Python爬虫--高性能的异步爬虫
Posted 胜天半月子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫--高性能的异步爬虫相关的知识,希望对你有一定的参考价值。
文章目录
文章知识点
- 单线程、多线程
- 线程池
- 单协程、多协程
- headers中Refere的作用
- 异步模块aiohttp使用
一、异步爬虫概述
高性能异步爬虫 :在爬虫中使用异步实现高性能的数据爬取操作
传统爬取数据的操作是顺序操作,下面看一个实例
- 代码
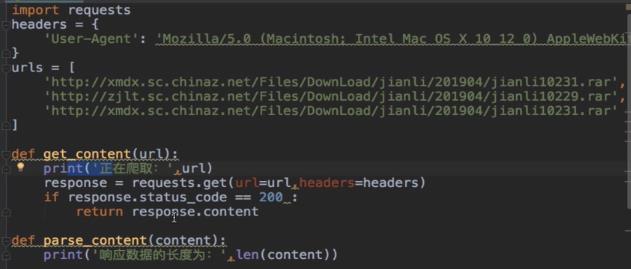

分析上述代码可知 for循环中的get方法会阻塞程序,只有请求到的数据获取后,才可以进行下一条url中对应的数据
上述可知,使用异步会提高爬虫程序的数据获取效率
- 异步爬虫的方式
- 多线程,多进程
好处:可以为相关阻塞的操作单独开启线程或进程,阻塞操作就可以异步进行
弊端:无法无限制的开启多线程或者多进程- 线程池、进程池(适当的使用)
好处:我们可以降低系统对进程或者线程创建和销毁的一个频率,从而很好的降低系统的开销
弊端:池中线程或进程的数量是有上限的。
二、线程池的基本使用
- 单线程串行方式使用
import time
# 单线程串行方式运行
def get_page(str):
print("正在下载:",str)
time.sleep(2)
print("下载成功:",str)
name_list = ['xiaozi','aa','bb','cc']
start_time = time.time()
for i in range(len(name_list)):
get_page(name_list[i])
end_time = time.time()
print('%d second' % (end_time - start_time))
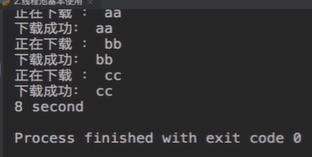
