Python实战—抓取58租房信息并存入Mysql数据库
Posted 白玉梁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python实战—抓取58租房信息并存入Mysql数据库相关的知识,希望对你有一定的参考价值。
Python操作数据库,相对于其它语言,要简单不少!
mysql的安装以及建库建表操作就不说了,我这里本地创建了一个数据库py,以及表tb_py_test:
create table tb_py_test
(
id int auto_increment
primary key,
url text null,
content varchar(255) null,
price double null
);
接下来,安装py的mysql连接工具,pymysql:pip install pymysql;
安装成功后,书写连接程序:
pymysql.connect(host="localhost", user="root", password="root", database="py")
它返回的是数据库对象,然后通过数据库对象获取到游标cursor,再通过cursor执行sql语句,并获取结果:
import pymysql
db = pymysql.connect(host="localhost", user="root", password="root", database="py")
cursor = db.cursor()
try:
sql = "select * from tb_py_test"
cursor.execute(sql)
results = cursor.fetchall()
for result in results:
print(result[0], result[1], result[2])
except Exception as e:
print('fail:' + str(e))
db.rollback()
db.close()
我们先手动向数据库中插入一条数据:

然后执行py:

证明数据库连接及操作没有问题!
那么接下来,本篇博客所要实现的功能,就是爬取58同城租房信息,价格<2000的前300条信息!
打开58首页,https://zz.58.com/分析:

我们需要获取到“租房按钮”并自动点击(当然,你也可以跳过这一步,直接获取租房连接):
driver = webdriver.Firefox(executable_path=r'C:\\geckodriver.exe')
driver.get("https://zz.58.com")
zf = driver.find_element_by_xpath("//a[@tongji_tag='pc_home_dh_zf']")
zf.click()
注意find_element_by_xpath用法,"//a[@tongji_tag=‘pc_home_dh_zf’]"意思是查找出a标签中,属性名为tongji_tag,属性值为’pc_home_dh_zf’的element,自动点击后进入租房信息页:
