LeetCode 430. 扁平化多级双向链表 / 583. 两个字符串的删除操作 / 478. 在圆内随机生成点(拒绝采样圆形面积推导)
Posted Zephyr丶J
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LeetCode 430. 扁平化多级双向链表 / 583. 两个字符串的删除操作 / 478. 在圆内随机生成点(拒绝采样圆形面积推导)相关的知识,希望对你有一定的参考价值。
430. 扁平化多级双向链表
2021.9.24 每日一题
题目描述
多级双向链表中,除了指向下一个节点和前一个节点指针之外,它还有一个子链表指针,可能指向单独的双向链表。这些子列表也可能会有一个或多个自己的子项,依此类推,生成多级数据结构,如下面的示例所示。
给你位于列表第一级的头节点,请你扁平化列表,使所有结点出现在单级双链表中。
示例 1:
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
输出:[1,2,3,7,8,11,12,9,10,4,5,6]
解释:
输入的多级列表如下图所示:
扁平化后的链表如下图:
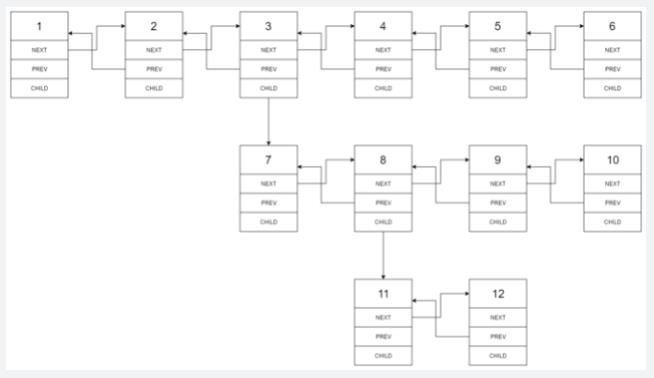

示例 2:
输入:head = [1,2,null,3]
输出:[1,3,2]
解释:
输入的多级列表如下图所示:
1---2---NULL
|
3---NULL
示例 3:
输入:head = []
输出:[]
如何表示测试用例中的多级链表?
以 示例 1 为例:
1---2---3---4---5---6--NULL
|
7---8---9---10--NULL
|
11--12--NULL
序列化其中的每一级之后:
[1,2,3,4,5,6,null]
[7,8,9,10,null]
[11,12,null]
为了将每一级都序列化到一起,我们需要每一级中添加值为 null 的元素,以表示没有节点连接到上一级的上级节点。
[1,2,3,4,5,6,null]
[null,null,7,8,9,10,null]
[null,11,12,null]
合并所有序列化结果,并去除末尾的 null 。
[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
提示:
节点数目不超过 1000
1 <= Node.val <= 10^5
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/flatten-a-multilevel-doubly-linked-list
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
首先要清楚,每一级最多只能有一个链表,多了用题中所给这个方法就表示不清楚了,这一点首先要明确,否则不知道怎么做
然后要利用child这个节点,找到这个节点,然后递归处理下面的部分
递归返回值为最后一个节点
首先判空,然后遍历,如果遍历到尾部了,都没有孩子,那么说明最后一层了,然后最后一层的最后一个节点,就是尾结点
然后有孩子,那么首先将后继节点succ保存下来,然后将孩子节点接到当前节点idx后面,然后递归处理孩子节点
得到end以后,如果end为空,那么说明下一层只有一个孩子节点,接好了已经,不需要处理
如果end不为null,那么end.next = succ
如果succ不为空,那么succ.prev = end
最后继续走到末尾,返回末尾的结点
错了两次,然后把所有情况都考虑进去了,说实话,如果要考虑清楚所有情况,真的不好做
/*
// Definition for a Node.
