WebDriver 识别反爬虫的原理和破解方法~
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了WebDriver 识别反爬虫的原理和破解方法~相关的知识,希望对你有一定的参考价值。

作者|志斌
来源|python笔记
有时候我们在爬取动态网页的时候,会借助渲染工具来进行爬取,这个“借助”实际上就是通过使用相应的浏览器驱动(即WebDriver)向浏览器发出命令。
但是有时候使用浏览器驱动来爬取网页时,会遇到这种情况
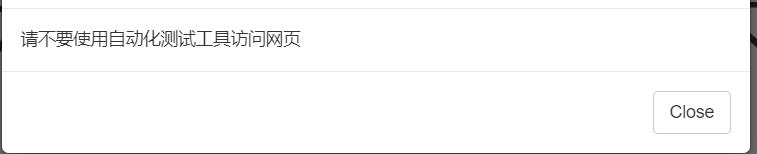
这时,就代表我们的爬虫程序被反爬了。
今天志斌就来给大家分享一下,如何破解这类特征识别反爬虫之WebDriver识别反爬虫。
01
原理
开发者在开发网页的时候,通过javascript设置一个事件,然后让这个事件来调用Navigator对象的webdriver属性,从而来判断客户端是否使用WebDriver驱动浏览器。
如果检测到客户端有webdriver属性,则会返回True,此时反爬虫就会认为这是一个爬虫程序,从而进行限制;如果没有检测到,则会返回False或者Undefined,此时反爬虫不会运行。
检测代码如下:
webdriver = window.navigator.webdriver;
if(webdriver){
console.log('请不要使用自动化测试工具访问网页')
}
else{
console.log('正常浏览器')
}02
破解
通过学习上面的WebDriver识别反爬虫原理,我们知道反爬虫机制是根据webdriver属性的返回值来判断是否是爬虫程序访问的。
也就是说,当我们用浏览器驱动来爬取网页时,只要我们能够将它的特征给隐藏,让Navigator对象检测不到浏览器驱动,从而使得webdriver属性返回的值为False或者Undefined,此时就破解WebDriver识别反爬虫了。
上面已经分析出来解决方案了,那我们现在就可以书写代码来实现这个方案了,隐藏浏览器驱动特征的代码如下:
driver = webdriver.Chrome()
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
option.add_argument(
'user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
option.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(options=option)
with open('stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': js
})让我们来看看效果:

此时,文章内容就被正确显示出来了,没有再出现被反爬冲限制。
03
小结
1. 本文详细介绍了如何破解特征识别反爬虫之WebDriver识别反爬虫。
2. 现在很多网站对Selenium套件有着明显的限制,所以破解WebDriver识别反爬虫是一个爬虫工程师必备的技能之一。
3. 本文仅供学习参考,不做它用。


往
期
回
顾
资讯
技术
资讯
资讯

分享

点收藏

点点赞

点在看
以上是关于WebDriver 识别反爬虫的原理和破解方法~的主要内容,如果未能解决你的问题,请参考以下文章