C++初识C++
Posted 蓝乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++初识C++相关的知识,希望对你有一定的参考价值。
初识C++
学习完C语言后,便开始认识C++了。C++是在C语言的基础上发展出来的,因此C语言中的所有内容均可在C++上运行。同时C++也进行了许多优化,实现了很多C语言无法实现的功能,下面让我们来慢慢认识C++这一门编程语言。
一.C++关键字
首先是C++的关键字,C++总计63个关键字,其中包含C语言的32个关键字。对于C++的关键字,我们并不一一介绍,而是在之后的学习中来慢慢认识。
二.命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
1.命名空间定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。
首先,一个普通的命名空间,可以定义变量,函数以及类型
namespace nd//以nd为命名空间
{
int a = 10;//变量
int b = 20;
int Swap(int* px, int* py)//函数
{
int tmp = *px;
*px = *py;
*py = tmp;
}
struct gh//结构体类型
{
int age;
char name[20];
int weight;
};
}
其次,命名空间可以嵌套使用,也就是说一个命名空间中可以包含另外一个命名空间。
namespace ep
{
int a;
float b;
char c;
//命名空间可以嵌套使用
namespace zm
{
int arr[10];
struct Node
{
int* data;
struct Node* next;
};
}
}
再者,在一个项目中允许有多个名字相同的命名空间存在,编译器在最后会将所有名称相同的命名空间进行合并。
namespace ep
{
int a;
float b;
char c;
//命名空间可以嵌套使用
namespace zm
{
int arr[10];
struct Node
{
int* data;
struct Node* next;
};
}
}
需要注意的是一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限在这个命名空间中。
namespace nd//以nd为命名空间
{
int a = 10;//变量
int b = 20;
}
int main()
{
printf("%d\\n", a);//该语句编译出错,无法识别a
return 0;
}
2.命名空间的使用
认识了命名空间之后,要怎么使用命名空间的成员呢?
1.使用命名空间的名称以及作用域限定符::
int main()
{
printf("%d\\n", nd::a);
printf("%d\\n", ep::zm::arr[0]);
return 0;
}
2.使用using将命名空间的名称引入
using namespace nd;
int main()
{
int m = 1;
int n = 2;
Swap(&m, &n);
printf("m:%d n:%d\\n", m, n);
printf("%d\\n", a);
return 0;
}
对于这种使用方法,有一点需要注意的是由于命名空间原本的作用就是为了避免命名冲突或名字污染,而如果直接将命名空间展开的话,就会直接让命名空间的成员暴露出来,从而可能会造成命名冲突和名字污染,因此,相对于直接将命名空间的名称引入,可以将命名空间中常用的成员引入。
3.使用using将命名空间中的成员引入
using nd::Add;
int main()
{
int a = 10;
int b = 20;
int c = Add(a, b);
printf("%d\\n", c);
return 0;
}
三.C++的输入输出
最初认识C语言时是从hello world开始的,那么C++的hello world又是怎么样的呢?
