详解基于 Cortex-M3 的任务调度(下)
Posted 车子 chezi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解基于 Cortex-M3 的任务调度(下)相关的知识,希望对你有一定的参考价值。
在 详解基于 Cortex-M3 的任务调度(上)_车子(chezi)-CSDN博客 这篇文章中,我们已经有了理论基础,这篇文章,我们写代码实践一下。
代码基于网友提供的工程和书中的参考代码修改而成,不求面面俱到,只求讲清原理。
工程说明
我用的是 STM32F103 这款芯片,工程结构如图:
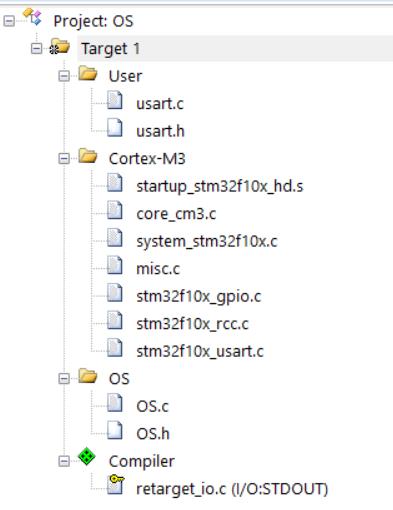
User 下面是串口的裸板驱动,调用官方的库函数,非常套路化;
Cortex-M3 下面是厂家提供的文件,一般不用修改;
OS 下面是本文的重点,任务调度的精髓就在里面;
Compiler 下面是我添加的组件,由 ARM 提供,也不用修改。方便没有板子的时候也可以用 PC 模拟运行。
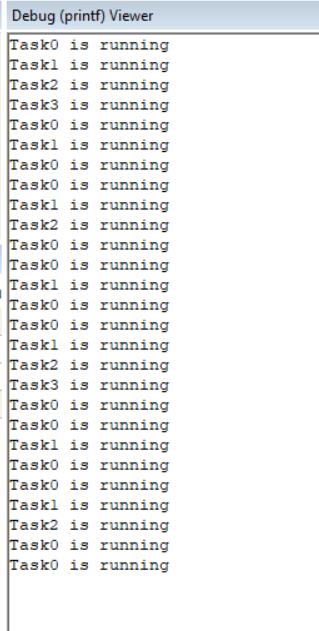
实验结果
结果就是 4 个任务轮流执行。虽然每个任务代码中都有 while(1),但是它不会一直占用 CPU,当它的时间片到了,OS 就会剥夺它对 CPU 的使用权,让下一个任务运行。
如果你有板子,那么就用串口输出。需要在 RTE_Components.h 文件中注释掉这两行
//#define RTE_Compiler_IO_STDOUT /* Compiler I/O: STDOUT */
//#define RTE_Compiler_IO_STDOUT_ITM /* Compiler I/O: STDOUT ITM */
如果没有板子,在仿真的时候,打开 Debug(printf) Viewer 窗口就可以了。
代码讲解
时钟节拍
上一篇博文说过,系统滴答定时器(SYSTICK)中断是要有的,在这个中断里面触发任务切换。
void OSSysTickInit(void)
{
//Systick定时器初使化
char *Systick_priority = (char *)0xe000ed23; //Systick中断优先级寄存器
SysTick->LOAD = (SystemCoreClock/8/1000000)* 1000; //Systick定时器重装载 计数9000次=1ms
*Systick_priority = 0x00; //Systick定时器中断优先级
SysTick->VAL = 0; //Systick定时器计数器清0
SysTick->CTRL = 0x3;//Systick打开并使能中断,且使用外部晶振时钟,8分频 72MHz/8=9MHz 计数9000次=1ms 计数9次=1us
}
配置 SYSTICK 的计数频率,然后使能 SYSTICK 和中断。
如果 SystemCoreClock 是 72MHz,就是 1ms 一次中断。
void SysTick_Handler(void) // 1KHz
{
System.TimeMS++; //系统时钟节拍累加
if((--System.TaskTimeSlice) == 0) {
System.TaskTimeSlice = TASK_TIME_SLICE;//重置时间片初值
task_switch();
}
}
以上就是 SYSTICK 中断处理函数。System.TaskTimeSlice 的初始值是 10;
在 main() 中有初始化的语句:
System.TaskTimeSlice = TASK_TIME_SLICE; // #define TASK_TIME_SLICE 10
System.OSRunning = OS_TRUE;
System.TimeMS = 0;
也就是说 10ms 切换一次任务。
注意,这是基于时间片的任务调度,而不是基于优先级。
任务切换 task_switch()
void task_switch(void)
{
if(System.OSLockNesting != 0)
return;
switch(curr_task) {
case(0):
next_task=1;
break;
case(1):
next_task=2;
break;
case(2):
next_task=3;
break;
case(3):
next_task=0;
break;
default:
next_task=0;
stop_cpu;
break; // Should not be here
}
if (curr_task != next_task){ // Context switching needed