class Node {
public int val;
public Node prev;
public Node next;
public Node child;
};
*/
class Solution {
public Node flatten(Node head) {
//首先要明白这个链表是怎么表示的,如果说一级有多个结点有子链表
//第二级应该咋表示才不混淆呢,才能准确表示它是第一级的某个节点下的子链表,而不是第二级的
//我想了半天也没想出来,然后我就只能默认每一级只有一个节点有子链表
//如果每级只有一个链表的话,那问题就变的简单了
//首先找到每一级有子链表的位置
//刚刚没有用到这个child指针,首先找到有这个指针的位置,然后将它的next指向child指向的结点
dfs(head);
return head;
}
public Node dfs(Node node){
if(node == null)
return null;
Node idx = node;
//找到有孩子的结点
Node right = new Node(); //用于保存最后的结点
while(idx != null && idx.child == null){
right = idx;
idx = idx.next;
}
//如果没有孩子节点,说明到了最后一层,那么返回最右一个节点
if(idx == null)
return right;
//如果有孩子,保存它的后继节点
Node succ = idx.next;
//然后将next指向孩子
idx.next = idx.child;
idx.next.prev = idx;
//孩子指针置空
idx.child = null;
//递归处理下一级,得到末尾的结点
Node end = dfs(idx.next);
//如果后继节点为null,说明接上下面的链表以后,最后一个节点还是end
//那么就直接返回下一层的最后一个节点
if(succ == null)
return end;
//如果end为空,说明下一层只有这个孩子节点,已经接好了
//如果不为空,那么接在后面
if(end != null){
end.next = succ;
succ.prev = end;
}
//遍历找到本级的succ
Node temp = succ;
while(temp != null && temp.next != null){
temp = temp.next;
}
return temp;
}
}
迭代写一下,挺巧妙的
递归是将下面处理的结果的尾结点传上来,然后接在后面
迭代是将下面一层先接在后面,再处理下一层
/*
// Definition for a Node.
class Node {
public int val;
public Node prev;
public Node next;
public Node child;
};
*/
class Solution {
public Node flatten(Node head) {
//迭代写一下
Node dummy = new Node();
dummy.next = head;
while(head != null){
//如果孩子节点为null,那么就一直next
if(head.child == null){
head = head.next;
//如果不为空,那么处理下一层
}else{
Node succ = head.next;
head.next = head.child;
head.next.prev = head;
head.child = null;
//找到当前层的最后一个节点
Node idx = head;
while(idx.next != null){
idx = idx.next;
}
//然后将这个节点接在head后面
idx.next = succ;
if(succ != null)
succ.prev = idx;
head = head.next;
}
}
return dummy.next;
}
}
583. 两个字符串的删除操作
2021.9.25 每日一题
题目描述
给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。
示例:
输入: “sea”, “eat”
输出: 2
解释: 第一步将"sea"变为"ea",第二步将"eat"变为"ea"
提示:
给定单词的长度不超过500。
给定单词中的字符只含有小写字母。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/delete-operation-for-two-strings
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
转化成最长公共子序列
class Solution {
public int minDistance(String word1, String word2) {
//其实要找的就是最长公共子序列,动态规划问题
int l1 = word1.length();
int l2 = word2.length();
int[][] dp = new int[l1 + 1][l2 + 1];
for(int i = 1; i <= l1; i++){
for(int j = 1; j <= l2; j++){
if(word1.charAt(i - 1) == word2.charAt(j - 1))
dp[i][j] = dp[i - 1][j - 1] + 1;
else{
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return l1 + l2 - dp[l1][l2] * 2;
}
}
或者直接定义删除的dp
class Solution {
public int minDistance(String word1, String word2) {
//dp以i结尾的字符串变成以j结尾的字符串需要的最少步数
//如果两个字符不相同,那么就都删除,也就是+2
//如果相同,就不用管,看前两个方向的最小值
int l1 = word1.length();
int l2 = word2.length();
int[][] dp = new int[l1 + 1][l2 + 1];
for(int i = 0; i <= l1; i++){
dp[i][0] = i;
}
for(int j = 1; j <= l2; j++){
