Leetcode——扁平化多级双向链表
Posted Yawn,
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Leetcode——扁平化多级双向链表相关的知识,希望对你有一定的参考价值。
1. 扁平化多级双向链表
多级双向链表中,除了指向下一个节点和前一个节点指针之外,它还有一个子链表指针,可能指向单独的双向链表。这些子列表也可能会有一个或多个自己的子项,依此类推,生成多级数据结构,如下面的示例所示。
给你位于列表第一级的头节点,请你扁平化列表,使所有结点出现在单级双链表中。
示例 1:
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
输出:[1,2,3,7,8,11,12,9,10,4,5,6]
解释:
输入的多级列表如下图所示:
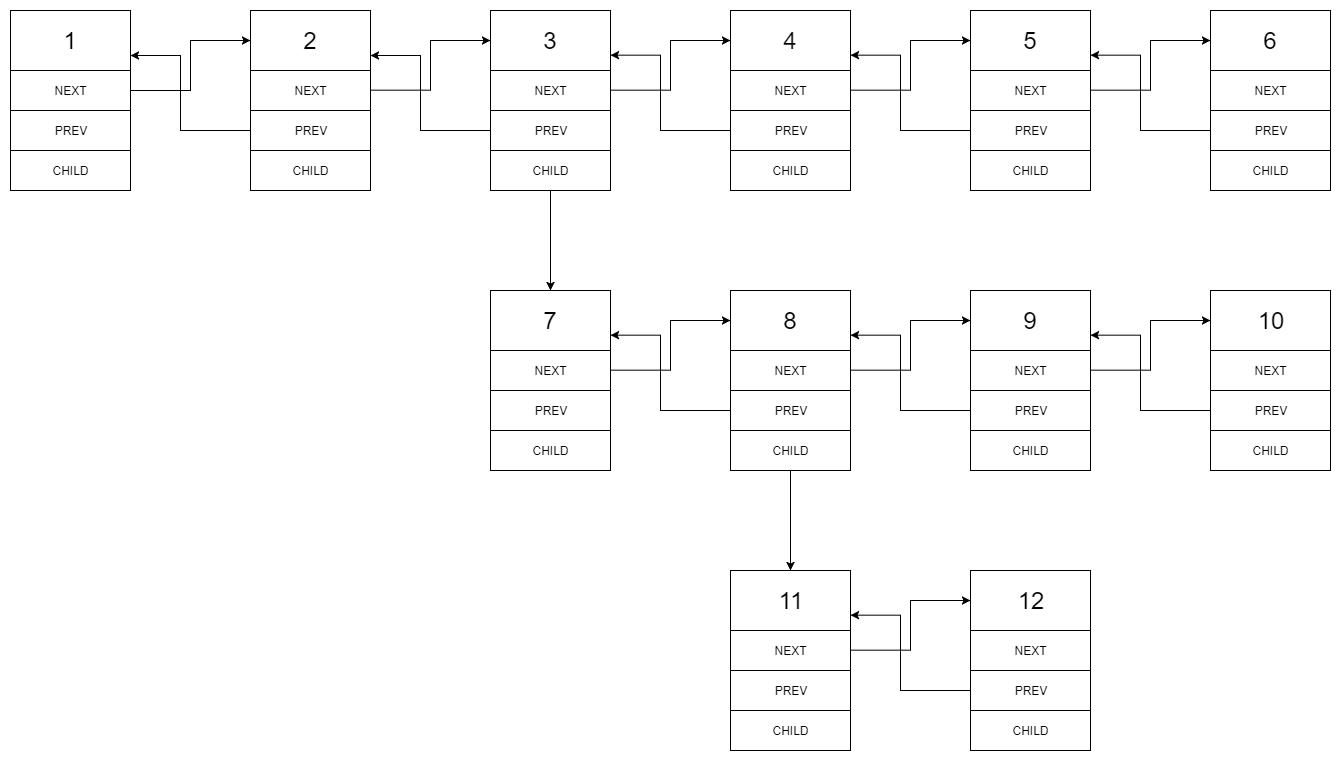
扁平化后的链表如下图:


(1)递归(模拟)
为防止空节点等边界问题,起始时建立一个哨兵节点 dummy 指向 head,然后利用 head 指针从前往后处理链表:
- 当前节点 head 没有 child 节点:直接让指针后即可,即 head = head.nexthead=head.next;
- 当前节点 head 有 child 节点:将 head.child 传入函数 flatten 递归处理,拿到普遍化后的头结点 chead,然后将 head 和 chead 建立“相邻”关系(注意要先存起来原本的 tmp = head.next 以及将 head.child置空),然后继续往后处理,直到扁平化的 chead 链表的尾部,将其与 tmp 建立“相邻”关系。
/*
// Definition for a Node.
