[论文阅读] Variational Adversarial Active Learning
Posted xiongxyowo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[论文阅读] Variational Adversarial Active Learning相关的知识,希望对你有一定的参考价值。
论文地址:https://arxiv.org/abs/1904.00370
代码:https://github.com/sinhasam/vaal
发表于:ICCV’19
Abstract
主动学习的目的是通过对最有代表性的查询进行采样,由专家进行标注,从而开发出高效标签的算法。我们描述了一种基于池的半监督主动学习算法,它以对抗的方式隐式地学习了这种采样机制。与传统的主动学习算法不同,我们的方法是与任务无关的,也就是说,它不依赖于我们试图获取标注数据的任务的性能。我们的方法使用变分自编码器(VAE)和训练好的对抗网络来学习潜在空间,以区分未标注和标注的数据。VAE和对抗网络之间的最大最小博弈是这样进行的:VAE试图欺骗对抗网络去预测,所有的数据点都来自已标注池;对抗网络则学习如何区分潜在空间中的不相似性。我们在各种图像分类和语义分割基准数据集上广泛评估了我们的方法,并在CIFAR10/100、Caltech-256、ImageNet、Cityscapes和BDD100K上建立了新的SOTA。我们的结果表明,我们的对抗性方法在大规模环境中学习了一个有效的低维潜在空间,并提供了一个计算效率高的采样方法。
I. Motivation
本文的出发点严格来讲可以理解如下。之前的很多方法,其uncertainty都是基于模型的,也就是说我们得先有个分割/分类等模型去计算一个预测结果,然后从结果的好坏去分析相应的被预测样本的价值。而本文的uncertainty是基于数据本身的,也就是说并非基于预测结果本身去分析,而是直接基于样本自身的特征去处理。
核心思想:利用VAE对已标注的数据和未标注的数据进行编码。因此,对于一个未标注的数据,如果其编码向量与潜在空间中向量的差异足够大,那么我们就认为该样本是有价值的。
而对于样本的选择,是通过一个对抗网络来实现的,该对抗网络被用来区分一个样本是已标注还是未标注。因此实际上上文的VAE还有一个额外的任务,即他的编码要让判别器难以区分已经标注还是没有标注。
本文的最大特点就是没有去利用公式来显式地去定义不确定性。此外,也研究了噪声标注鲁棒性的问题。接下来,将分析VAAL的详细流程。
II. Architecture
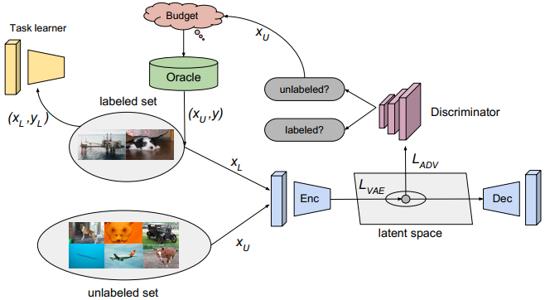
III. Transductive representation learning
本文所用的VAE为Wasserstein Autoencoder,其目标函数可以表示如下: L V A E t r d = E [ log p θ ( x L ∣ z L ) ] − β D K L ( q ϕ ( z L ∣ x L ) ∥ p ( z ) ) + E [ log p θ ( x U ∣ z U ) ] − β D K L ( q ϕ ( z U ∣ x U ) ∥ p ( z ) ) \\begin{aligned} \\mathcal{L}_{\\mathrm{VAE}}^{t r d}=& \\mathbb{E}\\left[\\log p_{\\theta}\\left(x_{L} \\mid z_{L}\\right)\\right]-\\beta \\mathrm{D}_{\\mathrm{KL}}\\left(q_{\\phi}\\left(z_{L} \\mid x_{L}\\right) \\| p(z)\\right) \\\\ &+\\mathbb{E}\\left[\\log p_{\\theta}\\left(x_{U} \\mid z_{U}\\right)\\right]-\\beta \\mathrm{D}_{\\mathrm{KL}}\\left(q_{\\phi}\\left(z_{U} \\mid x_{U}\\right) \\| p(z)\\right) \\end{aligned} LVAEtrd=E[logpθ(xL∣zL)]−βDKL(qϕ(zL∣xL)∥p(z))+E[logpθ(xU∣zU)]−βDKL(qϕ(zU∣xU)∥p(z)) 其中 q ϕ q_{\\phi} qϕ和 p θ p_{\\theta} pθ分别表示encoder与decoder, β \\beta β为优化问题的拉格朗日参数。