SCB->ICSR |= SCB_ICSR_PENDSVSET_Msk; // Set PendSV to pending
}
}
第 3 行:判断是否给调度器加锁了,如果是,就禁止任务切换,直接返回。
切换的逻辑很简单,只有 0-3 个任务, 0 切到 1,1 切到 2,…。next_task 是个全局变量,记录下一个任务编号。
第 26 行很重要,设置 PendSV 中断悬起。当 SYSTICK 中断服务退出后,马上就会进入 PendSV 中断服务。
这个函数虽然叫 task_switch,但是真正的切换是在 PendSV 中断服务里面。
PendSV_Handler
__asm void PendSV_Handler(void)
{
// Simple version - assume No floating point support
// Save current context
MRS R0, PSP // Get current process stack pointer value
STMDB R0!,{R4-R11} // Save R4 to R11 in task stack (8 regs)
LDR R1,=__cpp(&curr_task)
LDR R2,[R1] // Get current task ID
LDR R3,=__cpp(&PSP_array)
STR R0,[R3, R2, LSL #2] // Save PSP value into PSP_array
// Load next context
LDR R4,=__cpp(&next_task)
LDR R4,[R4] // Get next task ID
STR R4,[R1] // Set curr_task = next_task
LDR R0,[R3, R4, LSL #2] // Load PSP value from PSP_array
LDMIA R0!,{R4-R11} // Load R4 to R11 from taskstack (8 regs)
MSR PSP, R0 // Set PSP to next task
BX LR // Return
ALIGN 4
}
这段代码虽然短,但它是任务切换的精髓,简而言之就是保存当前任务的上下文,加载下一个任务的上下文。
在 PendSV_Handler 发生后,会有 8 个寄存器被自动压栈,7-8 行用来手动压栈另外 8 个寄存器。
我们一句一句说。
第 7 行:MRS R0, PSP
加载栈指针到 R0,也就是找到当前任务的栈
第 8 行:STMDB R0!,{R4-R11}
R0 = R0-4, 把 R11 的值存入 R0 指向的内存;然后 R0 = R0-4,把 R10 的值存入 R0 指向的内存;…
为了更加直观,我弄了一幅图:
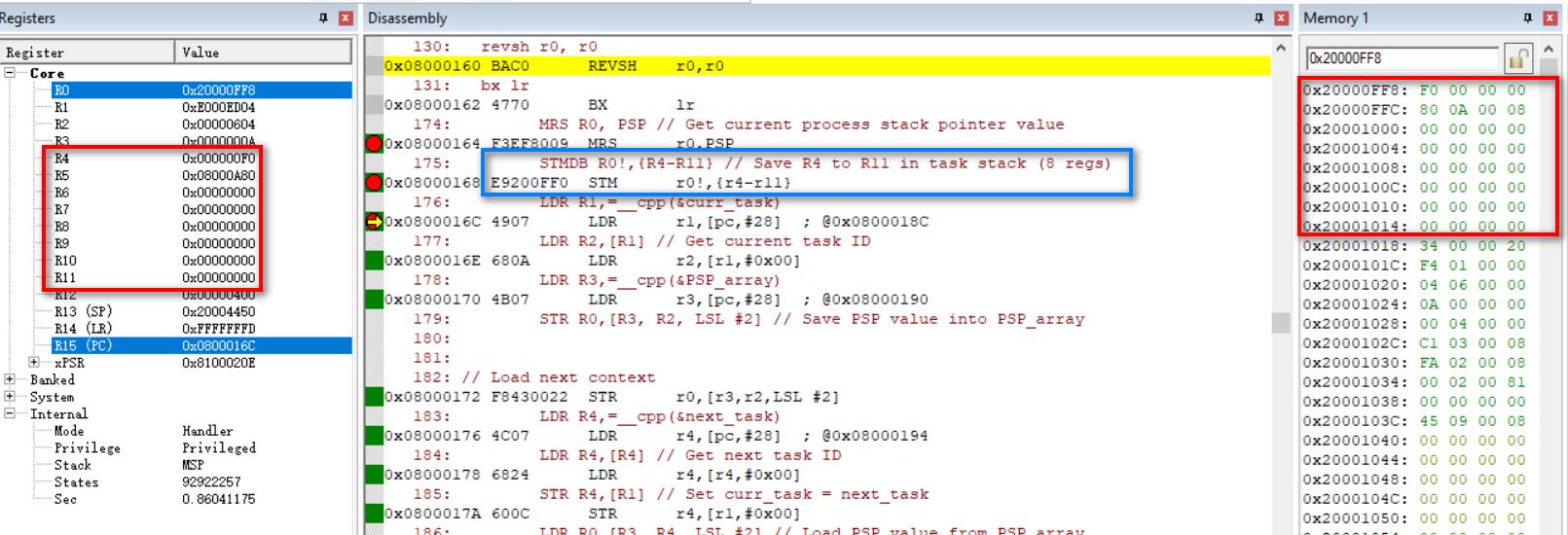
这张图是刚压栈后的情况,可以看到,R4 是最后被压进去的。右边的方框展示的是某个任务的栈。
第 9 行:LDR R1,=__cpp(&curr_task)
这句话的意思是把变量 curr_task 的地址赋值给 R1
第 10 行:LDR R2,[R1] // Get current task ID
取 R1 指向的内容给 R2,也就是获得当前任务的编号
第 11 行:LDR R3,=__cpp(&PSP_array)
取数组 PSP_array[] 的地址给 R3
第 12 行:STR R0,[R3, R2, LSL #2]
相当于伪码 STR R0,[R3, R2<<2],也就是 STR R0,[R3 + R2*4]
因为 R2 里面是当前任务的编号,所以 [R3 + R2*4] 是根据任务编号索引 PSP_array 数组(每个元素占 4 个字节),意思是把 R0 的值保存到 PSP_array[R2] ,结合 R0 指向当前任务的栈,就是要把当前任务的栈指针保存到数组中。
上面这一番操作,其实是保存当前任务的上下文。
我们继续看代码:
LDR R4,=__cpp(&next_task)
LDR R4,[R4] // Get next task ID
STR R4,[R1] // Set curr_task = next_task
LDR R0,[R3, R4, LSL #2] // Load PSP value from PSP_array
LDMIA R0!,{R4-R11} // Load R4 to R11 from taskstack (8 regs)
MSR PSP, R0 // Set PSP to next task
