英伟达新研究:不用动捕,直接通过视频就能捕获3D人体动作|ICCV 2021
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英伟达新研究:不用动捕,直接通过视频就能捕获3D人体动作|ICCV 2021相关的知识,希望对你有一定的参考价值。
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
不靠昂贵的动捕,直接通过视频也能提取3D人体模型然后进行生成训练:


英伟达这项最新研究不仅省钱,效果也不错——
其合成的样本完全可以用在以往只在动捕数据集上训练的运动合成模型,且在合成动作的多样性上还能更胜一筹。
成果已被ICCV 2021接收。

四个步骤从视频获得人体模型
下图概述了英伟达提出的这个从视频中获得动作样本的框架。
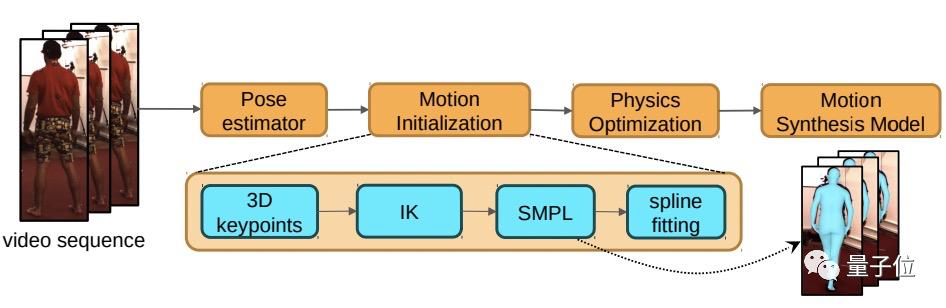
包含4步:
1、首先输入一个视频,使用单目姿势预估模型(pose estimator)生成由每帧图像组成的视频序列。
2、然后利用反向动力学,用每帧的3D关键点形成SMPL模型动作。
SMPL是一种参数化人体模型,也就是一种3D人体建模方法。
3、再使用他们提出的基于物理合理性的修正方法来优化上述动作;
4、 使用上述步骤处理所有视频,就可以使用获得的动作代替动捕来训练动作生成模型了。
概括起来就是用输入视频生成动作序列,然后建模成3D人体,再进行优化,最后就可以像使用标准动作捕捉数据集一样使用它们来训练你的动作生成模型。
下面是他们用该方法生成的一个样本合集:

具体效果如何?
研究人员对比了该方法与一些动捕模型,比如最新的PhysCap等。
PhysCap,一款基于AI算法的单目3D实时动捕方案。
结果发现,他们的方法在平均关节位置(MPJPE)的误差低于PhysCap。

其中的基于物理的修正方法更是将样本的脚切线速度误差降低40%以上,高度误差降低80%。

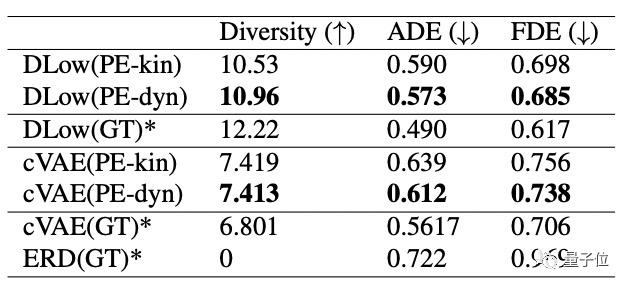
那用这些样本来训练生成模型的效果如何呢?
他们使用3个不同的训练数据集训练相同的DLow模型。
DLow(GT)是使用实际动捕数据进行训练的人体运动模型。
DLow(PE-dyn)是他们提出的方法,使用物理校正后的姿势训练。
DLow(PE-kin)也是他们的方法,没有优化过动作。
结果是DLow(PE-dyn)模型的多样性最好,超越了动捕数据集下的训练。
但在最终位移误差(FDE)和平均位移误差(ADE)上略逊一筹。
最后,作者表示,希望这个方法继续改进成熟以后,能够非常强大地利用身边的在线视频资源为大规模、逼真和多样的运动合成铺平道路。
作者信息
Xie Kevin,多伦多大学计算机专业硕士在读,也是英伟达AI Lab的实习生。

王亭午,多伦多大学机器学习小组博士生,清华本科毕业,研究兴趣为强化学习和机器人技术,重点集中在迁移学习、模仿学习。

Umar Iqbal,英伟达高级研究科学家,德国波恩大学计算机博士毕业。

后面还有其他3位来自多伦多大学和英伟达的作者,就不一一介绍了。
论文地址:
https://arxiv.org/abs/2109.09913
参考链接:
https://nv-tlabs.github.io/physics-pose-estimation-project-page/
以上是关于英伟达新研究:不用动捕,直接通过视频就能捕获3D人体动作|ICCV 2021的主要内容,如果未能解决你的问题,请参考以下文章
英伟达新显卡 RTX 3080Ti参数曝光 拥有24GB显存
英伟达新核弹GPU:4nm制程800亿晶体管,20张即可承载全球互联网流量,全新Hopper架构太炸了...
英伟达新核弹GPU:4nm制程800亿晶体管,20张即可承载全球互联网流量,全新Hopper架构太炸了...