dp[0][j] = j;
}
for(int i = 1; i <= l1; i++){
for(int j = 1; j <= l2; j++){
if(word1.charAt(i - 1) == word2.charAt(j - 1)){
dp[i][j] = dp[i - 1][j - 1];
}
else
dp[i][j] = Math.min(dp[i - 1][j], dp[i][j - 1]) + 1;
}
}
return dp[l1][l2];
}
}
478. 在圆内随机生成点
题目描述
给定圆的半径和圆心的 x、y 坐标,写一个在圆中产生均匀随机点的函数 randPoint 。
说明:
- 输入值和输出值都将是浮点数。
- 圆的半径和圆心的 x、y 坐标将作为参数传递给类的构造函数。
- 圆周上的点也认为是在圆中。
- randPoint 返回一个包含随机点的x坐标和y坐标的大小为2的数组。
示例 1:
输入:
[“Solution”,“randPoint”,“randPoint”,“randPoint”]
[[1,0,0],[],[],[]]
输出: [null,[-0.72939,-0.65505],[-0.78502,-0.28626],[-0.83119,-0.19803]]
示例 2:
输入:
[“Solution”,“randPoint”,“randPoint”,“randPoint”]
[[10,5,-7.5],[],[],[]]
输出: [null,[11.52438,-8.33273],[2.46992,-16.21705],[11.13430,-12.42337]]
输入语法说明:
输入是两个列表:调用成员函数名和调用的参数。Solution 的构造函数有三个参数,圆的半径、圆心的 x 坐标、圆心的 y 坐标。randPoint 没有参数。输入参数是一个列表,即使参数为空,也会输入一个 [] 空列表。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/generate-random-point-in-a-circle
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
昨天看的随机数生成,今天来做一下
用那天的拒绝采样,如果生成的随机数不满足条件,就拒绝
注意生成的x,y的坐标
class Solution {
//我想到的是画一个正方形,然后边长是圆的直径
//然后在正方形内生成随机数,随机数的范围就是[-r,r]
//然后用勾股定理算距离,如果在半径范围内,就说明满足条件,否则拒绝
double r;
Random random;
double x0;
double y0;
public Solution(double radius, double x_center, double y_center) {
r = radius;
x0 = x_center;
y0 = y_center;
random = new Random();
}
public double[] randPoint() {
while(true){
double ran1 = random.nextDouble(); //生成0到1的随机double
double ran2 = random.nextDouble();
double x = ran1 * 2 * r - r + x0; //[0,2r] - r = -r,r
double y = ran2 * 2 * r - r + y0;
double xabs = x - x0;
double yabs = y - y0;
if(xabs * xabs + yabs * yabs <= r * r){
return new double[]{x, y};
}
}
}
}
/**
* Your Solution object will be instantiated and called as such:
* Solution obj = new Solution(radius, x_center, y_center);
* double[] param_1 = obj.randPoint();
*/
第二种方法,看了官解,再看了看别人的,理解了一下
首先,因为圆的面积是 π r 平方,所以生成半径为x的点的概率是x平方除以r平方
所以生成一个0到1的随机数 t,就当做x的平方,也就是说在单位圆内生成了一个点,是随机的
然后要求的是这个点的坐标
首先,对这个随机数t开方,取到x,也就是圆心到这个点的距离
但是,得到了这个距离,只能是说找到了一个圆环,但是在这个圆环上取哪个点,还需要随机
所以还要生成一个随机数,表示角度
也就是高中学的那种用0到2π表示圆角度的公式,忘了叫什么了
所以用 random * 2 * π 生成这个角度
然后cos、sin求位置
用到Math.PI
Math.cos
Math.sin
class Solution {
//用圆的面积来思考
double r;
Random random;
double x0;
double y0;
public Solution(double radius, double x_center, double y_center) {
r = radius;
x0 = x_center;
y0 = y_center;
random = new Random();
}
public double[] randPoint() {
double rad = r * Math.sqrt(random.nextDouble()); //半径长度
double theta = random.nextDouble() * 2 * Math.PI;
double x = x0 + rad * Math.cos(theta);
double y = y0 + rad * Math.sin(theta);
return new double[]{x, y};
}
}
/**
* Your Solution object will be instantiated and called as such:
* Solution obj = new Solution(radius, x_center, y_center);
* double[] param_1 = obj.randPoint();
*/
以上是关于LeetCode 430. 扁平化多级双向链表 / 583. 两个字符串的删除操作 / 478. 在圆内随机生成点(拒绝采样圆形面积推导)的主要内容,如果未能解决你的问题,请参考以下文章