11-flink-1.10.1- Flink window API
Posted 逃跑的沙丁鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了11-flink-1.10.1- Flink window API相关的知识,希望对你有一定的参考价值。
目录
1 window api 概念

- 一般真实的流都是无界的,怎样处理无界的流?
- 可以把无界的流进行切分,得到有限的数据集进行处理-也就是得到了有界的流进行处理。
- 窗口就是将无限流切割成有限流的一种方式,它会将有限的流分发到有限大小的桶里(bucket)进行处理
2 window api 类型
2.1 时间窗口(Time Window)
(1)滚动的时间窗口

- 将数据依据固定的时间窗口长度对数据进行切分
- 时间固定,窗口长度相同,没有重叠
.window(TumblingProcessingTimeWindows.of(Time.seconds(15)))//滚动窗口
.timeWindow(Time.seconds(15))//滚动窗口简写(2)滑动的时间窗口

- 滑动窗口是固定窗口更为广泛义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成
- 窗口长度有固定可以有重叠
- 使用场景,比如最近24小时内,最近1一个小时内的统计指标等等
.window(SlidingEventTimeWindows.of(Time.seconds(15),Time.seconds(10)))//滑动窗口
.timeWindow(Time.seconds(15),Time.seconds(10))//滑动窗口简写(3) 会话窗口
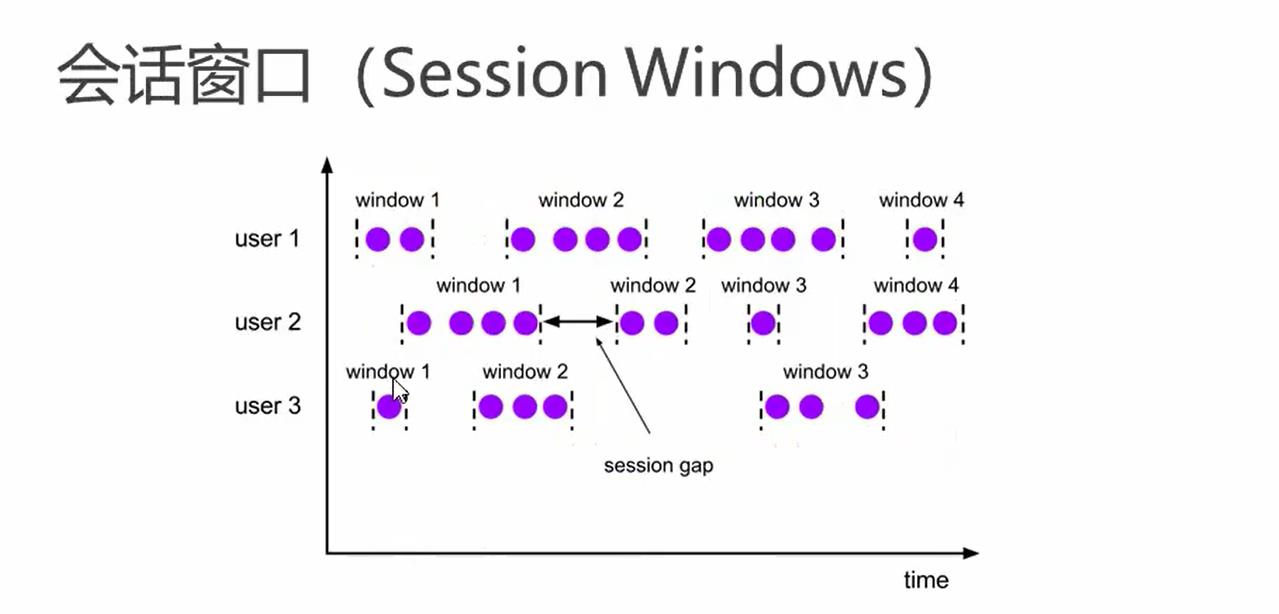
- 有一些列时间组合一个指定的时间长度的timeout间隙组成,也就是一段时间没有接收到数据就会生成新的窗口
- 特点,时间无对其
.window(EventTimeSessionWindows.withGap(Time.seconds(20)))//会话窗口2.2 计数窗口
滚动计数窗口
.countWindow(10)//计数滚动窗口滑动计数窗口
.countWindow(10,5)//计数滑动窗口3 窗口函数(window function)
window function 定义了对窗口中收集的数据做的计算操作
可分为两类:
① 增量聚合函数(incremental aggregation function)
每条数据到来就进行计算,保持一个简单的状态
ReduceFunction,Aggregation
② 全窗口函数(full window functions)
先把窗口所有数据收集起来,等到计算的时候会遍历所有数据
ProcessWindowFunction,WindowFunction