- 线程池的使用
import time
# 导入线程池模块对应的类
from multiprocessing.dummy import Pool
# 使用线程池方式执行
# Pool一定是应用在阻塞操作中的 get_page
start_time = time.time()
def get_page(str):
print("正在下载:",str)
time.sleep(2)
print("下载成功:",str)
name_list = ['xiaozi','aa','bb','cc']
# 实例化一个线程池对象
pool = Pool(4) # 4个线程对象
# 将列表中每一个列表元素传递给get_page进行处理
# pool.map的返回值就是方法get_page()的返回值
pool.map(get_page,name_list)
end_time = time.time()
print(end_time-start_time)
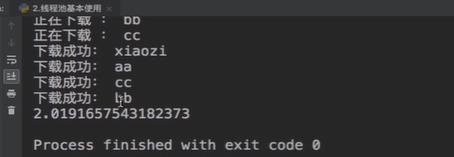
三、异步爬取线程池案例使用⭐⭐
本例爬取梨视频网站:梨视频官网

以上视频是我们需要爬取的具体视频,键盘上F12查看并且分析相关的detail_url和name,
- 信息分析
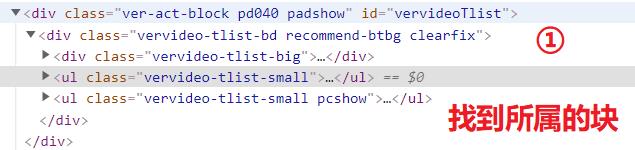
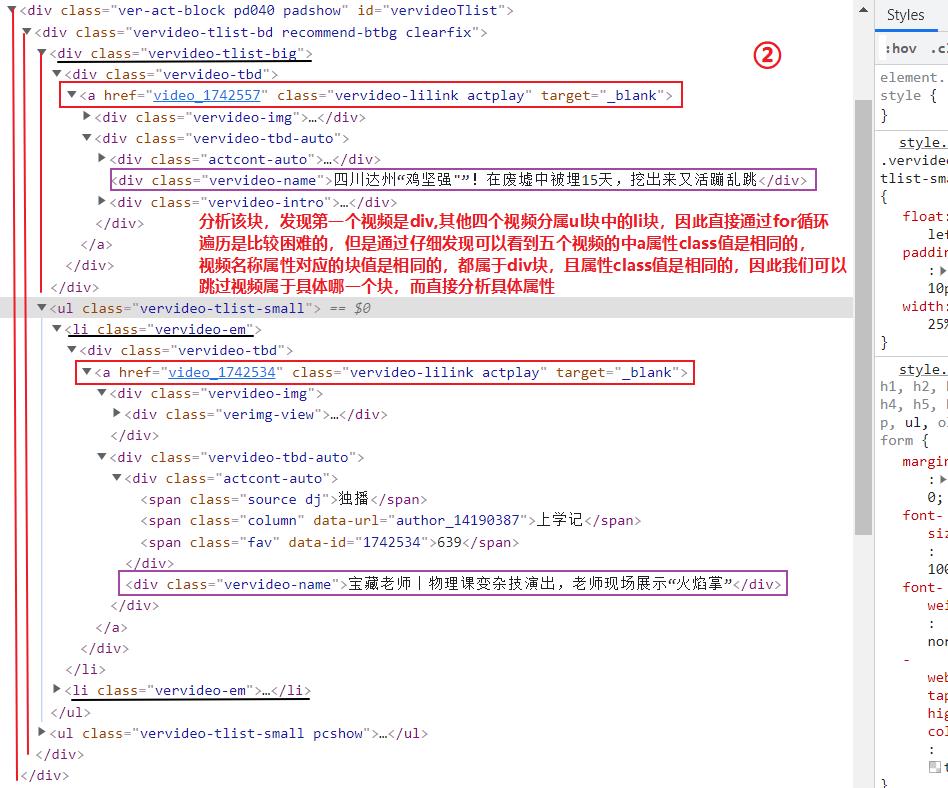
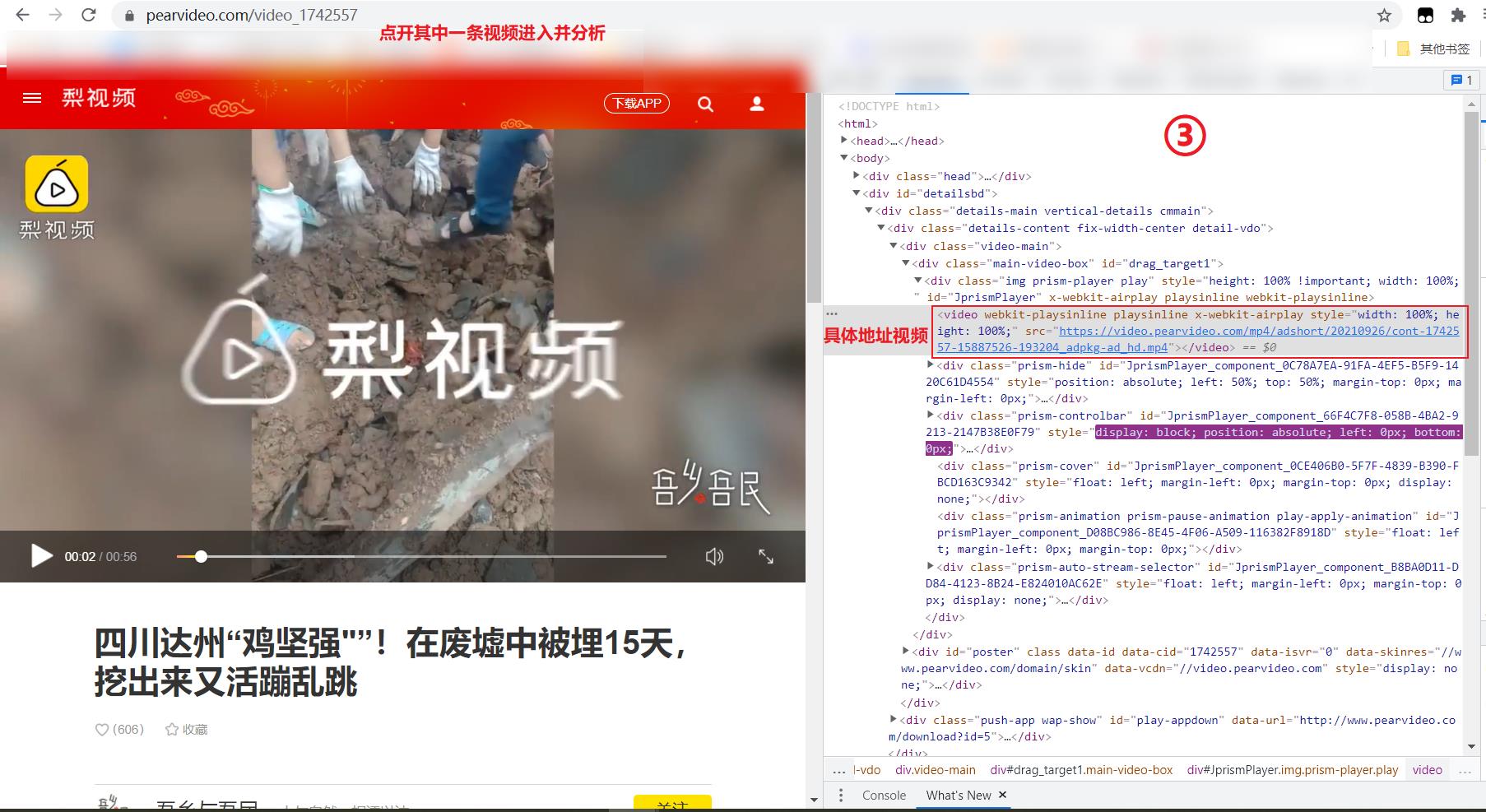
到此你可能认为使用xpath进行地址获取下载即可,但是这样就错了,你使用etree进行解析出来的是空值,因为这个页面的有些数据就是动态加载出来的,如下进行验证:
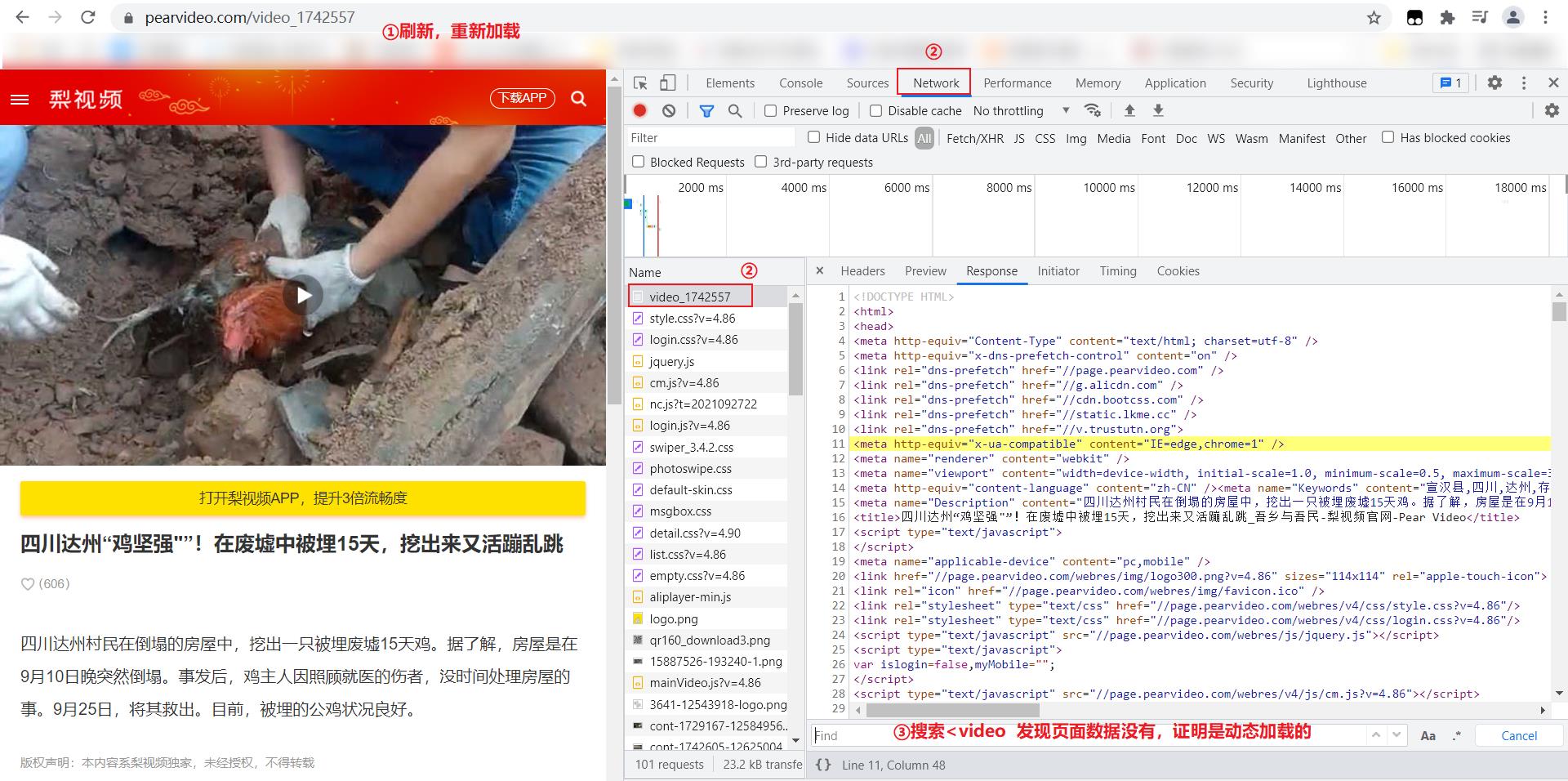
到此为止,我们发现数据是动态加载出来的,因此我们就需要找出真正要下载的地址链接在哪里?