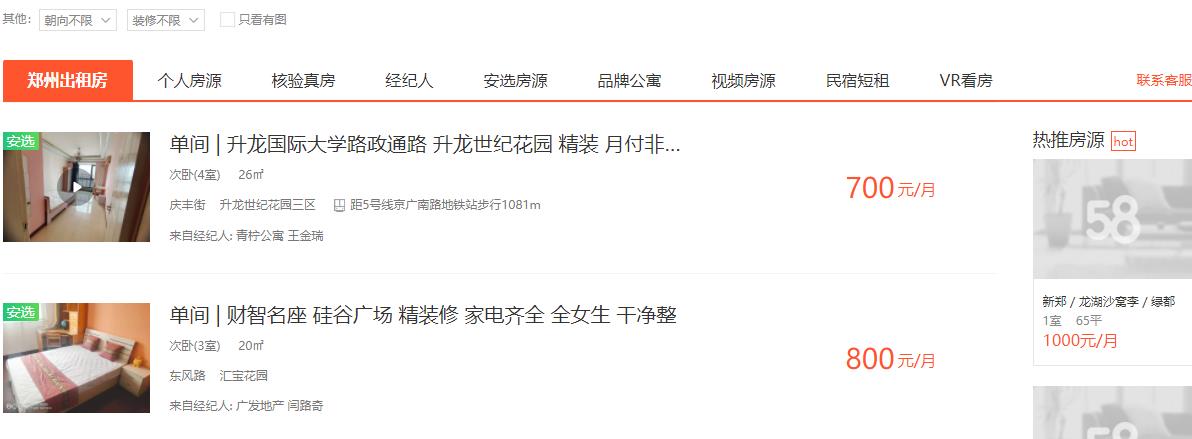
继续分析,按需求,我们需要获取三个字段,租房信息的标题,链接,价钱:
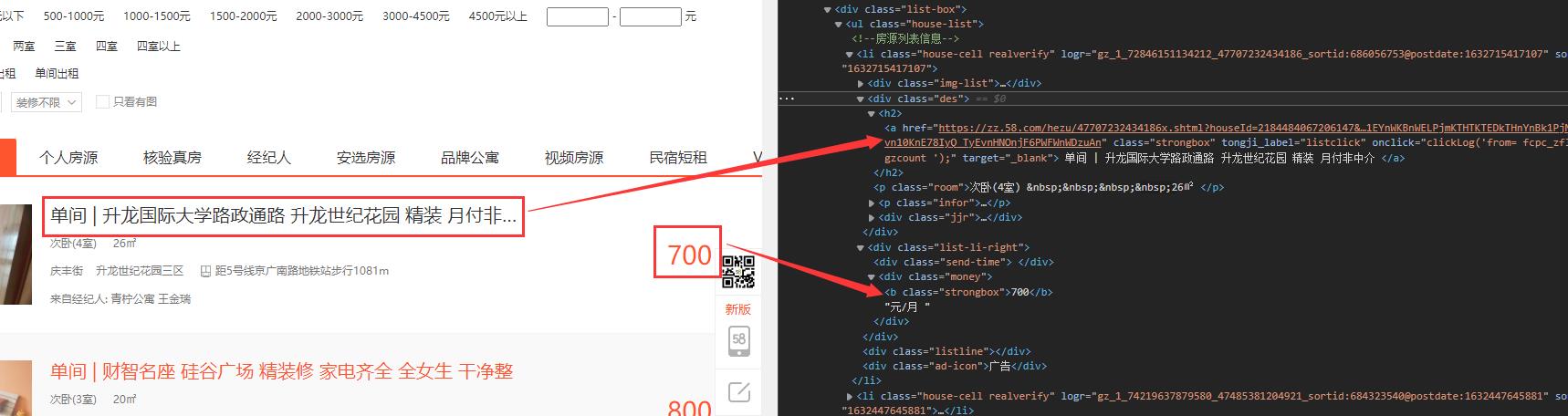
这里,我们需要注意的是,租房信息是一个列表(ul>li),我们获取到的是一个集合,所以i我们要首先获取到ul,然后再获取的li表,最后循环遍历li,并从每个item中提取信息:
driver = webdriver.Firefox(executable_path=r'C:\\geckodriver.exe')
driver.get("https://zz.58.com")
zf = driver.find_element_by_xpath("//a[@tongji_tag='pc_home_dh_zf']")
zf.click()
time.sleep(2)
driver.switch_to.window(driver.window_handles[len(driver.window_handles) - 1])
ul = driver.find_element_by_css_selector('ul.house-list')
lis = ul.find_elements_by_tag_name('li')
for i in range(len(lis) - 1):
price = lis[i].find_element_by_class_name("money").find_element_by_tag_name('b').text # 价格
if int(price) < 2000:
des = lis[i].find_element_by_class_name("des")
a = des.find_element_by_tag_name('a')
title = a.text # 标题
url = a.get_attribute('href') # 链接
print(title, " 租金:" + price, " 链接:" + url)
但实际上,我们再仔细看以下li元素:
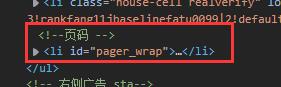
最后一条是页码,并不是我们要的数据,所以需要过滤掉这一条,我们可以在循环时直接-1即可!
driver.switch_to.window(driver.window_handles[len(driver.window_handles) - 1])
这句话的意思是,获取到新窗口的句柄,并切换到新窗口,否则,driver查找的还是旧窗口的元素!
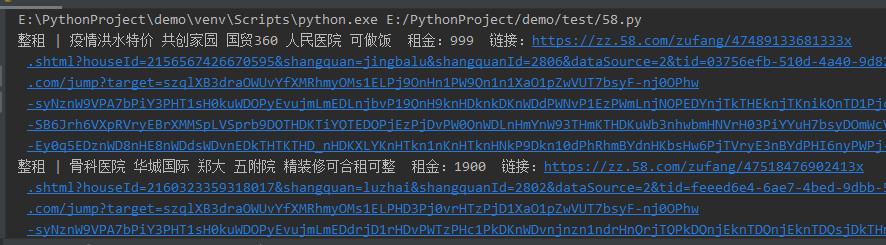
打印结果:
是不是结束了?,当然没有,我们的的需求是获取300条,而上面的代码仅仅是获取了第一页的数据,所以我们需要在第一页数据获取完毕后,自动获取下一页数据,直到获取满足300条!