BX LR // Return
1:取得变量 next_task 的地址给 R4
2:把 R4 指向的内容给 R4,也就是得到下一个任务的编号
3:存储 R4 的值到 R1 指向的内存,R1 是 curr_task 的指针,所以就是把下一个任务的编号赋值给变量 curr_task ,用 C 语言表示就是 curr_task = next_task;
4:相当于 LDR R0,[R3, R4*4],即以 R4 的值为下标索引 PSP_array 数组,把里面的值给 R0,连起来就是获得下一个任务的 PSP 到 R0
5:手动出栈,把下一个任务的栈上面的 8 个值恢复到对应的寄存器。剩下 8 个怎么办?会在中断返回的时候自动出栈。IA 表示每次传送后地址增加 4,出栈顺序是先 R4, 再 R5,…,最后 R11
6:用 R0 调整栈指针 PSP,为后面的自动出栈做准备
7:启动异常返回流程
以上语句执行后,就会切换到下一个任务。
任务的代码
void task0(void) //任务0
{
while(1)
{
OSprintf("Task0 is running\\r\\n");
OS_delayMs(500); //任务延时
}
}
void task1(void) //任务1
{
while(1)
{
OSprintf("Task1 is running\\r\\n");
OS_delayMs(1000); //任务延时
}
}
void task2(void) //任务2
{
while(1)
{
OSprintf("Task2 is running\\r\\n");
OS_delayMs(2000); //任务延时
}
}
void task3(void) //任务3
{
while(1)
{
OSprintf("Task3 is running\\r\\n");
OS_delayMs(4000); //任务延时
}
}
很傻瓜地搞了四个任务,每个任务都向串口输出一句话。
OSprintf 中有一个给调度器上锁和解锁的操作,防止每个任务的打印混淆在一起。有关的代码是:
#define OS_CORE_ENTER __disable_irq
#define OS_CORE_EXIT __enable_irq
#define OSprintf(fmt, ...) \\
{ OSSchedLock(); printf( fmt, ##__VA_ARGS__); OSSchedUnlock();}
//系统布尔值
#define OS_FALSE 0
#define OS_TRUE 1
//系统变量类型定义
typedef struct
{
INT8U OSRunning; //运行标志变量
INT8U OSLockNesting; //任务切换锁定层数统计变量
volatile INT32U TimeMS; //系统时钟节拍累计变量
INT32U TaskTimeSlice; //任务时间片
}SYSTEM;
//系统变量
SYSTEM System;
void OSSchedLock(void) //任务切换锁定
{
OS_CORE_ENTER(); // 关中断
if(System.OSRunning == OS_TRUE)
{
if (System.OSLockNesting < 255u) // 任务锁定可以最大嵌套 255 层
System.OSLockNesting++;
}
OS_CORE_EXIT(); // 开中断
}
void OSSchedUnlock(void) //任务切换解锁
{
OS_CORE_ENTER();
if(System.OSRunning == OS_TRUE)
{
if (System.OSLockNesting > 0)
System.OSLockNesting--;
}
OS_CORE_EXIT();
}
INT32U GetTime(void)
{
return System.TimeMS;
}
void OS_delayMs(INT32U ms)
{
INT32U counter;
counter = GetTime() + ms;
while(1){
if(counter < GetTime())
break;
}
}
OS_delayMs 这个函数有点问题,没有考虑到定时器的溢出。另外,OS_delayMs 这个函数不会挂起当前任务。比较好的做法是当任务调用这个函数的时候,主动放弃 CPU,这时候 CPU 可以选择其他任务执行。当延时时间到了,被挂起任务再恢复到就绪态。
重要的全局变量
// Stack for each task (4K bytes each)
unsigned int task0_stack[1024],