在此感谢这两位博主提供的思路:
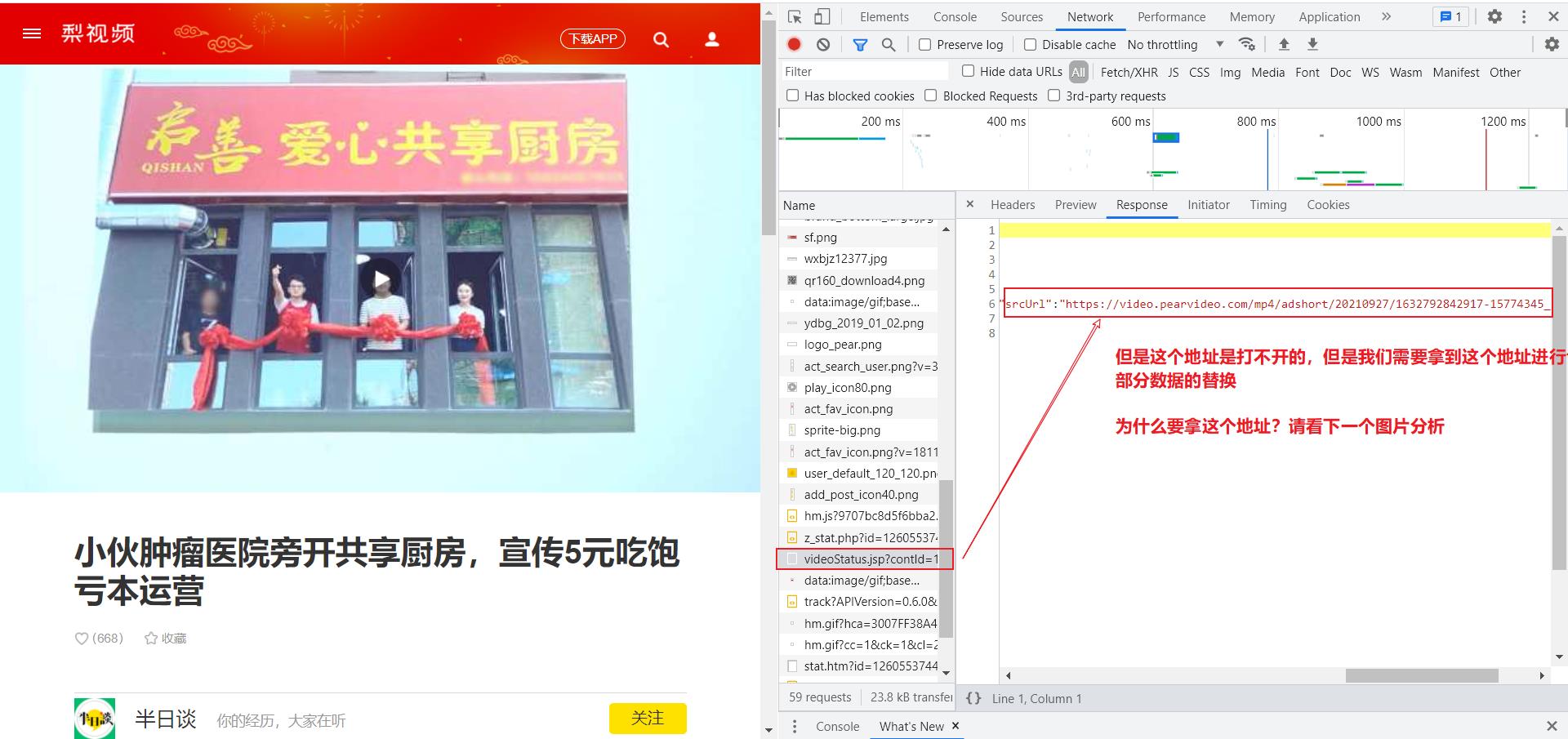
- 地址信息对比
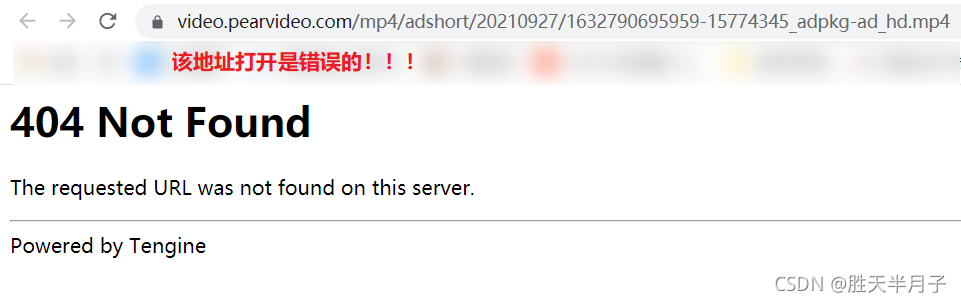
- 报错404:
https://video.pearvideo.com/mp4/adshort/20210927/1632790695959-15774345_adpkg-ad_hd.mp4- 正确的路径:
https://video.pearvideo.com/mp4/adshort/20210927/cont-1742572-15774345_adpkg-ad_hd.mp4
此外多次实验发现获取报错404地址的网址有一部分数字是随机产生的,
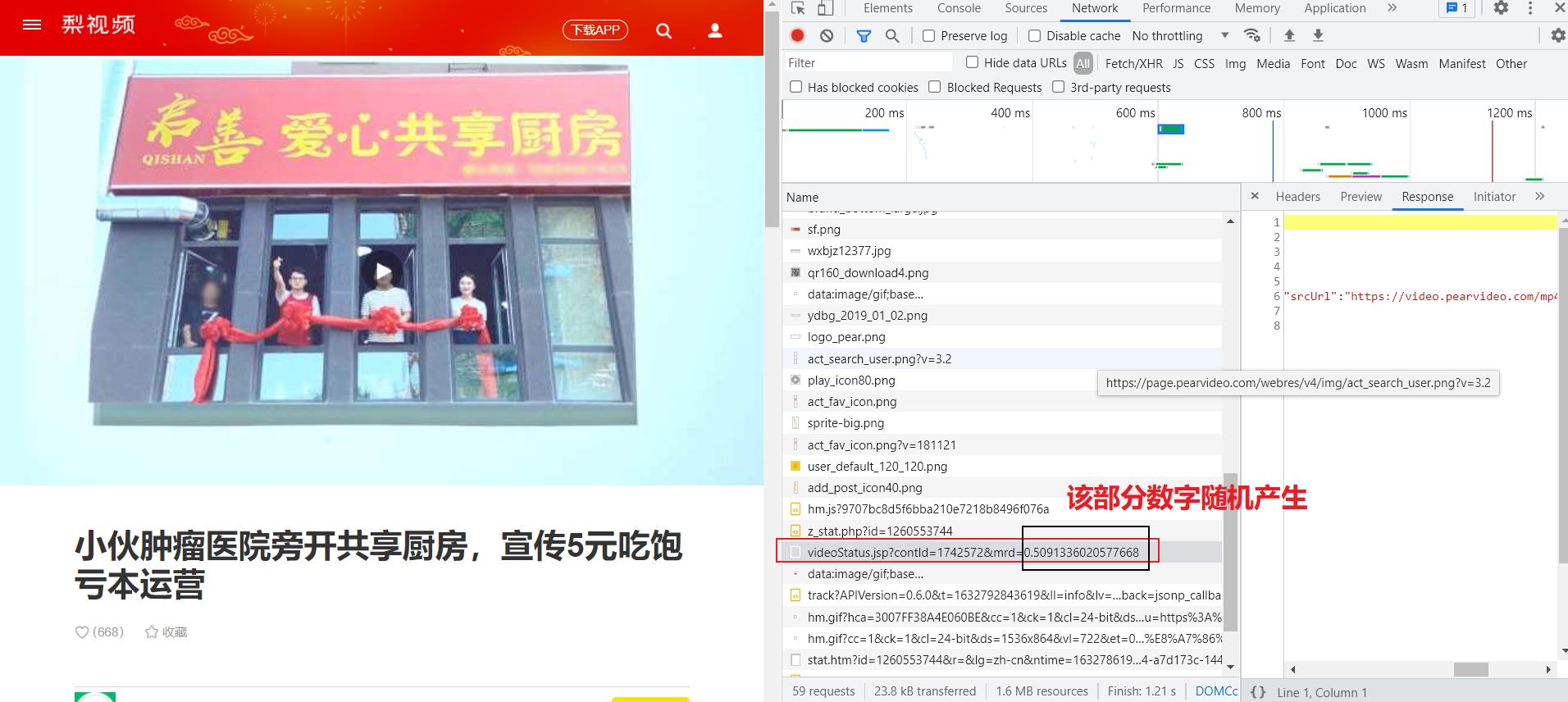
- 真实信息地址
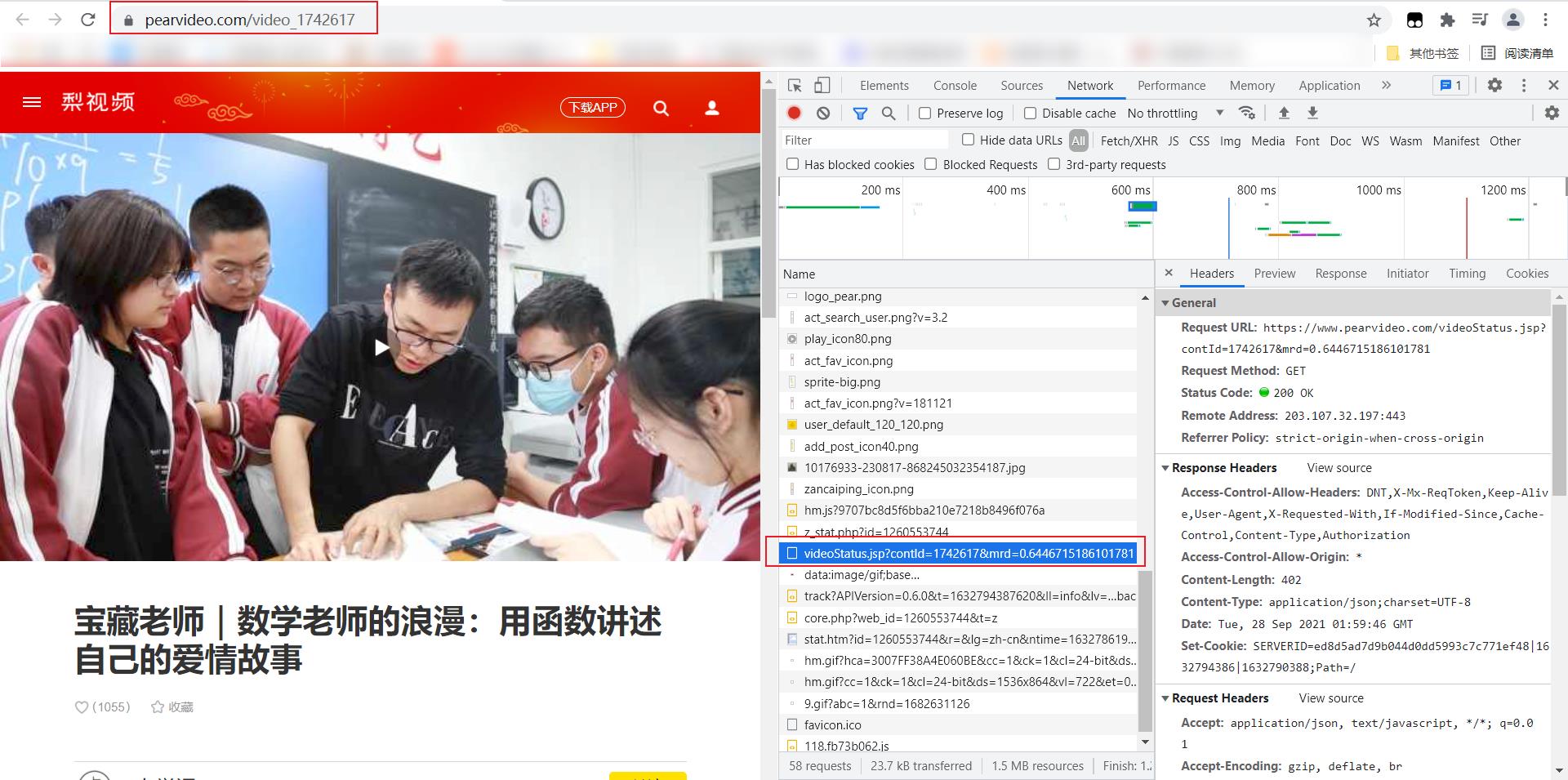
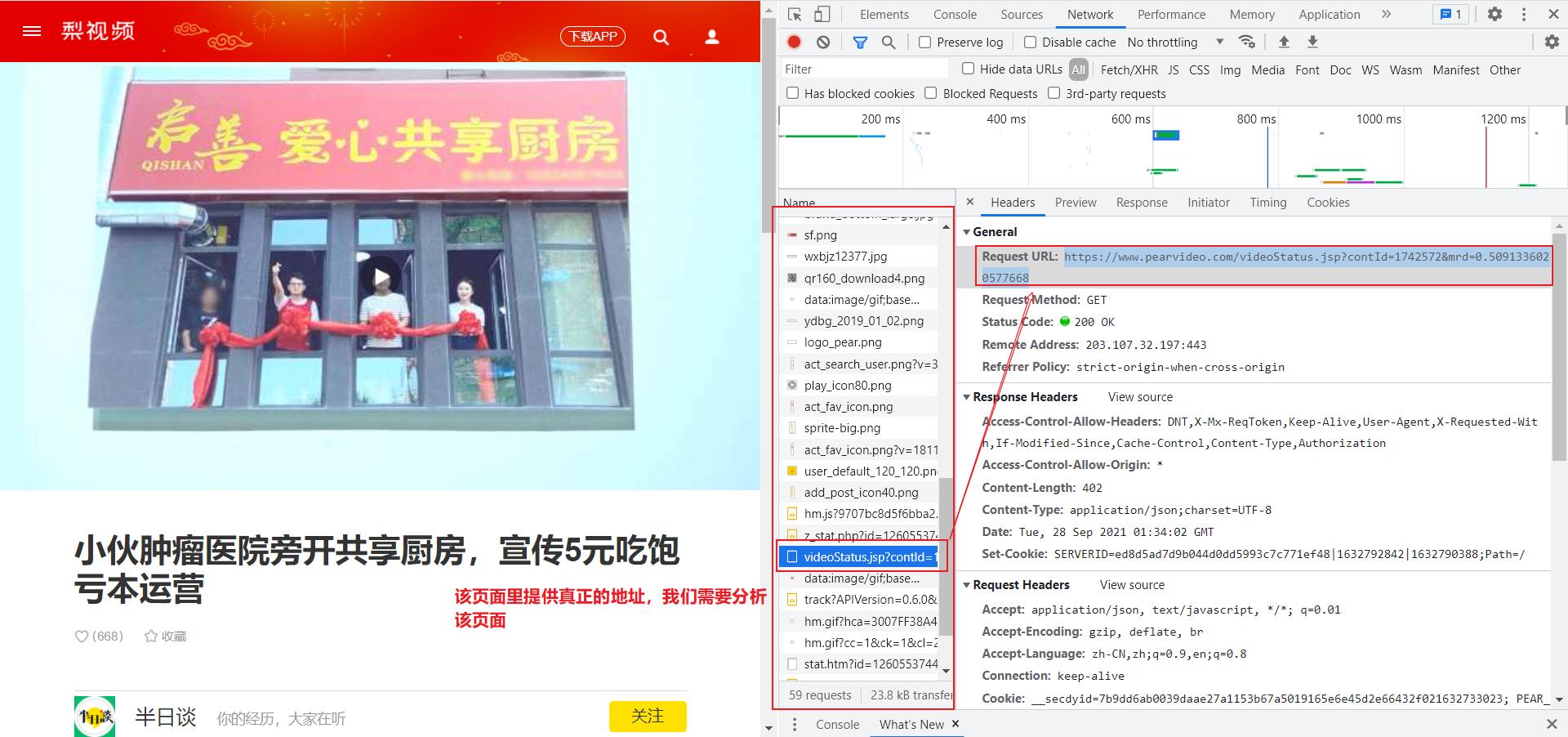
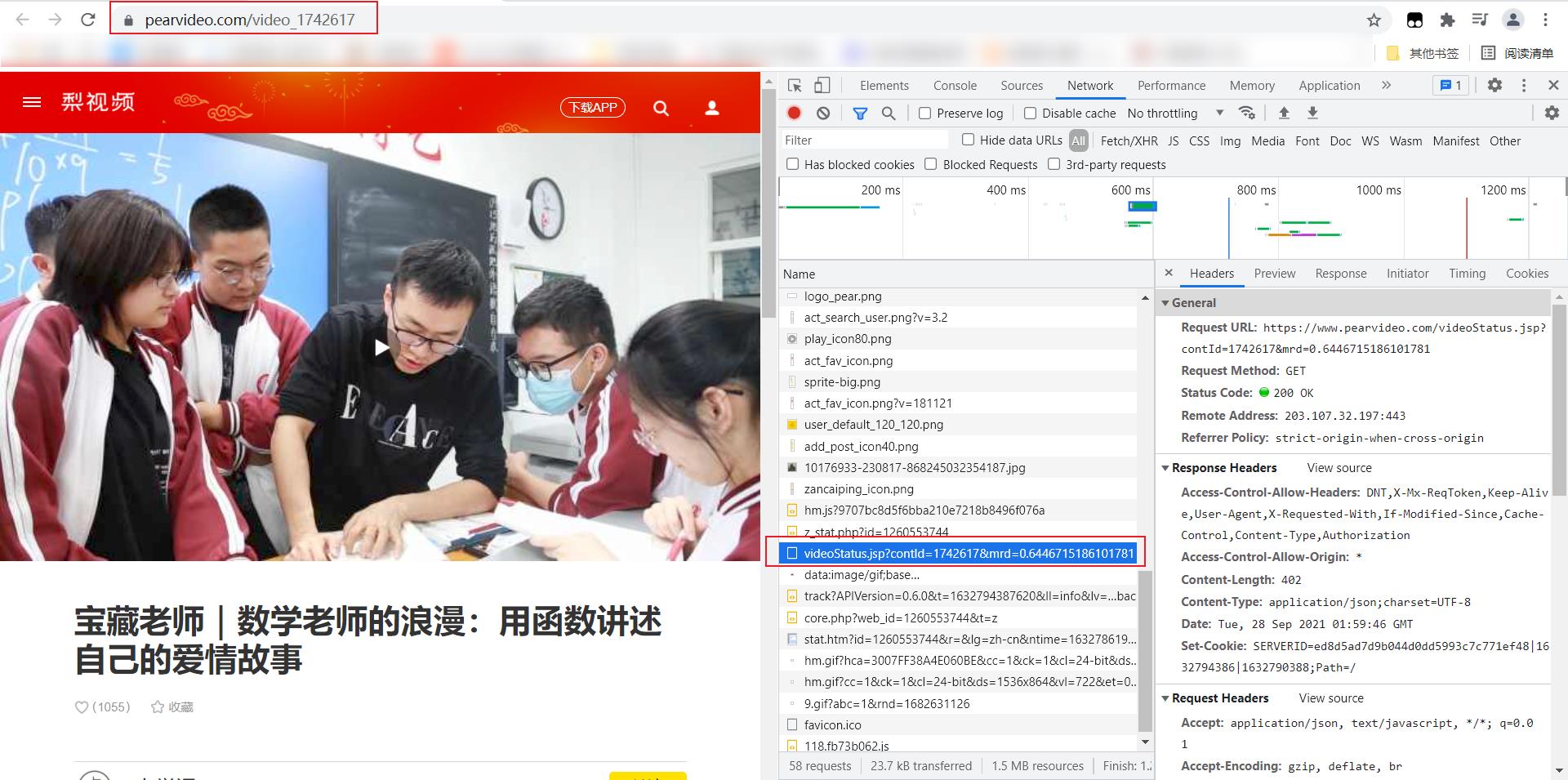
- 宝藏老师|数学老师的浪漫:用函数讲述自己的爱情故事:
https://www.pearvideo.com/videoStatus.jsp?contId=1742617&mrd=0.6446715186101781- 小伙肿瘤医院旁开共享厨房,宣传5元吃饱亏本运营:
https://www.pearvideo.com/videoStatus.jsp?contId=1742572&mrd=0.5091336020577668
通过以上两个视频的地址不难发现它们网址都有共同的特点包含contId,我们再回到原始的视频网页数据查看:
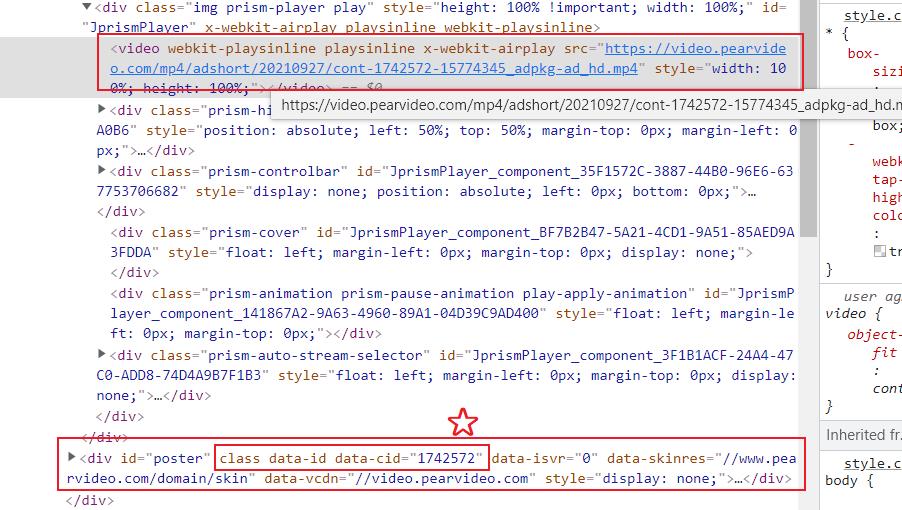
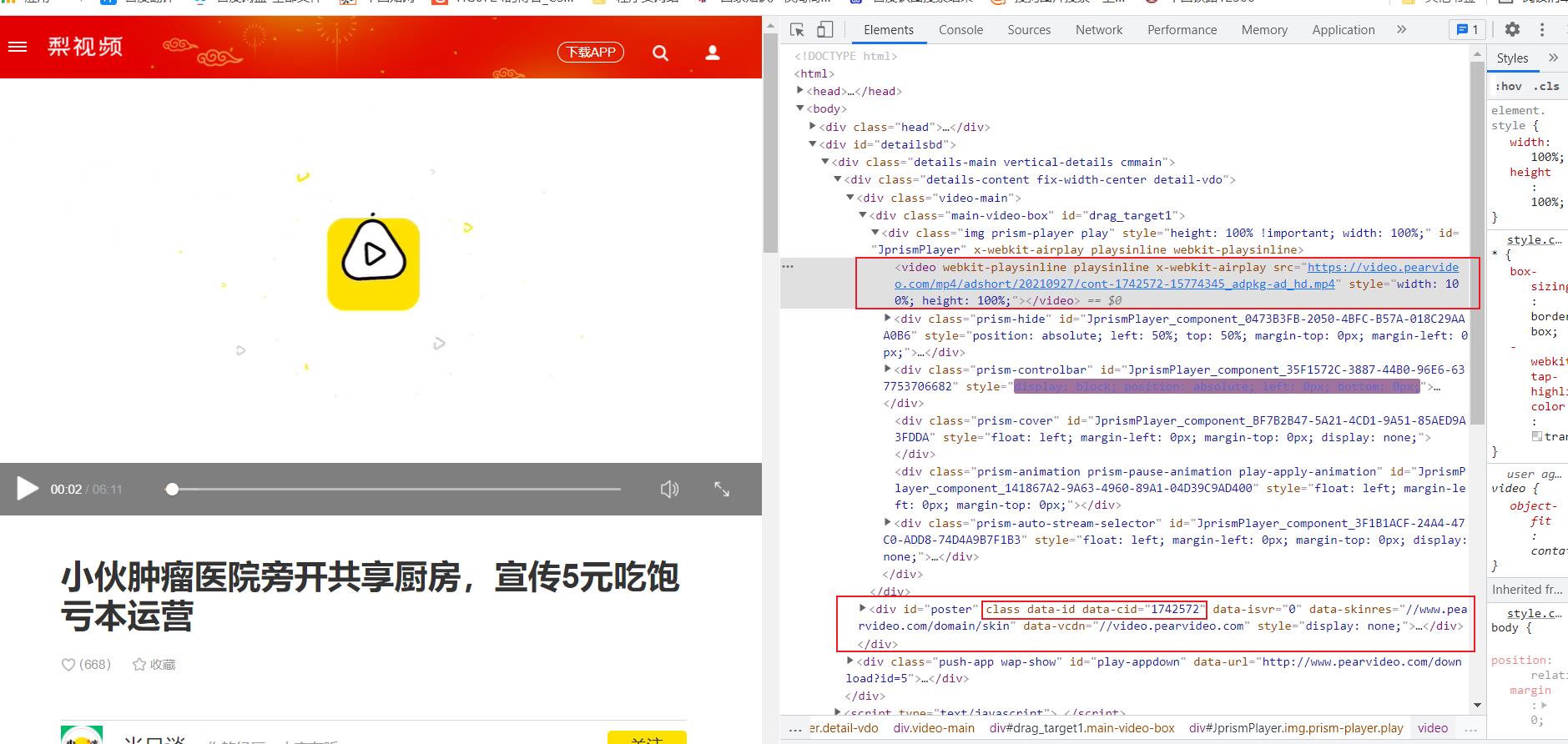
后来由于个人水平问题这个属性值解析出错,因此换了思路:
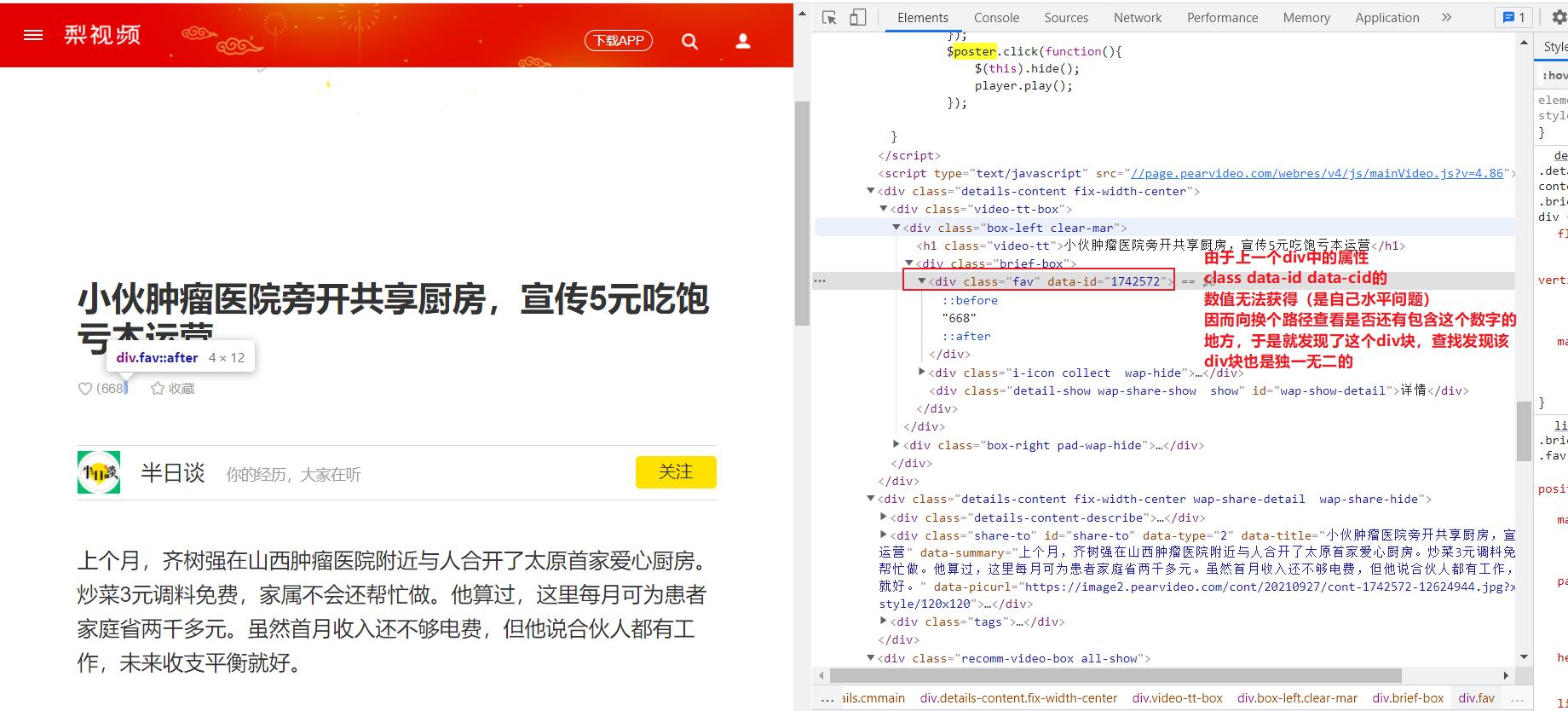
- 解析地址
https://www.pearvideo.com/videoStatus.jsp?contId=1742572&mrd=0.8749545784196235
https://www.pearvideo.com/videoStatus.jsp?contId=1742572&mrd=0.5510063831062151
https://www.pearvideo.com/videoStatus.jsp?contId=1742572&mrd=0.5091336020577668
3.1 代码
- 源代码
import requests
from lxml import etree
import random
import json
from multiprocessing.dummy import Pool
# 需求:安去梨视频的视频数据
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
# 原则:线程池处理的是阻塞且耗时的操作
# 对下述url发起请求解析出视频详情页的url和视频的名称
url = "https://www.pearvideo.com/"
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