#include <iostream>
using std::cin;
using std::cout;
using std::endl;
int main()
{
cout << "hello world" << endl;
return 0;
}

这里需要说明的是:
首先,使用cout标准输出(即控制台)和cin标准输入(即键盘)时,需要包含<iostream>头文件以及std标准命名空间。
需要注意的是:早期的C++由于没有命名空间的概念,因此标准库的所有功能都是在全局作用域下实现,声明在.h为后缀的头文件中。使用时只需包含对应的头文件即可,而随着C++的逐步发展,原来标准库的功能都std这个命名空间下,同时为了与C语言的头文件区分,也为了正确使用命名空间,规定了C++的头文件不带.h。旧编译器(vc 6.0)中还支持<iostream.h>格式,后续编译器已不支持,因此推荐使用<iostream>+std的方式。
其次,C++中的输入输出是不需要数据格式的控制,比如整型-- “%d” ,浮点型–”%f“。
#include <iostream>
using std::cin;
using std::cout;
using std::endl;
int main()
{
int n = 0;
cin >> n;
double* a = (double*)malloc(sizeof(double) * n);
if (a == NULL)
{
printf("malloc fail");
exit(-1);
}
for (int i = 0; i < n; i++)
{
cin >> a[i];
}
for (int i = 0; i < n; i++)
{
cout << a[i] << " ";
}
cout << endl;
free(a);
a = NULL;
}

不需要控制数据格式,这是比较方便的一点。但是也可能会遇上比较麻烦的情况,比如要输出一个结构体的信息时,C++的输出就显得有些冗杂了:
namespace ns
{
struct Stu
{
char name[20];
int age;
char id[10];
};
}
using namespace ns;
int main()
{
struct Stu s1 = { "李华",18,"20200225" };
cout << "姓名:" << s1.name << " " << "年龄:" << s1.age << " " << "学号:" << s1.id << endl;
printf("姓名:%s 年龄:%d 学号:%s\\n", s1.name, s1.age, s1.id);
return 0;
}

因此,在实际使用过程中,没必要纠结那种输入输出方式,怎么方便就怎么用。
四.缺省参数
1.缺省参数的概念
缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的实参。
int Add(int a, int b = 10)
{
return a + b;
}
int main()
{
cout << Add(10, 20) << endl;//传参时,使用指定的实参
cout << Add(10) << endl;//没有传参时,使用默认的参数值
return 0;
}

2.缺省参数的分类
全缺省参数
全缺省参数即函数的所有参数都设置了默认的参数。
void Test1(int a = 10, int b = 20, int c = 30)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
int main()
{
Test1();
Test1(1);
Test1(1, 2);
Test1(1, 2, 3);
return 0;
}
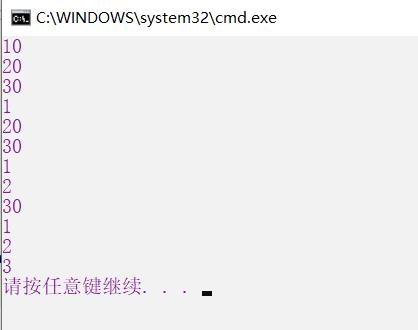
需要注意的是,在传参时只能从左往右按顺序传,而不能出现类似Test(,10,);这样的语句,编译器是无法识别的。
半缺省参数
半缺省参数即函数的部分参数设置了默认值。
void Test2(int a, int b = 20, int c = 30)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
int main()
{
Test2(1);
Test2(1, 2);
Test2(1, 2, 3);
return 0;
}
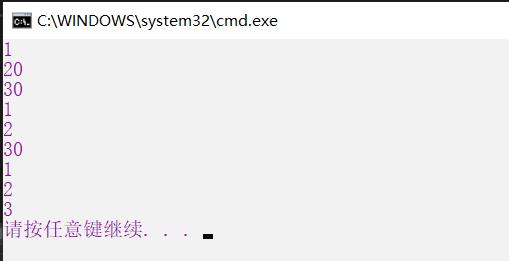
注:(1)半缺省参数中的默认值必须从右往左设置,而不能出现类似Test(int a = 10, int b; int c);这样的语句,因为这样设置会产生歧义,编译器无法识别。
(2)缺省参数不能在函数的声明和定义中同时出现,这是规定的,如果声明和定义的参数默认值不相同编译器会无法识别,为了防止这种情况出现,因此缺省参数不能同时出现在函数的声明和定义中。
//fun.h
int Add(int a = 10,int b = 20);
//fun.c
int Add(int a= 10, int b = 20);//错误,缺省参数不能同时出现在声明和定义中
(3)缺省值必须是常量或者全局变量。
(4)缺省参数是C语言不支持的。
五.函数重载
1.函数重载的概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 顺序)必须不同,常用来处理实现功能类似数据类型不同的问题。
//函数名相同,参数类型不同
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void Swap(double* px, double* py)
{
double tmp = *px;
*px = *py;
*py = tmp;
}
int main()
{
int a = 1;
int b = 2;
double c = 3.3;
double d = 4.4;
Swap(&a, &b);
Swap(&c, &d);
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
cout << "d = " << d << endl;
return 0;
}
需要注意的是,参数类型相同而返回值不同的同名函数不属于函数重载,而且这种情况是编译不过去的。

2.名字修饰(Name Mangling)
首先我们来看一个问题:C++能支持函数重载,那么C语言能否支持函数重载呢?