task1_stack[1024],
task2_stack[1024],
task3_stack[1024];
// Data use by OS
uint32_t curr_task = 0; // Current task
uint32_t next_task = 1; // Next task
uint32_t PSP_array[4]; // Process Stack Pointer for each task
2-5:定义了 4 个数组,分别对应 4 个任务的栈
10-11:curr_task 记录当前任务的编号,next_task 记录下一个任务的编号
12:数组 PSP_array 用来保存每个任务的栈指针。
其实管理任务应该有个 TCB(任务控制块),但是我们的代码比较简陋(防止喧宾夺主),所以就用这些全局变量对付了。
main() 函数
铺垫了那么多,终于来到主函数。
#define HW32_REG(ADDRESS) (*((volatile unsigned long *)(ADDRESS)))
int main(void)
{
USART1_Config(115200); //串口1初使化
System.TaskTimeSlice = TASK_TIME_SLICE; // 设置时间片为 10ms
System.OSRunning = OS_TRUE;
System.TimeMS = 0;
SCB->CCR |= SCB_CCR_STKALIGN_Msk;
// Enable double word stack alignment
//(recommended in Cortex-M3 r1p1, default in Cortex-M3 r2px and Cortex-M4)
// Create stack frame for task0
PSP_array[0] = ((unsigned int) task0_stack) + (sizeof task0_stack) - 16*4;
HW32_REG((PSP_array[0] + (14<<2))) = (unsigned long) task0;
// initial Program Counter
HW32_REG((PSP_array[0] + (15<<2))) = 0x01000000; // initial xPSR
// Create stack frame for task1
PSP_array[1] = ((unsigned int) task1_stack) + (sizeof task1_stack) - 16*4;
HW32_REG((PSP_array[1] + (14<<2))) = (unsigned long) task1;
// initial Program Counter
HW32_REG((PSP_array[1] + (15<<2))) = 0x01000000; // initial xPSR
// Create stack frame for task2
PSP_array[2] = ((unsigned int) task2_stack) + (sizeof task2_stack) - 16*4;
HW32_REG((PSP_array[2] + (14<<2))) = (unsigned long) task2;
// initial Program Counter
HW32_REG((PSP_array[2] + (15<<2))) = 0x01000000; // initial xPSR
// Create stack frame for task3
PSP_array[3] = ((unsigned int) task3_stack) + (sizeof task3_stack) - 16*4;
HW32_REG((PSP_array[3] + (14<<2))) = (unsigned long) task3;
// initial Program Counter
HW32_REG((PSP_array[3] + (15<<2))) = 0x01000000; // initial xPSR
curr_task = 0; // Switch to task #0 (Current task)
__set_PSP((PSP_array[curr_task] + 16*4)); // Set PSP to top of task 0 stack
NVIC_SetPriority(PendSV_IRQn, 0xFF); // Set PendSV to lowest possible priority
OSSysTickInit();