class Node {
public int val;
public Node prev;
public Node next;
public Node child;
};
*/
class Solution {
public Node flatten(Node head) {
Node dummy = new Node(0);
dummy.next = head;
while (head != null) {
if (head.child == null) {
head = head.next;
} else {
//存储下一个节点
Node tmp = head.next;
//开始遍历子节点,直到遍历完最后一个子节点
Node chead = flatten(head.child);
head.next = chead;
chead.prev = head;
head.child = null; //将 head.child置空
while (head.next != null)
head = head.next;
//开始继续遍历下一个节点(非子节点)
head.next = tmp;
if (tmp != null)
tmp.prev = head;
head = tmp;
}
}
return dummy.next;
}
}
(2)递归(优化)
上述解法中,由于我们直接使用 flatten 作为递归函数,导致递归处理 head.childhead.child 后不得不再进行遍历来找当前层的“尾结点”,这导致算法复杂度为 O(n2)
可以额外设计一个递归函数 dfs 用于返回扁平化后的链表“尾结点”,从而确保我们找尾结点的动作不会在每层发生。
/*
// Definition for a Node.
class Node {
public int val;
public Node prev;
public Node next;
public Node child;
};
*/
class Solution {
public Node flatten(Node head) {
dfs(head);
return head;
}
public Node dfs(Node head) {
Node last = head;
while (head != null) {
//如果没有子节点
if (head.child == null) {