第一种方法: 分析每一页网页url链接:

你会发现,在切换下一页时,这个参数会跟随页码数变为pn2,pn3…,所以在当前页面数据提取完毕后,你可以直接修改url并转到下一页;
第二种方法: 模拟点击“下一页”按钮:
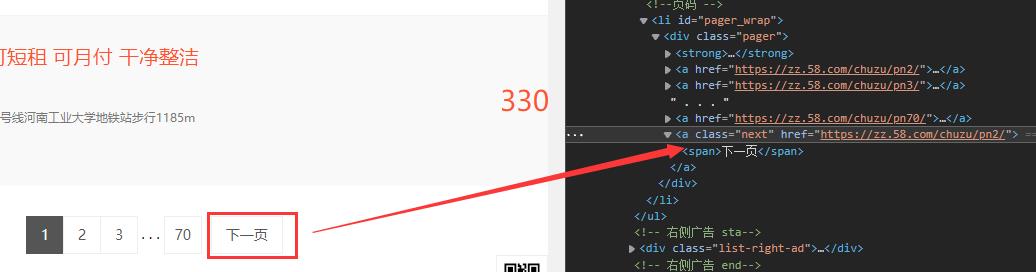
也是本篇博客所使用的方法:
nextBtn = driver.find_element_by_css_selector('div.pager').find_element_by_css_selector("a.next")
nextBtn.click()
当循环遍历每条数据时,再插入到数据库,即可:
sql = "insert into tb_py_test (url, content, price) VALUE ('','','')"
cursor.execute(sql)
db.commit()
完整py代码:
import time
from selenium import webdriver
import pymysql
class House:
def __init__(self):
self.title = ""
self.url = ""
self.price = 0.0
fp = webdriver.FirefoxProfile()
# 限制css加载
fp.set_preference("permissions.default.stylesheet", 2)
# 限制img加载
fp.set_preference("permissions.default.image", 2)
# 限制js加载
fp.set_preference("javascript.enabled", False)
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'C:\\geckodriver.exe')
driver.get("https://zz.58.com")
zf = driver.find_element_by_xpath("//a[@tongji_tag='pc_home_dh_zf']")
zf.click()
time.sleep(2)
driver.switch_to.window(driver.window_handles[len(driver.window_handles) - 1])
houses = []
def start():
while True:
if len(houses) >= 300:
return
getHouses()
def getHouses():
try:
ul = driver.find_element_by_css_selector('ul.house-list')
lis = ul.find_elements_by_tag_name('li')
for i in range(len(lis) - 1):
house = House()
try:
price = lis[i].find_element_by_class_name("money").find_element_by_tag_name('b').text # 价格
if int(price) < 2000:
des = lis[i].find_element_by_class_name("des")
a = des.find_element_by_tag_name('a')
title = a.text # 标题
url = a.get_attribute('href') # 链接
# print(title, " 租金:" + price, " 链接:" + url)
house.title = title
house.url = url
house.price = price
addHouse(house)
if len(houses) >= 300:
return
except Exception as e:
print(str(e))
nextBtn = driver.find_element_by_css_selector('div.pager').find_element_by_css_selector("a.next")
nextBtn.click()
time.sleep(3)
except Exception as e:
print(str(e))
def addHouse(house):
houses.append(house)
print(len(houses), house.price)
try:
# 先查询数据库中是否已经插入该条,是则过滤
sql = "select url from tb_py_test where url='" + house.url + "'"
cursor.execute(sql)
url = cursor.fetchone()
if url:
return
# 插入数据
sql = "insert into tb_py_test (url, content, price) VALUE ('" + house.url + "','" + house.title + "',+'" + house.price + "')"
cursor.execute(sql)
db.commit()
print('insert success')
except Exception as e:
print('insert fail:' + str(e))
db.rollback()
db = pymysql.connect(host="localhost", user="root", password="root", database="py")
cursor = db.cursor()
start()
db.close()
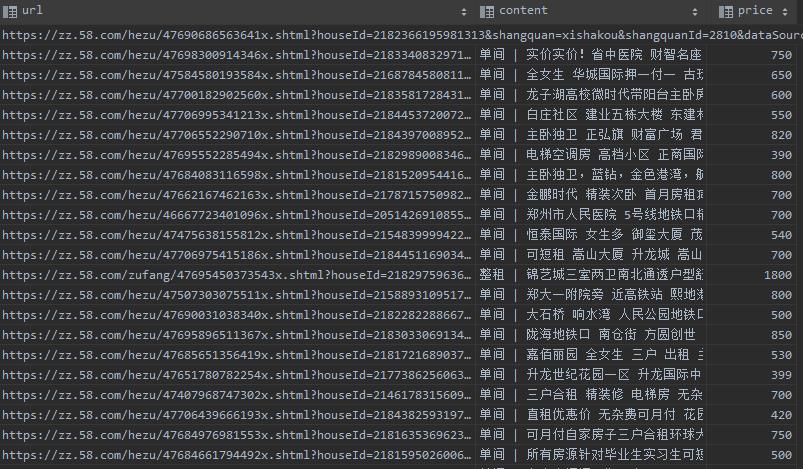
以上是关于Python实战—抓取58租房信息并存入Mysql数据库的主要内容,如果未能解决你的问题,请参考以下文章