__set_CONTROL(0x3); // Switch to use Process Stack, unprivileged state
__ISB(); // Execute ISB after changing CONTROL (architectural recommendation)
task0(); // Start task 0
while(1){
stop_cpu;// Should not be here
};
}
比较重要的是创建每个任务的栈帧,比如
// Create stack frame for task0
PSP_array[0] = ((unsigned int) task0_stack) + (sizeof task0_stack) - 16*4;
HW32_REG((PSP_array[0] + (14<<2))) = (unsigned long) task0;
// initial Program Counter
HW32_REG((PSP_array[0] + (15<<2))) = 0x01000000; // initial xPSR
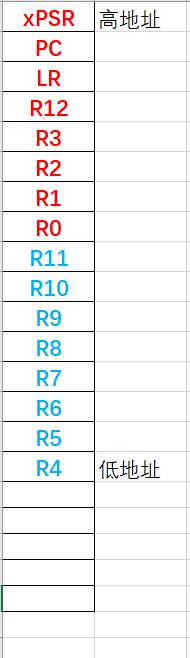
当在 PendSV_Handler 中进行切换的时候,要手动出栈 8 个寄存器(蓝色),另外 8 个寄存器(红色)会自动出栈,对于要切换的任务(将要运行的任务),它的栈指针应该指向 R4
所以第 2 行:PSP_array[0] = ((unsigned int) task0_stack) + (sizeof task0_stack) - 16*4;
后面减去 16*4 表示要预留出这 16 个寄存器的位置,把 PSP 指向 R4
这 16 个寄存器中有 2 个要给初始值,一个是 PC,要指向任务的入口函数;还有一个是 xPSR


xPSR 的 bit[24] 必须是 1,表示 Thumb state,所以会有代码
HW32_REG((PSP_array[0] + (15<<2))) = 0x01000000; // initial xPSR
继续看代码
curr_task = 0; // Switch to task #0 (Current task)
__set_PSP((PSP_array[curr_task] + 16*4)); // Set PSP to top of task 0 stack
NVIC_SetPriority(PendSV_IRQn, 0xFF); // Set PendSV to lowest possible priority
OSSysTickInit(); // SysTick 初始化和使能
__set_CONTROL(0x3); // Switch to use Process Stack, unprivileged state
__ISB(); // Execute ISB after changing CONTROL (architectural recommendation)
task0(); // Start task 0
第 2 行:因为前面设置好了栈帧,PSP_array[0] 其实是指向 task0 的栈(上面图中 R4 的位置),但是 task0 先运行,它不是在 PendSV_Handler 中切换过去的,而是通过调函数 task0() 来开始执行的,所以它的栈应该是空的,也就是要把它的 PSP 调整到最高处,所以要加上 16*4
第 3 行:把 PendSV_Handler 设置成最低的优先级,为什么这样,可以看我的前一篇博文:详解基于 Cortex-M3 的任务调度(上)_车子(chezi)-CSDN博客
第 6 行:使用 PSP,且运行在非特权级
第 7 行:指令同步屏障。用来清空流水线,确保在执行新的指令前,前面的指令都已执行完毕。


第 8 行:执行 task0。其实执行第一个任务还有别的方法,比如触发 PendSV_Handler,在中断里面“切换”到 task0
以上就是本文全部内容,欢迎读者批评指正。
代码下载
链接:https://pan.baidu.com/s/1dnl7Cld97hujA3OoxGfd3Q
提取码:chez
参考资料
【1】《Cortex-M3 权威指南 》
【2】《The Definitive Guide to ARM Cortex-M3 and Cortex-M4 Processors(Third Edition)》
以上是关于详解基于 Cortex-M3 的任务调度(下)的主要内容,如果未能解决你的问题,请参考以下文章
Linux下定时任务(系统任务调度、用户任务调度)crontab使用详解