答案是否定的,原因是什么呢,接下来就让我们来一起看看。
首先,在C/C++中,程序运行需要经过以下几个阶段:预处理,编译,汇编,链接。

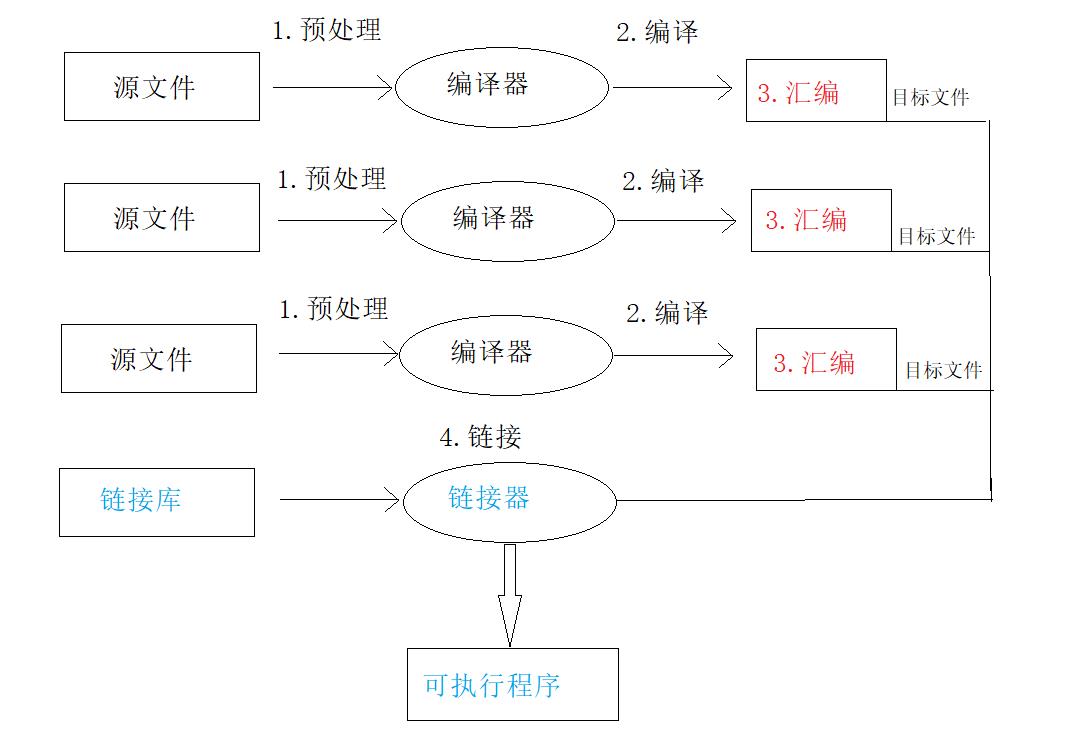
实际上我们的项目都是由多个源文件和多个头文件构成的,根据C/C++的编译链接等阶段,当test.c调用了f.c中定义的Add函数时,在编译后链接前的这个阶段,test.o这个目标文件中没有Add这个函数的地址,因为Add是在f.c中定义的,因此Add的地址是在f.o中的,那么这时应该怎么办呢?
