带你全面的了解二叉树
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你全面的了解二叉树相关的知识,希望对你有一定的参考价值。
摘要:日常生活中,很多事物都可以用树来描述,例如书的目录、工作单位的组织架构等等。树是计算机中非常重要的一种数据结构,树存储方式可以提高数据的存储、读取效率。
本文分享自华为云社区《【云驻共创】想了解二叉树,看这篇文章就够了》,作者: liuzhen007 。
前言
日常生活中,很多事物都可以用树来描述,例如书的目录、工作单位的组织架构等等。树是计算机中非常重要的一种数据结构,树存储方式可以提高数据的存储、读取效率。
一、树的基本定义
日常生活中,很多事物都可以用树来描述,树是计算机中非常重要的一种数据结构,树存储方式可以提高数据的存储、读取效率,比如利用二叉排序树,既可以保证数据的检索速度,同时,也可以保证数据的插入、删除、修改的速度。
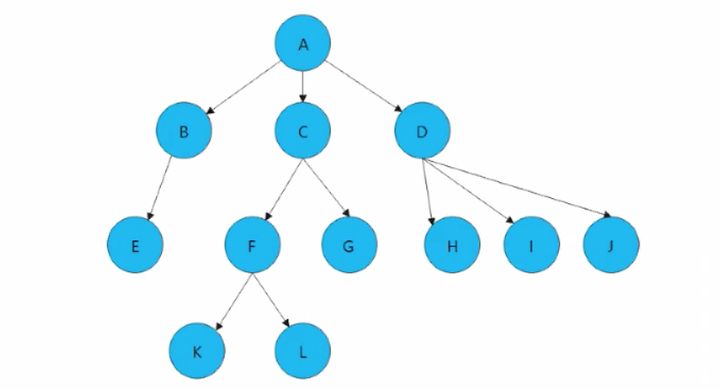
其实,树的种类有很多种,比如普通的二叉树、完全二叉树、满二叉树、线索二叉树、哈夫曼树、二叉排序树、平衡二叉树、AVL平衡二叉树、红黑树、B树、B+树、堆等。今天介绍的主要内容是二叉树的基本知识和几种基础类型的二叉树。
二、二叉树的相关术语
在正式开讲前,首先介绍一些关于二叉树的专业名词和术语,包括结点、结点的度、叶子结点、分支结点、结点的层次、树的度、树的深度等,了解这些基础的专业名词和术语对于我们理解二叉树的特性有非常重要的帮助作用。
1)结点:包含一个数据元素及若干指向子树分支的信息。
