联邦学习——一种基于分布和知识蒸馏的聚合策略
Posted LeoJarvis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了联邦学习——一种基于分布和知识蒸馏的聚合策略相关的知识,希望对你有一定的参考价值。
《FEDBE: Making Bayesian Model Ensemble Applicable to Federated Learning》是ICLR 2021的一篇文章。该文章主要提出了一种新的聚合策略,该策略在 multi-round FL 以及 Non-IID 下具有不错的表现。这里我主要总结这个策略的思路。
- 构建模型分布:首先客户端将本地训练好的模型发送给服务端,服务端应用 Dirichlet 或 Bayesian 构建模型的分布,具体构建方法可以看论文,其中用到的蒙特卡洛方法可以参考【怎么通俗理解蒙特卡洛模拟?】。
- 模型采样:服务端对所构建的模型分布进行采样,得到 model ensemble,注意,这里采样得到的是多个模型,是无法应用于联邦学习的(服务端只把一个模型发送给客户端)。那么就需要把这多个模型聚合成一个,但这里又不像 FedAvg 可以根据数据量大小来进行聚合,因此这篇文章提出了一个新的方法。
- 模型聚合:文章假设服务端可以收集到一些无标签数据,然后以集成学习的方法用采样得到的 model ensemble 对数据进行预测,将预测结果作为伪标签,进而以知识蒸馏的方式将 model ensemble 总结为 single global model。具体是以伪标签为 teacher,single global model 为 student。
- 有一个问题是,集成学习预测出的伪标签实际存在很多噪声,为了预防 single global model 对噪声过拟合,文章在蒸馏过程中应用了 stochastic weight average(SWA)。SWA采样"循环学习率"执行随机梯度下降(SGD),并对 traversed models(个人理解为model ensemble) 的权值平均化,使 traversed models 能跳出嘈杂的局部最小值,从而使 student 更加 robust。
- 伪代码如下,其中 Equation 5 和 Equation 7 分别为采用 Bayesian 和 Dirichlet 构建模型分布的公式。

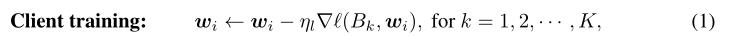

以上是关于联邦学习——一种基于分布和知识蒸馏的聚合策略的主要内容,如果未能解决你的问题,请参考以下文章