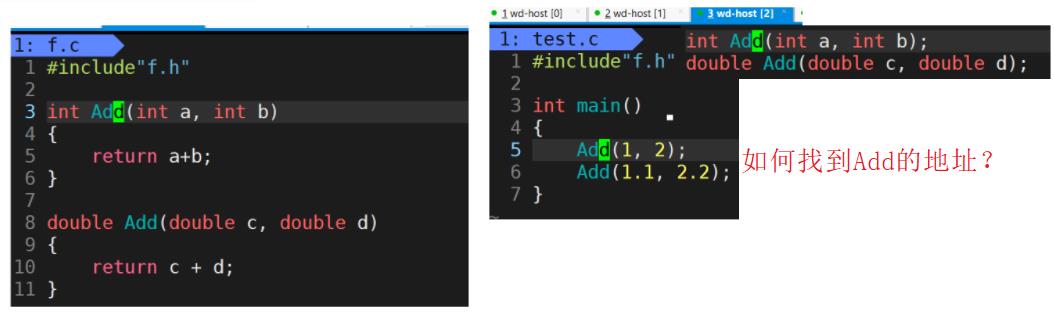
这个时候就需要让链接发挥作用了,链接器看到test.o调用Add函数,但是却没有Add的地址,就会到f.o的符号表中去找Add的地址,然后链接到一起。
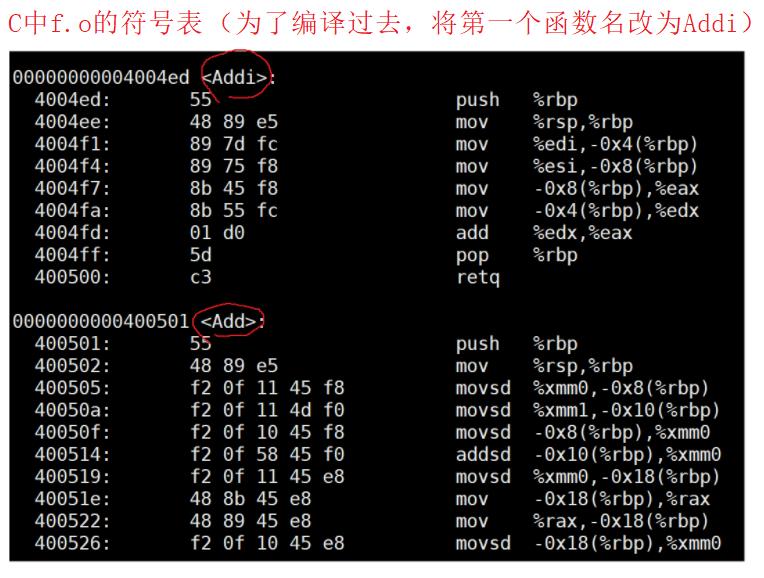
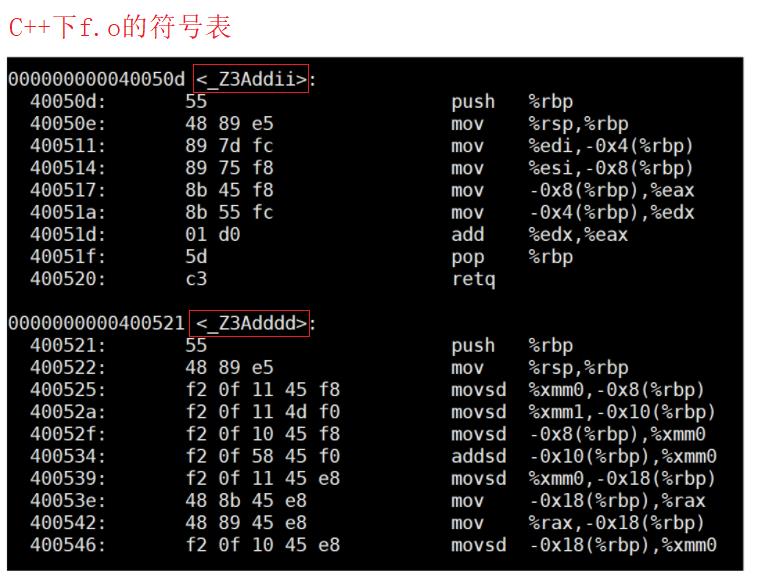
因为每个编译器都有自己的函数名修饰规则,因此在链接时,连接器会据此按照不同的函数名去寻找函数地址。
由于VS的修饰规则过于复杂,这里我们以Linux下的gcc编译器为例。
可以看出C语言编译器编译后,函数名字的修饰并没有发生改变;而C++编译器编译后函数名字的修饰发生改变,并且编译器将函数参数类型信息添加到修改后的名字中。这里有一套修饰规则,即_Z + 函数名的字母个数 + 函数名 + 每个参数类型的首字母。比如int Add(int a,int b);这个函数名最终修饰为_Z3Addii。
综上所述,由于同名函数无法区分,因此C语言是无法支持函数重载的,而C++通过函数的修饰规则来区分,只要参数不同,修饰出来的名字就不一样,因此支持函数重载。此外,我们也可以理解为什么函数重载要求的是参数不同而跟返回值没有关系。
以上是关于C++初识C++的主要内容,如果未能解决你的问题,请参考以下文章