2)结点的度:一个结点拥有子树的数据成为结点的度。
3)叶子结点:也称为终端结点,没有子树的结点或者度为零的结点。
4)分支结点:也称为非终端结点,度不为零的结点成为非终端结点。
5)结点的层次:从根结点开始,根结点的层次为1,根的直接后继层次为2,以此类推。
6)树的度:树中所有结点的度的最大值。
7)树的深度:树中结点的最大层次。
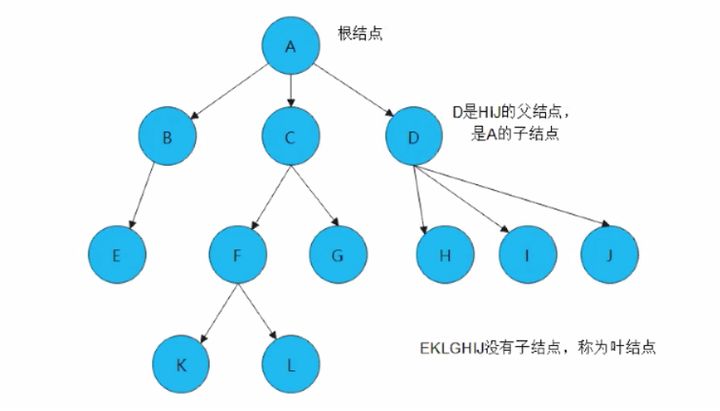
1. 树的特点
树作为一种特殊的数据结构,有非常多的特性,比如:
1)每个结点有多个或者零个子结点
2)没有父结点的结点成为根结点,没有子结点的结点成为叶结点
3)每一个非根结点只有一个父结点
4)每个结点及其后代结点整体上可以看做是一棵树,称为当前结点为根的子树
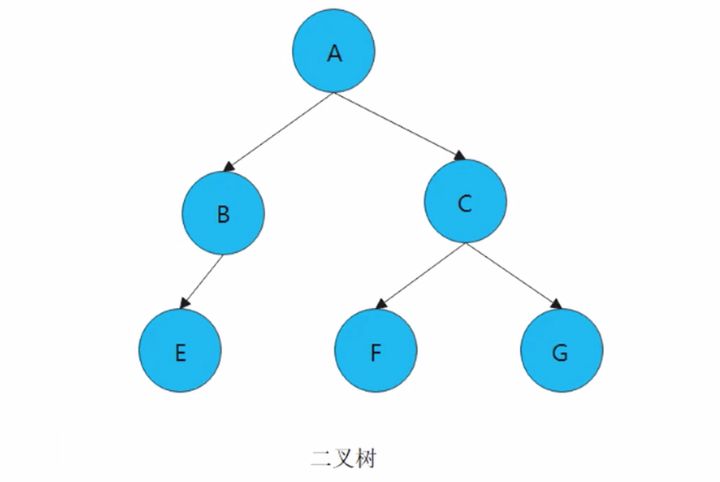
2. 二叉树的基本定义
1)二叉树就是度不超过2的树,其每个结点最多有两个子结点
2)二叉树的结点分为左结点和右结点
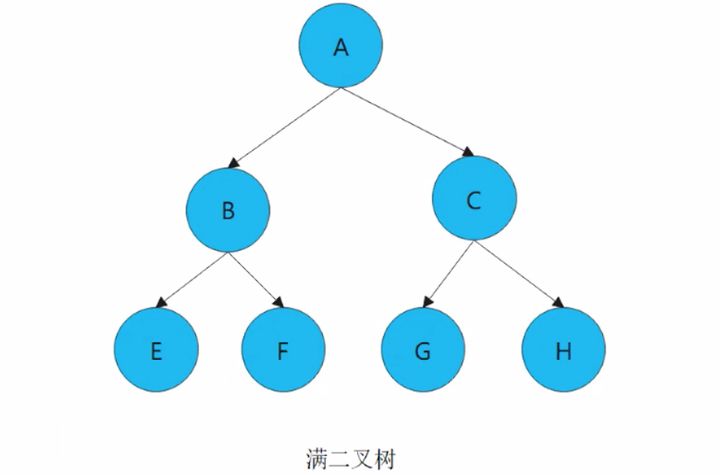
3. 满二叉树
1)二叉树的每一层的结点度都达到最大值,则这个二叉树就是满二叉树
2)一棵深度为n的满二叉树,有2^n-1个结点
4. 完全二叉树
叶子结点只能出现在最下层和次下层,最后一层的叶子结点在左边连续,倒数第二层的叶子结点在右边连续,我们称为完全二叉树。
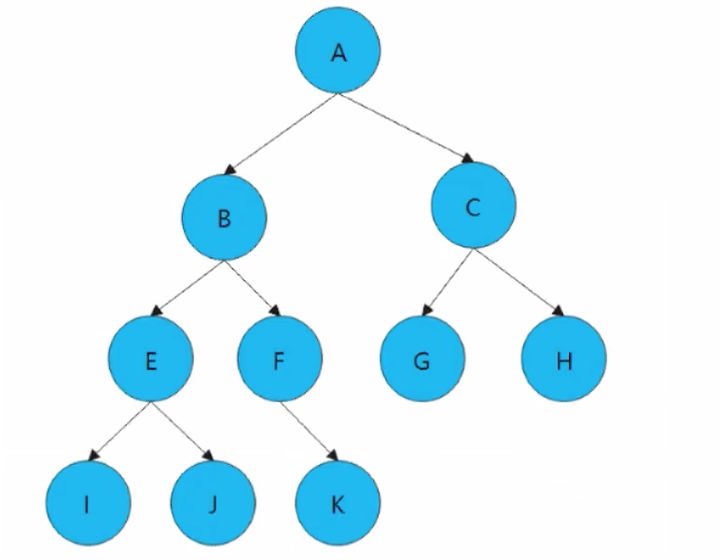
三、二叉树的创建
接下来,我们通过代码来描述二叉树,语言以Java为例,其中结点类定义如下:

二叉查找树类定义如下:

相关类定义好后,我们来看具体的方法实现,下面分别介绍。
1. size()方法
size()方法相对简单,每次添加元素加一,删除元素减一,维护一个公共的变量 num 即可,代码实现如下:

2. put(Key key,Value value)方法
put(Key key,Value value)方法可以利用重载方法 put(Node x,Key key,Value value),因此实现也相对简单,其中第一个参数只需要传根结点即可,代码实现如下:

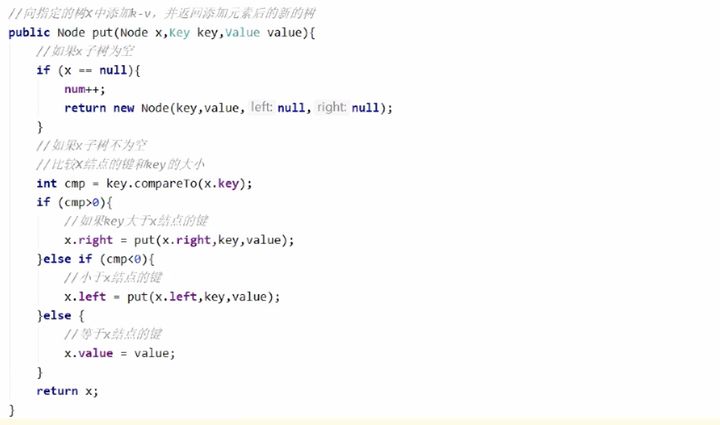
3. put(Node x,Key key,Value value)方法
put(Node x,Key key,Value value)方法应该是整个类中实现相对较为复杂的,下面进行简单的分析。
第一种情况,当前树中没有任何一个结点,直接将新插入的结点作为根结点。

第二种情况,当前树不为空,则从根结点开始。这种情况有可以细分为三种情况:
1)如果新结点的key小于当前结点的key,则继续查找当前结点的左子结点。
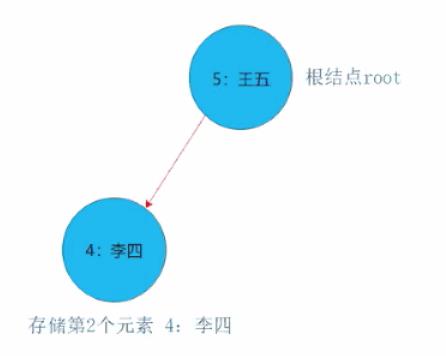
2)如果新结点的key大于当前结点的key,则继续查找当前结点的右子结点。
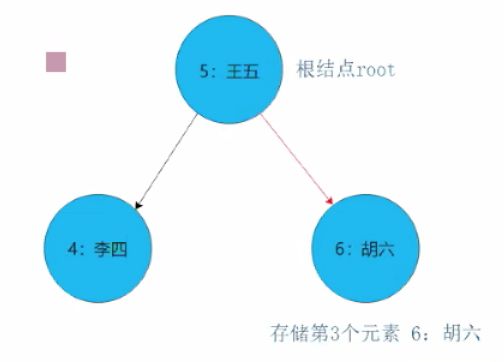
3)如果新结点的key等于当前结点的key,则树中已经存在这样的结点,替换该结点的value值即可。
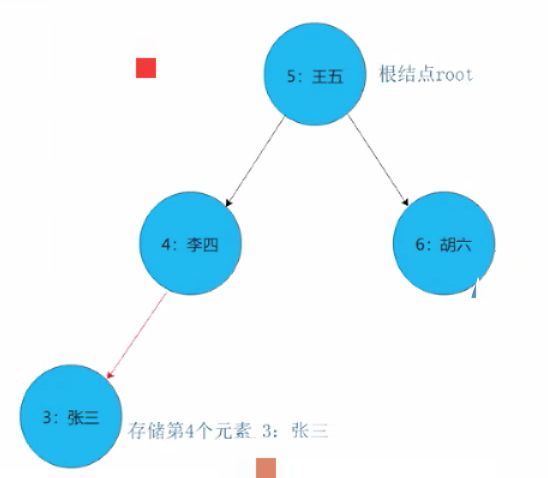
具体的代码实现如下:
4. get(Key key)方法
get(Key key)方法和 put(Key key,Value value)方法类似,也可以利用重载方法 get(Node x,Key key)来实现,代码实现如下:

5. get(Node x,Key key)方法
get(Node x,Key key)方法实现查询方法从根结点开始,如果要查询的key小于当前结点的key,则继续找当前结点的左子结点;如果要查找的key大于当前结点的key,则继续找当前结点的右子结点;如果要查找的key等于当前结点的key,则返回当前结点的value。
具体的代码实现如下:
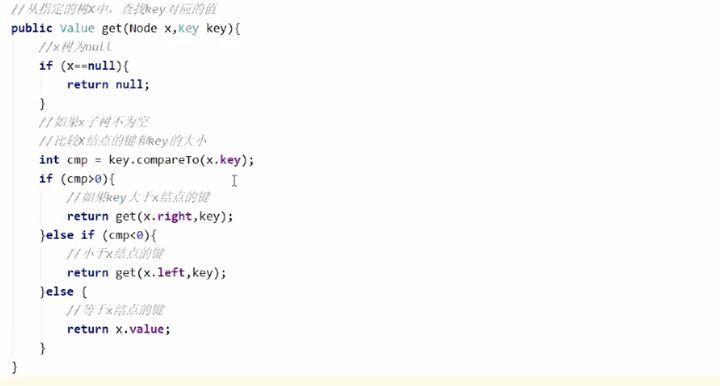
通过上面的代码,我们可以看出 get()方法和 put()方法类似,都是通过递归调用实现的。
6. delete(Key key)方法
delete(Key key)方法也是一样的思路,调用后面的重载方法就行了,代码实现如下:

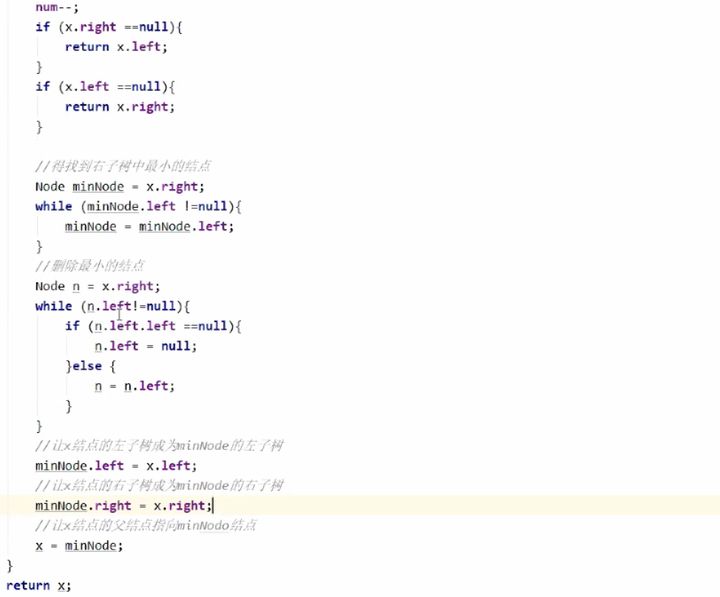
7. delete(Node x,Key key)方法
删除方法的实现思路,以最复杂的情况为例,首先找到被删除的结点,找到被删除结点右子树中的最小结点 minNode,删除右子树中的最小结点,让被删除结点的左子树成为最小结点 minNode 的左子树,让被删除结点右子树成为最小结点minNode的右子树,让被删除结点的父结点指向最小结点 minNode。
具体的代码实现如下:

既然代码已经写完了,接下来通过代码来验证一下,看看我们写得是否正确:

答案输出:
3
李四
2
Nice,太好了,通过上述输出结果已经证明了程序是正确的。
四、查找二叉树中最小和最大的键
比如二叉树中用来记录某个公司员工薪资和员工姓名数据,或者某班级学生们的排名和姓名数据。如何快速找出排名最高和最低的同学数据?
这样的话,该怎么做呢?其实,一般还可以整理出如下四个方法,定义如下:

1. min()方法
min()方法和上面提到的 get()和 put()方法类似,也可以使用下面的重载方法实现,具体代码如下:
// 找出树中最小的键
public key min() {
return min(root).key;
}2. min(Node x)方法
min(Node x)方法需要根据传入的结点位置,查找左子树中的最小的结点,如果为空,则直接返回空,具体代码实现如下:
// 找出树中最小键所在的结点
public Node min(Node x) {
if (x == null) {
return x;
}
Node minNode = x;
while (minNode.left != null) {
minNode = minNode.left;
}
return minNode;
}3. max()方法
max()方法和上面提到的 min()方法类似,也可以使用下面的重载方法实现,具体代码如下:
// 找出树中最小的键
public key max() {
return max(root).key;
}4. max(Node x)方法
max(Node x)方法需要根据传入的结点位置,查找右子树中的最大的结点,如果为空,则直接返回空,具体代码实现如下:
// 找出树中最大键所在的结点
public Node min(Node x) {
if (x == null) {
return x;
}
Node maxNode = x;
while (maxNode.right != null) {
maxNode = maxNode.right;
}
return maxNode;
}五、二叉树的遍历
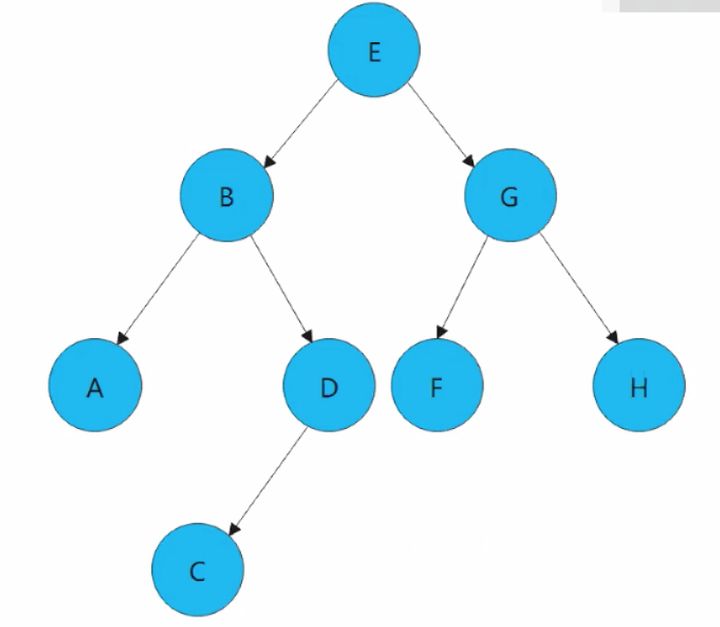
二叉树的遍历有三种方式,分别是前序遍历、中序遍历、后序遍历。
1. 前序遍历
先访问根结点,再访问左子树,最后访问右子树,比如下图中的二叉树,前序遍历结果如下:
EBADCGFH。
2. 中序遍历
先访问左子树,再访问根结点,最后访问右子树,比如下图中的二叉树,中序遍历结果如下:
ABCDEFGH。
3. 后序遍历
先访问左子树,再访问右子树,最后访问根结点,比如下图中的二叉树,后序遍历结果如下:
ACDBFHGE。
结论
二叉树的不仅在基础的数据结构方面有非常重要的研究意义,在实际应用中也有非常重要的应用场景,兼顾了常规数据结构数组和链表的优点,同时又避免了二者天生的不足。许多实际的问题抽象出来的数据结构往往是二叉树的形式,从而利用二叉树的存储结构和算法特性,因此学习二叉树就非常的必要。希望通过今天本文的介绍能够帮助大家深入理解和掌握二叉树。
以上是关于带你全面的了解二叉树的主要内容,如果未能解决你的问题,请参考以下文章