抛开公式不谈,由于本文VAE是同时学了已标注池与未标注池的信息,因此可以补充到已标注池中所缺失的表征。
IV. Adversarial representation learning
由于VAE学到的特征既包含已标注图像的也包含未标注图像的,因此,我们就得想办法去找出里面那些属于未标注图像的特征来。
对于VAE而言,其在同一潜在空间里有两个概率分布:
q
ϕ
(
z
L
∣
x
L
)
q_{\\phi}\\left(z_{L} \\mid x_{L}\\right)
qϕ(zL∣xL)
q
ϕ
(
z
U
∣
x
U
)
q_{\\phi}\\left(z_{U} \\mid x_{U}\\right)
qϕ(zU∣xU)
相应的,GAN的目标函数为: L D = − E [ log ( D ( q ϕ ( z L ∣ x L ) ) ) ] − E [ log ( 1 − D ( q ϕ ( z U ∣ x U ) ) ) ] \\mathcal{L}_{D}=-\\mathbb{E}\\left[\\log \\left(D\\left(q_{\\phi}\\left(z_{L} \\mid x_{L}\\right)\\right)\\right)\\right]-\\mathbb{E}\\left[\\log \\left(1-D\\left(q_{\\phi}\\left(z_{U} \\mid x_{U}\\right)\\right)\\right)\\right] LD=−E[log(D(qϕ(zL∣xL)))]−E[log(1−D(qϕ(zU∣xU)))]
最终整个网络的训练流程如下:

输入 已标注池
(
X
L
,
Y
L
)
(X_{L},Y_{L})
(XL,YL),未标注池
(
X
U
)
(X_{U})
(XU),初始化任务模型(分类模型,分割模型等)
θ
T
\\theta_{T}
θT,变分自编码器
θ
V
A
E
\\theta_{VAE}
θVAE,判别器
θ
D
\\theta_{D}
θD
超参数 迭代次数epochs,损失函数参数
λ
\\lambda
λ以及学习率
α
\\alpha
α
对于每个epoch:
step 1 从已标注池中采样
(
x
L
,
y
L
)
(x_{L},y_{L})
(xL,yL),从未标注池中采样
(
x
U
)
(x_{U})
(xU)
step 2 计算VAE的训练损失
L
V
A
E
t
r
d
\\mathcal{L}_{\\mathrm{VAE}}^{t r d}
LVAEtrd
step 3 计算VAE的对抗损失
L
V
A
E
a
d
v
\\mathcal{L}_{\\mathrm{VAE}}^{a d v}
LVAEadv
step 4 加权得到VAE的最终损失
L
V
A
E
\\mathcal{L}_{\\mathrm{VAE}}
LVAE,并相应地更新VAE的模型参数
step 5 计算判别器的损失
L
D
\\mathcal{L}_{\\mathrm{D}}
LD
step 6 更新判别器的模型参数
step 7 训练任务模型T,这一部分详细过程省略
V. Sampling strategies
本文的采样策略如下:

以上是关于[论文阅读] Variational Adversarial Active Learning的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读“Dual-View Variational Autoencoders for Semi-Supervised Text Matching”
NIPS 2016图神经网络论文解读VGAE:图变分自编码器 Variational Graph Auto-Encoders(基于图的VAE)
VAE(Variational Autoencoder)的原理
Semi-supervised Segmentation of Optic Cup in Retinal Fundus Images Using Variational Autoencoder 论文笔
文献阅读·62-Variational Autoencoder based Anomaly Detection using Reconstruction Probability