python爬虫美剧下载
Posted 诡途
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫美剧下载相关的知识,希望对你有一定的参考价值。
阅前声明:本文旨在交流技术,尊重版权尊重原创,科学上网,不得用于违法途径,安全使用技术,因技术使用不当导致不良后果,本人概不负责
问题起源
最近想学学英语,看了几个课程,里面建议看看美剧,里面推荐了几部美剧应该还不错,还没看完,有兴趣的可以瞅瞅!!
影单目录如下:
- 《安娜》
- 《时尚女魔头》
- 《行动目标希特勒》
朋友推荐了【人人影视】的资源,不知道是我自己的网络问题还是因为网站服务器在外部或者其他原因,一秒卡三下,在线播放就贼痛苦,所以就想下载下来看,顺便为打发国庆高铁的无聊囤点儿货,为了看点儿美剧也是拼了。
网络分析
这里以《安娜》为例,开发者模式查询网络传输,先找到m3u8的请求,这里是双层嵌套,但是好在没有加密,
加密的暂时没啥办法,网上有很多案例,试了好多没成功
解释一下:m3u8是一种流媒体格式,以文件列表的形式存在,里面记录了版本号、加密方式、文件列表等信息
如下图所示,先找到第一层索引文件
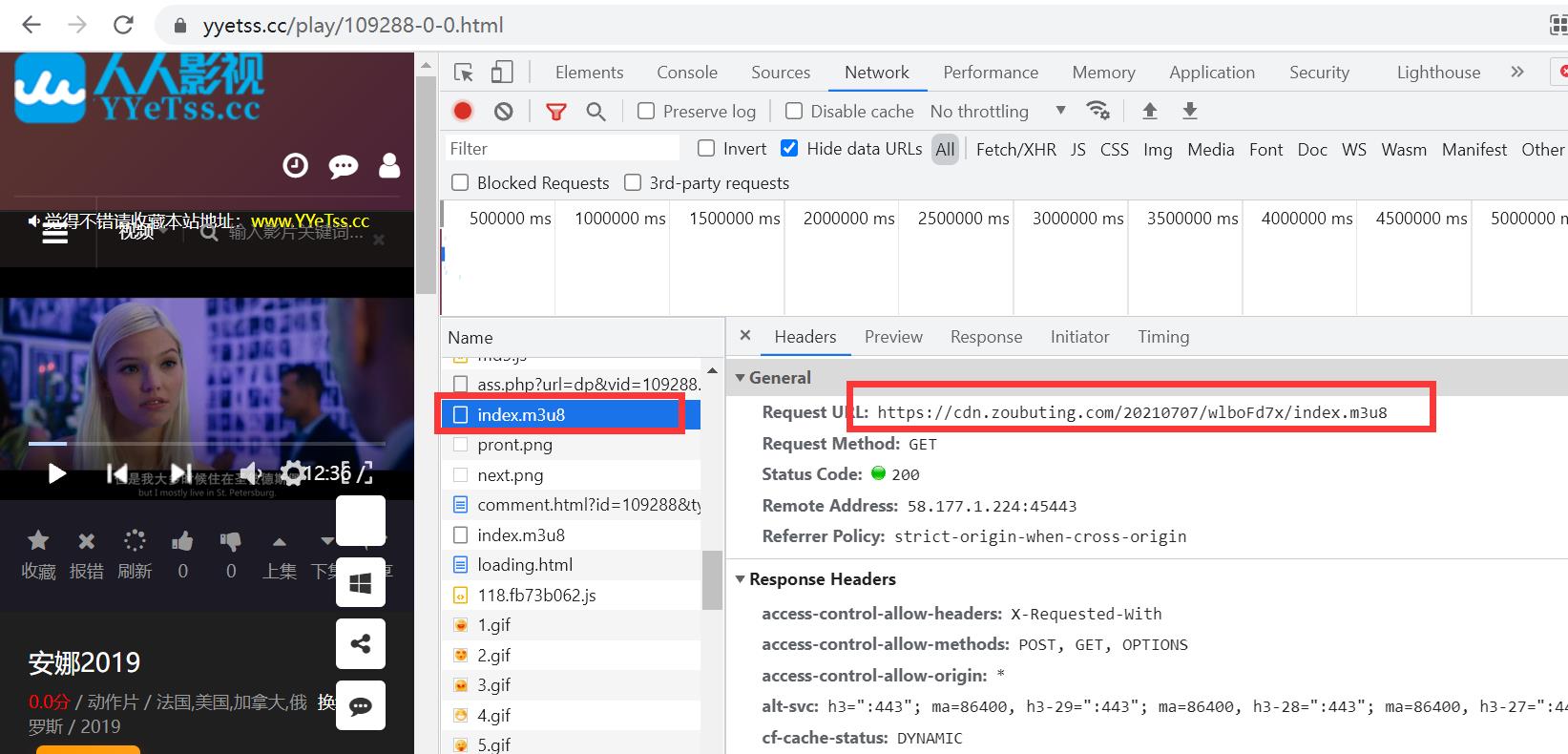 直接复制请求url到浏览器,下载m3u8文件,使用记事本/notepad++打开,文件内容如下,这里放的是真实m3u8文件路径
直接复制请求url到浏览器,下载m3u8文件,使用记事本/notepad++打开,文件内容如下,这里放的是真实m3u8文件路径

播放一段,找到一段ts,解析出当前请求域路径
