最新快照表的分区大小。
拉链表的压缩比
下面是根据实际数据测算的两种数据表的压缩比,一种是记录增长率低的表,另外一种是记录增长率高的表。对比发现,使用拉链表存储后一月的数据大约都只是1天数据的1倍左右。
A表:记录增长率低表【用户信息】
日期:20170501-20170531
天数:31天
| TA | 记录数 | 存储 | 文件数 |
| 原始 | 1.6亿 | 58.18GB | 171 |
| 原始/合并 | 1.6亿 | 48.94GB | 59 |
| 拉链 | 600万 | 2.36GB | 47 |
| 压缩比 | 26.02 | 20.75 | 1.26 |
B表:记录增长率高表【交易日志/事件表】
日期:20170501-20170531
天数:31天
| TB | 记录数 | 存储 | 文件数 |
| 原始 | 49亿 | 447.90GB | 3596 |
| 原始/合并 | 49亿 | 447.90GB | 1111 |
| 拉链 | 1.6亿 | 15.10GB | 31 |
| 压缩比 | 30.74 | 29.67 | 35.84 |
存储归档的压缩比
如果Project里的空间比较紧张,需要进行数据删除或数据压缩,可以考虑MaxCompute里对表的Archive功能,效果是可以将存储空间压缩50%左 右。Archive功能将数据存为Raid File,数据不再简单的存三份,而是6份数据+3份校验块的方式,这样有效的将存储比从1:3提高到1:1.5,可以节省 一半的物理空间,同时也采用了更高压缩比的压缩算法。 上述的操作也是有代价的,如果某个数据块损坏或某台机器损坏,恢复数据块的时间要比原来的方式更长,读的性能也会有一定损失。所以现在这种功能可以用在一些冷数据的压缩存储上,例如一些非常大的日志数据,超过一定时间期限后使用的频率非常低,但是又需要长期保存,则可以考虑用 Raid File来存储。
实际使用测算效果如下:
| 显示存储 | 实际存储 | 份数 |
| 447.90GB | 1343.69GB | 3.0 |
| 328.33GB | 492.49GB | 1.5 |
总结
通过以上介绍,我们了解到了常用的存储方案,了解到了快照表、拉链表和存储压缩和历史数据清理的方法。相信大家心里已经有了一定的想法,该怎么去规划和设计我们的存储策略。
再有存储与计算是有一定的换算关系,压缩需要计算资源,没有计算资源,存储缩减的方法就只有一条:删除数据。一般批量系统都是夜间运行,所以,可以把压缩存储的任务安排在白天执行。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于MaxCompute 存储设计的主要内容,如果未能解决你的问题,请参考以下文章