# xpath返回的是列表 ['video_1742557']
all_addresses = tree.xpath("//div[@id='vervideoTlist']//a[@class='vervideo-lilink actplay']/@href")
# print(all_addresses)
# ['video_1742557', 'video_1742534', 'video_1742545', 'video_1733739', 'video_1718659']
all_names = tree.xpath('//div[@id="vervideoTlist"]//div[@class="vervideo-name"]/text()')
# print(all_names)
urls = []
for i in range(len(all_addresses)):
video_url = 'https://www.pearvideo.com/' + all_addresses[i]
mp4_name = all_names[i] + '.mp4'
video_page_text = requests.get(url=video_url,headers=headers).text
video_tree = etree.HTML(video_page_text)
# https://www.pearvideo.com/videoStatus.jsp?contId=1742572&mrd=0.8749545784196235
contId = video_tree.xpath('//div[@class="fav"]/@data-id')[0]
# print(contId)
mrd = random.random() # random.random() 0.5330239801324711
new_headers={
'Referer':video_url,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
ajax_url = 'https://www.pearvideo.com/videoStatus.jsp?contId='+str(contId)+'&mrd='+str(mrd)
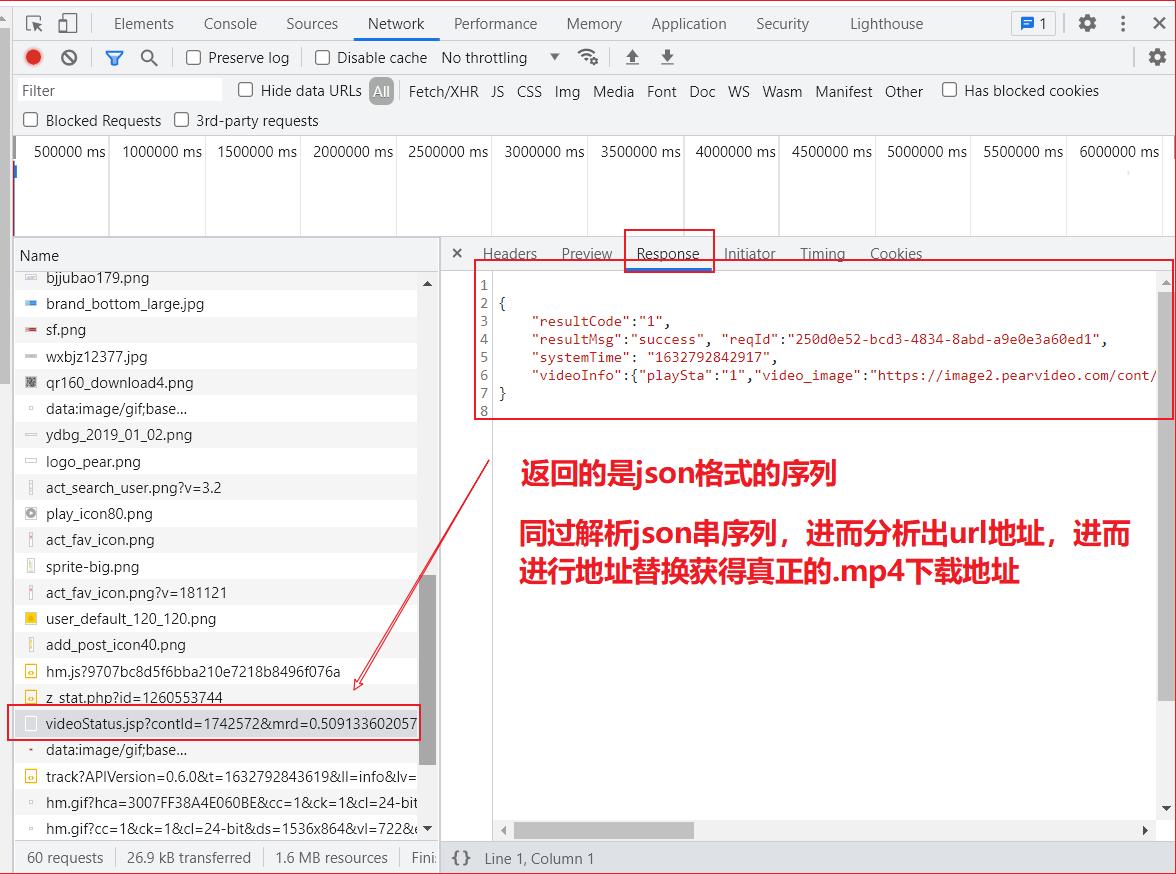
real_video_content = requests.get(url=ajax_url,headers=new_headers).text # 返回的是json字符串
# 获取伪地址
false_video_url = eval(real_video_content)['videoInfo']['videos']['srcUrl']
# 获取真地址
old=false_video_url.split('/')[-1].split('-')[0]
new='cont-'+str(contId)
true_video_url=false_video_url.replace(old,new)
dic = {
'name':mp4_name,
'video_url':true_video_url
}
urls.append(dic)
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载.....')
data_url=dic['video_url']
data=requests.get(url=data_url,headers=headers).content
with open(dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()# 关闭pool,使其不在接受新的(主进程)任务