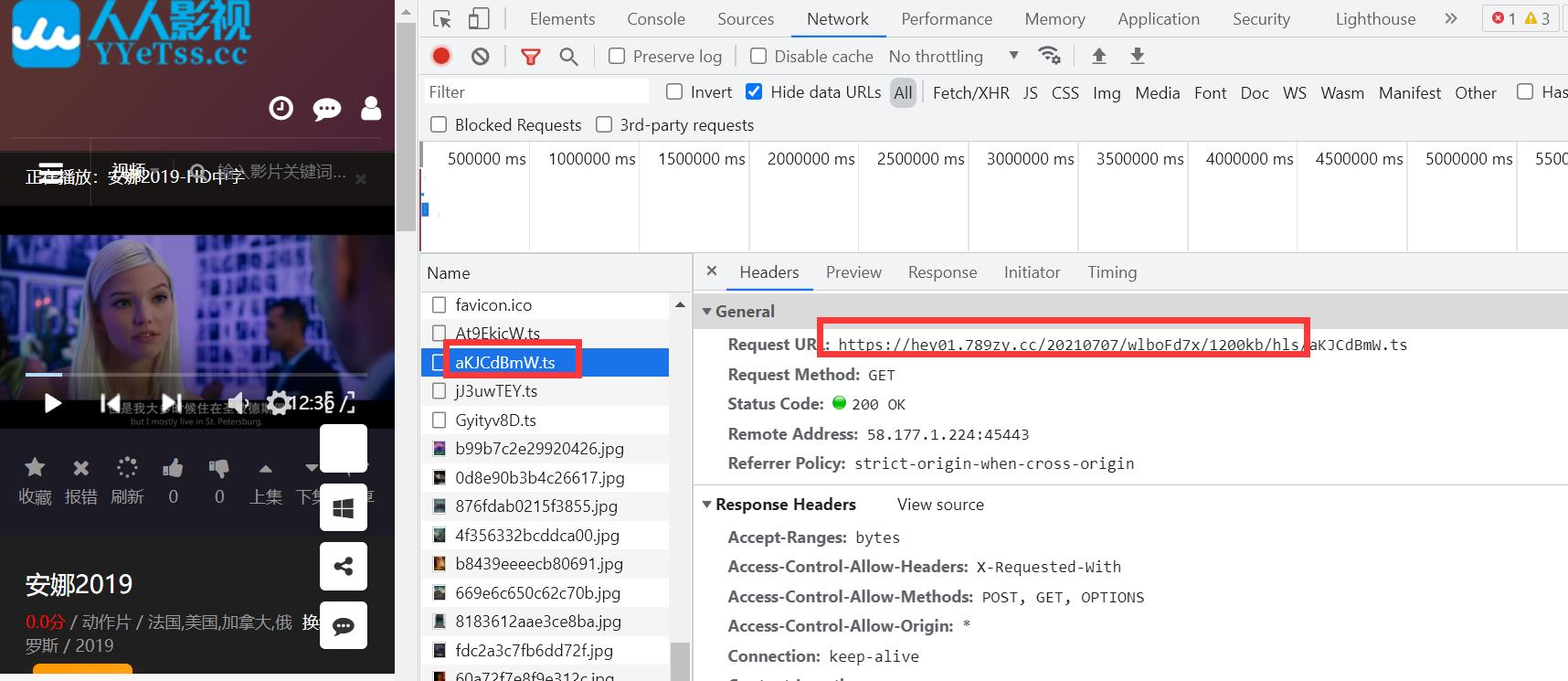
把前面的域路径和前面第一层的m3u8路径拼接
得到真实m3u8请求
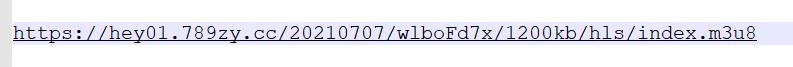
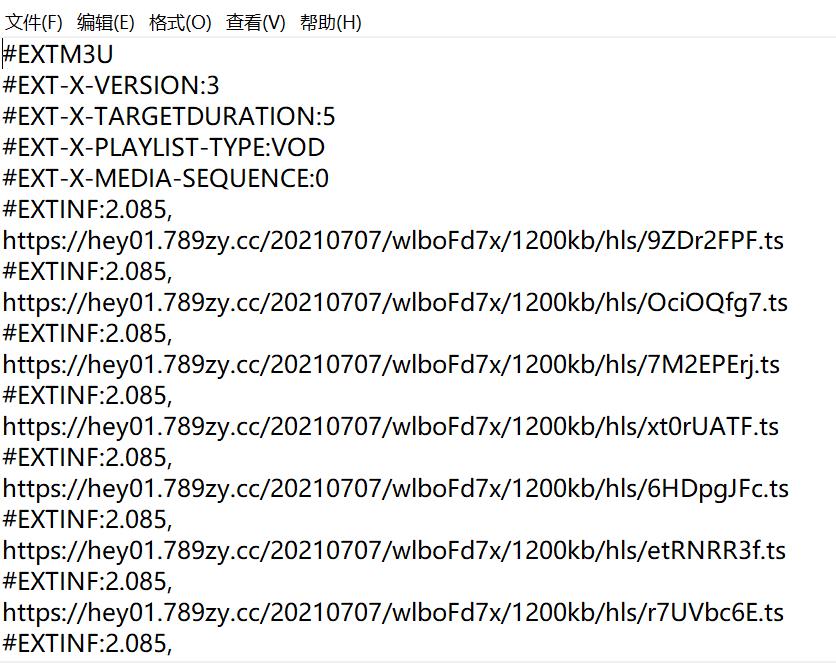
重复前面步骤:把完整连接复制到浏览器–>下载
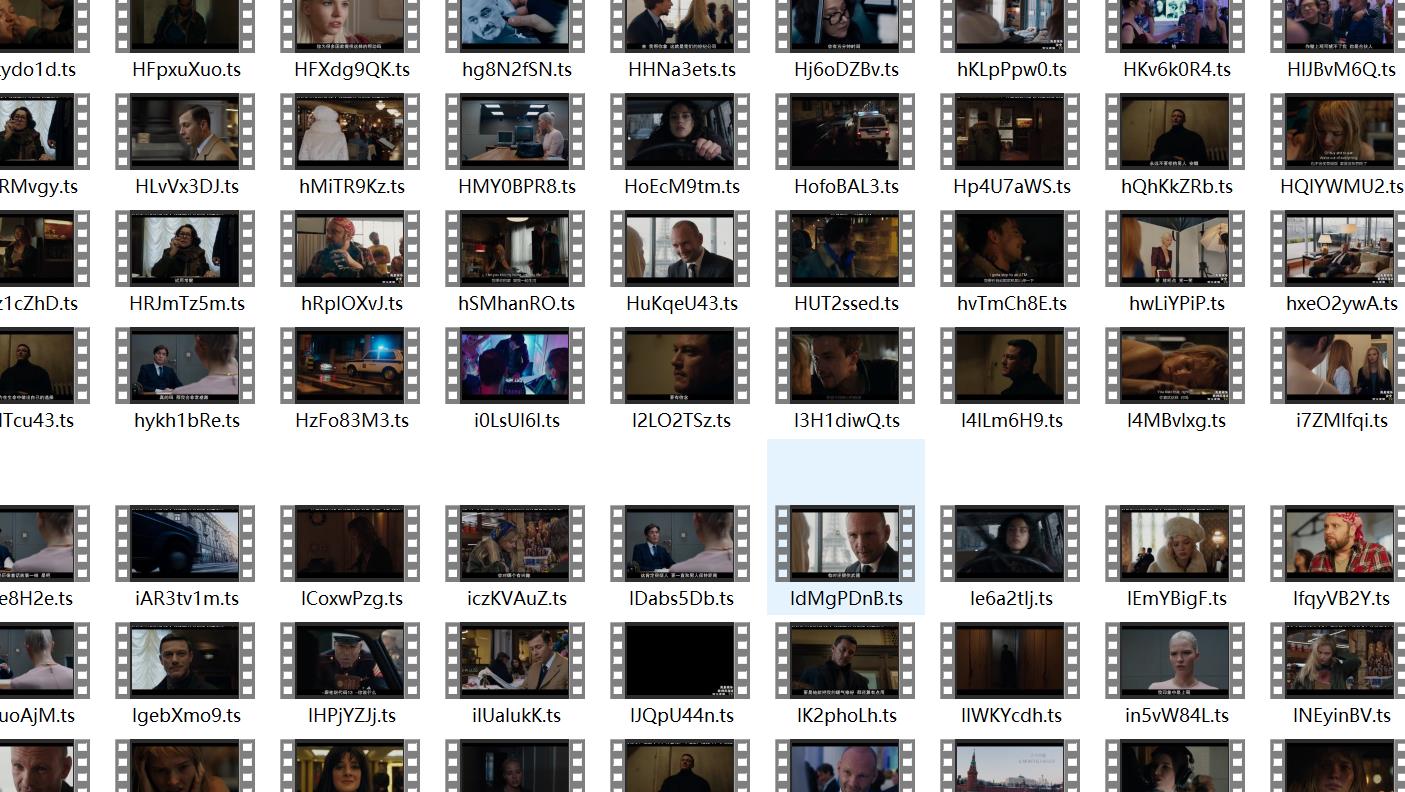
这里就得到了全部的ts路径和顺序,解析出来合并就可以了
代码示例
import requests,os
def download_ts_file(url,num,total):
"""单个ts文件下载"""
# 这里可以用自己的,也可以使用 fake_useragent 生成随机请求头
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
response=requests.get(url,headers=headers)
data = response.content
file_name = url.split("/")[-1]
ts_path = os.path.join(tmp_path,file_name)
with open(ts_path,'wb') as f:
f.write(data)
f.close()
print(f"第【{num+1}/{total}】个ts片段{file_name}下载完成")
return None
# ts临时存储路径
tmp_path = os.path.join(os.getcwd(),"tmp_path")