last = head;
head = head.next;
}
else {
//存储下一个节点
Node tmp = head.next;
//开始遍历子节点,直到遍历完最后一个子节点
Node childLast = dfs(head.child);
head.next = head.child;
head.child.prev = head;
head.child = null;
//开始继续遍历下一个节点(非子节点)
if (childLast != null)
childLast.next = tmp;
if (tmp != null)
tmp.prev = childLast;
last = head;
head = childLast;
}
}
return last;
}
}
(3)迭代
与「递归」不同的是,「迭代」是以“段”为单位进行扁平化,而「递归」是以深度(方向)进行扁平化,这就导致了两种方式对每个扁平节点的处理顺序不同。
递归 的处理节点(新的 nextnext 指针的构建)顺序为:
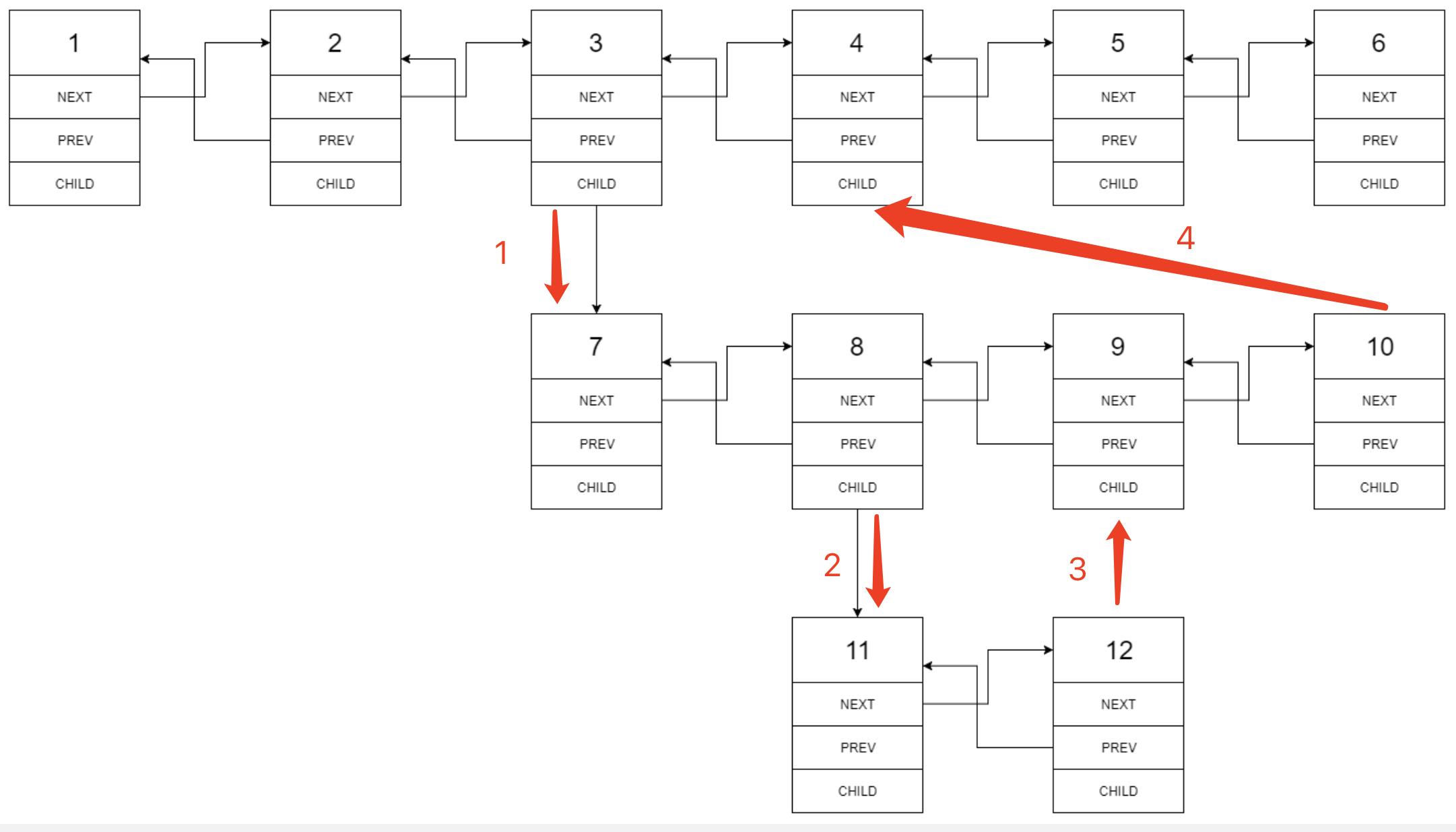
迭代 的处理节点(新的 nextnext 指针的构建)顺序为:
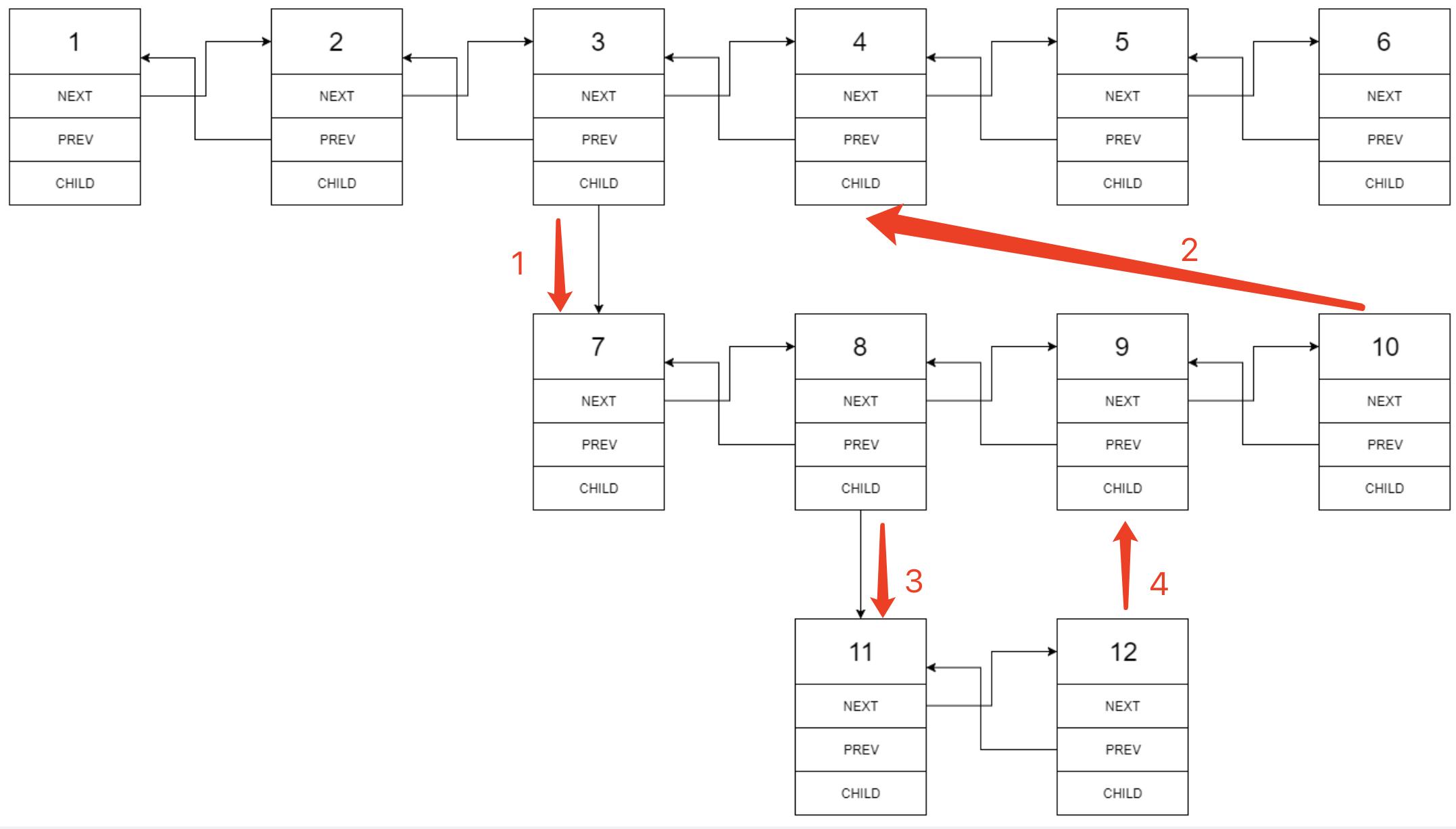
class Solution {
public Node flatten(Node head) {
Node dummy = new Node(0);
dummy.next = head;
for (; head != null; head = head.next) {
if (head.child != null) {
Node tmp = head.next;
Node child = head.child;
head.next = child;
child.prev = head;
head.child = null;
Node last = head;
while (last.next != null) last = last.next;
last.next = tmp;
if (tmp != null) tmp.prev = last;
}
}
return dummy.next;
}
}
以上是关于Leetcode——扁平化多级双向链表的主要内容,如果未能解决你的问题,请参考以下文章