pool.join() # 主进程阻塞后,让子进程继续运行完成,子进程运行完后,再把主进程全部关掉
# print(video_url,mp4_name):
# https://www.pearvideo.com/video_1742572 小伙肿瘤医院旁开共享厨房,宣传5元吃饱亏本运营.mp4
# https://www.pearvideo.com/video_1742617 宝藏老师|数学老师的浪漫:用函数讲述自己的爱情故事.mp4
# https://www.pearvideo.com/video_1742606 每一帧都如梦境!航拍神农架绝美秋季,云雾浩渺红架绝美秋季,云雾浩渺红叶争艳.mp4
# https://www.pearvideo.com/video_1740575 89岁浙大教师拾破烂9年, 金全部捐助贫困生.mp4 资金全部捐助贫困生.mp4 丘菜刀吗?18道工序,手
# https://www.pearvideo.com/video_1727677 听说过章丘铁锅,听说过章丘菜刀吗?18道工序,手工锻打.mp4
- 运行结果


3.2 代码讲解
- 随机数
返回随机生成的一个实数,它在
[0,1)范围内
>>> import random
>>> random.random()
0.5330239801324711
- Referer的含义
Referer是HTTP请求Header的一部分,当浏览器向Web服务器发送请求的时候,请求头信息一般需要包含Referer。
该Referer会告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。
Referer作用是什么?