# 读取并解析ts链接
f = open("index.m3u8","r",encoding="utf-8")
m3u8 = f.readlines()
f.close()
url_list = [url.split("\\n")[0] for url in m3u8 if "https" in url]
# 循环下载各个ts片段--这里可以使用多线程,这里出于安全考虑没有加速,感兴趣的可以自己试试
[download_ts_file(url,url_list.index(url),len(url_list)) for url in url_list]
----------重要的事情说三遍,注意安全注意安全注意安全--------
----------重要的事情说三遍,注意安全注意安全注意安全--------
----------重要的事情说三遍,注意安全注意安全注意安全--------
—————————————————————————————————————————————————————
-----------分割线,多线程速度贼快,注意安全哦!----------
-----------本来不想用多线程的,奈何单线程实在太慢----------
import requests,os
def download_ts_file(num,url_list):
"""单个ts文件下载"""
url,total = url_list[num],len(url_list)
# 这里可以用自己的,也可以使用 fake_useragent 生成随机请求头
headers={'User-Agent':'xxxxx'}
response=requests.get(url,headers=headers)
data = response.content
file_name = url.split("/")[-1]
ts_path = os.path.join(tmp_path,file_name)
with open(ts_path,'wb') as f:
f.write(data)
f.close()
print(f"第【{num+1}/{total}】个ts片段{file_name}下载完成")
return None
# ts临时存储路径
tmp_path = os.path.join(os.getcwd(),"tmp_path")
# 读取并解析ts链接
f = open("index.m3u8","r",encoding="utf-8")
m3u8 = f.readlines()
f.close()
url_list = [url.split("\\n")[0] for url in m3u8 if "https" in url]
# 循环下载各个ts片段--这里可以使用多线程,这里出于安全考虑没有加速,感兴趣的可以自己试试
from concurrent.futures import ThreadPoolExecutor # 线程池
p = ThreadPoolExecutor(8)
for num in range(len(url_list)):
p.submit(download_ts_file, num,url_list)