4 window api 结合代码

需求,求最近15秒内收到的数据里温度最小的温度,且最后一次温度采集的时间戳是什么?
① 读有界数据无法输出
package com.study.liucf.unbounded.window
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.{EventTimeSessionWindows, SlidingEventTimeWindows, TumblingEventTimeWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
/**
* @Author liucf
* @Date 2021/9/22
* 需求,求最近15秒内收到的数据里温度最小的温度,且最后一次温度采集的时间戳是什么?
*/
object LiucfWindowApi {
def main(args: Array[String]): Unit = {
//创建flink执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//读取数据
val inputStream: DataStream[String] = env.readTextFile("src\\\\main\\\\resources\\\\sensor.txt")
//转换数据类型 string 类型转换成LiucfSensorReding,求最小值
val ds = inputStream.map(r => {
val arr = r.split(",")
LiucfSensorReding(arr(0), arr(1).toLong, arr(2).toDouble)
}).map(d=>(d.id,d.temperature,d.timestamp))
.keyBy(_._1) // 按照传感器id分组
// .window(TumblingProcessingTimeWindows.of(Time.seconds(15)))//滚动窗口
// .window(SlidingEventTimeWindows.of(Time.seconds(15),Time.seconds(10)))//滑动窗口
// .window(EventTimeSessionWindows.withGap(Time.seconds(20)))//会话窗口
//
// .timeWindow(Time.seconds(15),Time.seconds(10))//滑动窗口简写
// .countWindow(10)//计数滚动窗口
// .countWindow(10,5)//计数滑动窗口
.timeWindow(Time.seconds(15))//滚动窗口简写
// .reduce((currentData,newData)=>{
// (currentData._1,currentData._2.min(newData._2),currentData._3.max(currentData._3))
// })
.reduce(new LiucfReduceFunction())
//输出到控制台
ds.print()
env.execute("flink window api:liucf window api test ")
}
}
/**
* 自定义reduceFunction处理
*/
class LiucfReduceFunction extends ReduceFunction[(String,Double,Long)]{
override def reduce(value1: (String, Double, Long), value2: (String, Double, Long)): (String, Double, Long) = {
(value1._1,value1._2.min(value2._2),value1._3.max(value2._3))
}
}

可见没有任何输出,这是因为窗口关闭需要等到15秒,而读取文件数据的有界流很快就完成了还没等到15秒就结束,所以没有输出
解决策略是换成无界流进行数据读入就可以了,我下面代码使用kafka来进行测试
为了看到效果我把窗口改成60秒快速往kafka里生成几条数据
package com.study.liucf.kafka
import java.util.Properties
import org.apache.kafka.clients.producer.{Callback, KafkaProducer, ProducerRecord, RecordMetadata}
import org.apache.kafka.common.serialization.StringSerializer
object SensorProduce2 {
def main(args: Array[String]): Unit = {
val kafkaProp = new Properties()
kafkaProp.put("bootstrap.servers", "192.168.109.151:9092")
kafkaProp.put("acks", "1")
kafkaProp.put("retries", "3")
//kafkaProp.put("batch.size", 16384)//16k
kafkaProp.put("key.serializer", classOf[StringSerializer].getName)
kafkaProp.put("value.serializer", classOf[StringSerializer].getName)
kafkaProp.put("topic","sensor_input_csv")
val producer = new KafkaProducer[String, String](kafkaProp)
val sensor = "sensor_1,1617505481,30.6"
send(sensor,producer)
producer.close()
}
def send(str:String,producer: KafkaProducer[String, String]): Unit ={
val record = new ProducerRe cord[String, String]("sensor_input_csv", str )
producer.send(record, new Callback {
override def onCompletion(metadata: RecordMetadata, exception: Exception): Unit = {
if (metadata != null) {
println("发送成功")
}
if (exception != null) {
println("消息发送失败")
}
}
})
}
}

可见可以达到预期的。
以上是关于11-flink-1.10.1- Flink window API的主要内容,如果未能解决你的问题,请参考以下文章
Flink SQL 窗口表值函数 Window TVF 实战
Flink学习笔记:搭建Flink on Yarn环境并运行Flink应用