- 防盗链
比如办事通服务器只允许网站访问自己的静态资源,那服务器每次都需要判断Referer的值是否是>zwfw.yn.gov.cn,如果是就继续访问,不是就拦截。- 防止恶意请求
比如静态请求是.html结尾的,动态请求是.shtml,那么所有的*.shtml请求,必须 Referer为我自己的>网站才可以访问,这就是Referer的作用。
参考链接
- 获取真正的地址
切片目的:获取地址中需要替换的内容
报错404:https://video.pearvideo.com/mp4/adshort/20210927/1632790695959-15774345_adpkg-ad_hd.mp4
正确的路径:https://video.pearvideo.com/mp4/adshort/20210927/cont-1742572-15774345_adpkg-ad_hd.mp4
# 获取真地址
old=false_video_url.split('/')[-1].split('-')[0]
new='cont-'+str(contId)
true_video_url=false_video_url.replace(old,new)
>>> url = "https://video.pearvideo.com/mp4/adshort/20210927/1632790695959-15774345_adpkg-ad_hd.mp4"
>>> url.split('/')
['https:', '', 'video.pearvideo.com', 'mp4', 'adshort', '20210927', '1632790695959-15774345_adpkg-ad_hd.mp4']
>>> str = url.split('/')[-1]
>>> str
'1632790695959-15774345_adpkg-ad_hd.mp4'
>>> str.split('-')
['1632790695959', '15774345_adpkg', 'ad_hd.mp4']
>>> str.split('-')[0]
'1632790695959'
>>>
- 处理json字符串
print('-----eval-----')
print(eval(real_video_content))
print('-----json.loads()-----')
print(json.loads(real_video_content))
-----eval-----
{'resultCode': '1', 'resultMsg': 'success', 'reqId': 'c44f6eb1-971a-410a-9959-a92d2afeb05f', 'systemTime': '1632799446578', 'videoInfo': {'playSta': '1', 'video_image': 'https://image2.pearvideo.com/cont/20210927/cont-1742572-12624944.jpg', 'videos': {'hdUrl': '', 'hdflvUrl': '', 'sdUrl': '', 'sdflvUrl': '', 'srcUrl': 'https://video.pearvideo.com/mp4/adshort/20210927/1632799446578-15774345_adpkg-ad_hd.mp4'}}}
-----json.loads()-----
{'resultCode': '1', 'resultMsg': 'success', 'reqId': 'c44f6eb1-971a-410a-9959-a92d2afeb05f', 'systemTime': '1632799446578', 'videoInfo': {'playSta': '1', 'video_image': 'https://image2.pearvideo.com/cont/20210927/cont-1742572-12624944.jpg', 'videos': {'hdUrl': '', 'hdflvUrl': '', 'sdUrl': '', 'sdflvUrl': '', 'srcUrl': 'https://video.pearvideo.com/mp4/adshort/20210927/1632799446578-15774345_adpkg-ad_hd.mp4'}}}
-----eval-----
{'resultCode': '1', 'resultMsg': 'success', 'reqId': 'e488637c-0200-41f0-a259-9493913f1d11', 'systemTime': '1632799446898', 'videoInfo': {'playSta': '1', 'video_image': 'https://image1.pearvideo.com/cont/20210927/cont-1742617-12625072.jpg', 'videos': {'hdUrl': '', 'hdflvUrl': '', 'sdUrl': '', 'sdflvUrl': '', 'srcUrl': 'https://video.pearvideo.com/mp4/adshort/20210927/1632799446898-15774709_adpkg-ad_hd.mp4'}}}
-----json.loads()-----
{'resultCode': '1', 'resultMsg': 'success', 'reqId': 'e488637c-0200-41f0-a259-9493913f1d11', 'systemTime': '1632799446898', 'videoInfo': {'playSta': '1', 'video_image': 'https://image1.pearvideo.com/cont/20210927/cont-1742617-12625072.jpg', 'videos': {'hdUrl': '', 'hdflvUrl': '', 'sdUrl': '', 'sdflvUrl': '', 'srcUrl': 'https://video.pearvideo.com/mp4/adshort/20210927/1632799446898-15774709_adpkg-ad_hd.mp4'}}}
-----eval-----
{'resultCode': '1', 'resultMsg': 'success', 'reqId': 'b2b607e8-9685-4f3f-8c16-e10aedad97d0', 'systemTime': '1632799447261', 'videoInfo': {'playSta': '1', 'video_image': 'https://image2.pearvideo.com/cont/20210927/cont-1742606-12625013.png', 'videos': {'hdUrl': '', 'hdflvUrl': '', 'sdUrl': '', 'sdflvUrl': '', 'srcUrl': 'https://video.pearvideo.com/mp4/adshort/20210927/1632799447261-15774653_adpkg-ad_hd.mp4'}}}
-----json.loads()-----
{'resultCode': '1', 'resultMsg': 'success', 'reqId': 'b2b607e8-9685-4f3f-8c16-e10aedad97d0', 'systemTime': '1632799447261', 'videoInfo': {'playSta': '1', 'video_image': 'https://image2.pearvideo.com/cont/20210927/cont-1742606-12625013.png', 'videos': {'hdUrl': '', 'hdflvUrl': '', 'sdUrl': '', 'sdflvUrl': '', 'srcUrl': 'https://video.pearvideo.com/mp4/adshort/20210927/1632799447261-15774653_adpkg-ad_hd.mp4'}}}
-----eval-----
{'resultCode': '1', 'resultMsg': 'success', 'reqId': '16929bb3-257e-4c01-94df-4343a42b99d9', 'systemTime': '1632799447584', 'videoInfo': {'playSta': '1', 'video_image': 'https://image1.pearvideo.com/cont/20210227/cont-1721628-12558949.png', 'videos': {'hdUrl': '', 'hdflvUrl': '', 'sdUrl': '', 'sdflvUrl': '', 'srcUrl': 'https://video.pearvideo.com/mp4/adshort/20210227/1632799447584-15618162_adpkg-ad_hd.mp4'}}}
-----json.loads()-----
{'resultCode': '1', 'resultMsg': 'success', 'reqId': '16929bb3-257e-4c01-94df-4343a42b99d9', 'systemTime': '1632799447584', 'videoInfo': {'playSta': '1', 'video_image': 'https://image1.pearvideo.com/cont/20210227/cont-1721628-12558949.png', 'videos': {'hdUrl': '', 'hdflvUrl': '', 'sdUrl': '', 'sdflvUrl': '', 'srcUrl': 'https://video.pearvideo.com/mp4/adshort/20210227/1632799447584-15618162_adpkg-ad_hd.mp4'}}}
-----eval-----
{'resultCode': '1', 'resultMsg': 'success', 'reqId': '34db5053-02f9-40c1-98c8-4d83a0e7d50f', 'systemTime': '1632799447961', 'videoInfo': {'playSta': '1', 'video_image': 'https://image.pearvideo.com/cont/20210521/cont-1729993-12587145.png', 'videos': {'hdUrl': '', 'hdflvUrl': '', 'sdUrl': '', 'sdflvUrl': '', 'srcUrl': 'https://video.pearvideo.com/mp4/adshort/20210521/1632799447961-15678629_adpkg-ad_hd.mp4'}}}
-----json.loads()-----
{'resultCode': '1', 'resultMsg': 'success', 'reqId': '34db5053-02f9-40c1-98c8-4d83a0e7d50f', 'systemTime': '1632799447961', 'videoInfo': {'playSta': '1', 'video_image': 'https://image.pearvideo.com/cont/20210521/cont-1729993-12587145.png', 'videos': {'hdUrl': '', 'hdflvUrl': '', 'sdUrl': '', 'sdflvUrl': '', 'srcUrl': 'https://video.pearvideo.com/mp4/adshort/20210521/1632799447961-15678629_adpkg-ad_hd.mp4'}}}
通过以上测试不难发现json.loads()方式和eval方式都可以将json处理为相同的结果,但是既然是不同的方法,终究会有区别
四、协程概念
4.1 单线程+异步协程(推荐)
event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事件循环上,当满足某些条件的时候,函数就会被循环执行
coroutine:协程对象,我们可以将协程对象注册到事件循环中,它会被事件循环调用。我们可以使用async关键字来定义一个方法,这个方法在调用时不会立即被执行,而是返回一个协程对象。
task:任务,它是对协程对象的进一步封装,包含了任务的各个状态。
future:代表将来执行或还没有执行的任务,实际上和task没有本质区别。
async:定义一个协程
await:用来挂起阻塞方法的执行。
4.2
以上是关于Python爬虫--高性能的异步爬虫的主要内容,如果未能解决你的问题,请参考以下文章