———————————————————我又是一条分割线——————————————
——————————————下面是怎么把ts合成成MP4格式——————————
#方法一:直接读取写入,注意按照m3u8文件给出的顺序读取写入
import os
# ts临时存储路径
tmp_path = os.path.join(os.getcwd(),"tmp_path")
# 读取并解析ts链接
f = open("index.m3u8","r",encoding="utf-8")
m3u8 = f.readlines()
f.close()
url_list = [url.split("\\n")[0] for url in m3u8 if "https" in url]
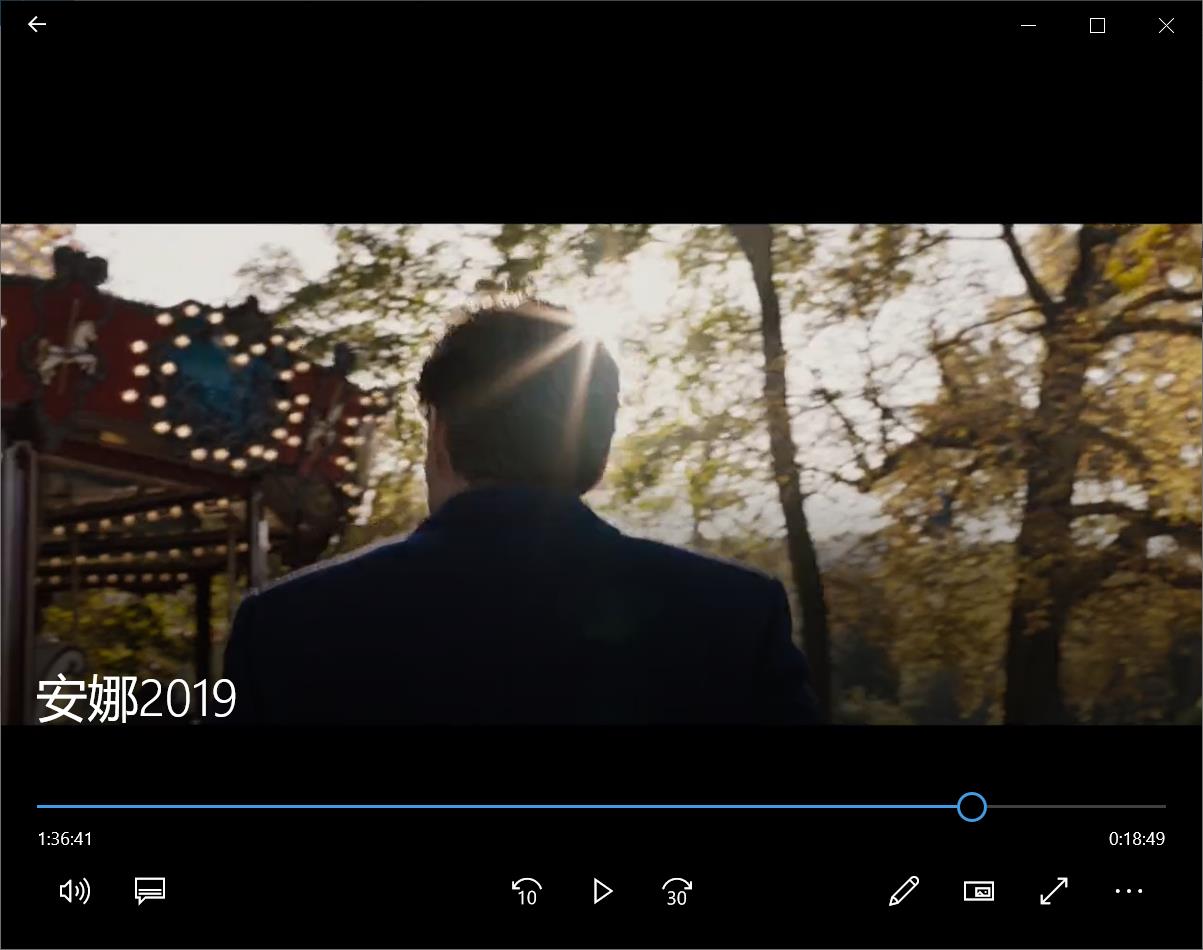
with open('安娜2019.mp4','wb') as f2:
for url in url_list:
file_name = url.split("/")[-1]
ts_path = os.path.join(tmp_path,file_name)
f1 = open(ts_path,"rb")
data = f1.read()
f1.close()
f2.write(data)
f2.close()
合并ts还有一种方法,但是上限只能合并450个,我们这里是大视频不适用,可以了解参考下,当然有方法规避这个bug,这里不细讲了,有兴趣的自己查下资料
结果展示
以上是关于python爬虫美剧下载的主要内容,如果未能解决你的问题,请参考以下文章