浙大赵俊博:重新审视模型 vs 数据这个问题!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浙大赵俊博:重新审视模型 vs 数据这个问题!相关的知识,希望对你有一定的参考价值。
↑↑↑关注后"星标"Datawhale
每日干货 & 每月组队学习,不错过
Datawhale干货
作者:赵俊博,浙江大学博导,整理:段秋阳
1. 为啥有必要重新审视?
原因一:数据作为AI的能源燃料,被严重忽视。尤其在学术研究中体现得尤为明显。
AI在当下是一个非常火热的研究领域,每年有大量的研究论文涌现,但整体上比起研究探索,这更像是一个竞赛。在一个相同的公开的标准数据集或评测任务上,全世界的研究者乐此不疲地开发(说尝试更恰当些)新的模型结构,努力把模型层数做的越来越深,力图刷榜达到SOTA效果。在这样一个竞赛式的研究体系下,自然没有人去关心数据本身(因为数据已经是固定的了,这是一道命题作文)。
原因二:数据是一种稀缺资源,是昂贵的。
事实上,在许多工业场景下,特别是以交叉学科为背景的(如生物信息、医学影像、制药、材料工业),真实的数据需要实验人员耗费大量的心血才能得到。如果是需要标签的数据,则又增加了大量的标注成本。
原因三:重新审视,是为了不偏离航向。
学术界和工业界都要进行研究,做研究是为了解决实际问题,可是现在我们是在研究解决问题的方法吗?我们发明的模型能够处理实际场景中面临的问题吗?
2. 灵魂拷问:你的模型会被使用吗?
这个问题非常具有攻击性,我们还可以让他更激烈一些:你这奇怪玩意儿真的能用?
你可能会说:能啊,好用的很!我们在这个公开评测数据集上目前取得了最棒的效果,这太令人振奋了!
“帅啊兄弟!那换个数据集呢?我这有好几个数据集”
“……”

有人可能会说,那这就是个泛化性能的问题啊,要想泛化性能好,当然是数据量越多越好,最好还是不同领域不同分布,让模型学到更多的信息。
那这个话不就说回来了吗,能找到好几个数据集,为啥偏在一个数据集上训练,你也知道这样泛化性能大概率不会好,那我拿来怎么用啊?就算侥幸能用,我当初多加点高质量数据进去,难道不比这方便?人都快渴死了,从大海里就可以得到蒸馏水,为啥我们非要在陆地上抢水?
玩笑归玩笑,我们还是想挖掘这个问题出来。做研究当然需要很多假设条件,甚至是从最理想的情况下出发,不断对理论和模型进行修正。但是在AI这个更新迭代速度极快,应用价值极高的领域,这种在一个数据集上刷榜的研究模式是否有点过多地偏离了实际?我们经常喜欢用银行的业务场景举例子,几大行现在还离不开逻辑回归呢,这都多少年的老古董了,你可能会吐槽这些行业或者公司技术垃圾之类的。那每年顶会上那么多的新模型,都去给谁用?全球的互联网、高科技公司加一块也用不过来啊?
我们重新审视模型 vs 数据这个问题,并不是想说这二者是对立的。在一个AI项目的实施与落地中,模型、数据、部署都是手段而非目的,而很多算法落地困难,就是因为数据短板的木桶效应造成的。模型vs数据,从研究上来说,是需要人们关注的程度和研究的方向,从工业上来说,是资源分配和投资回报,以及如何满足工业系统最核心的需求:稳定性。模型稳定最重要!不需要过于fancy,差不多得了!
那么需要用到的数据,会存在哪些问题呢?
根本没有数据!但是我有经费,嘿嘿,那怎么搞呢?我又不想花太多,嘿嘿。。。这可能涉及到一些数据选择、学习范式方面的研究,比如主动学习等。
我数据多的是,但是他们标签体系不一样啊!这可能需要一些数据集融合的方法。
我钱多的是,我请了一堆人标数据,但是他们标的太烂了,全是噪声!这需要noisy-label数据方面的研究。
实际场景中我没有测试集啊,我怎么检验效果!这时候是一个验证集的最佳选择问题。
我怎么知道这数据好还是坏!这是数据点质量评估问题。
数据方面的研究还有许许多多的问题,我们不能再视若无睹了!
3. 解决数据侧问题的思路
我们之前提到过,数据是一种昂贵的稀缺资源,特别是领域性、专业性强的,交叉学科的数据,还要带高质量标签的就更稀缺了。对于稀缺资源,必须要合理利用,善加使用,“把数据用在刀刃上”。
1. 半监督学习(Semi-Supervised Learning)
举个实际场景的例子,医学影像这一交叉学科,可以把传统CV的很多数据迁移过来用,但是他们缺少医学意义的标签,形成了一种“数据多,标签少”的现象。这种场景就比较适合用半监督学习来利用未标注数据。
2. 数据增强(Data Augmentation)
这是一个被讨论地较多,研究也较为深入的领域。仅图像数据就能各种切分旋转玩出一堆花来,近年来也有许多基于生成的方法,特别是对抗生成,都被广泛应用于数据增强。
3. 主动学习(Active Learning)
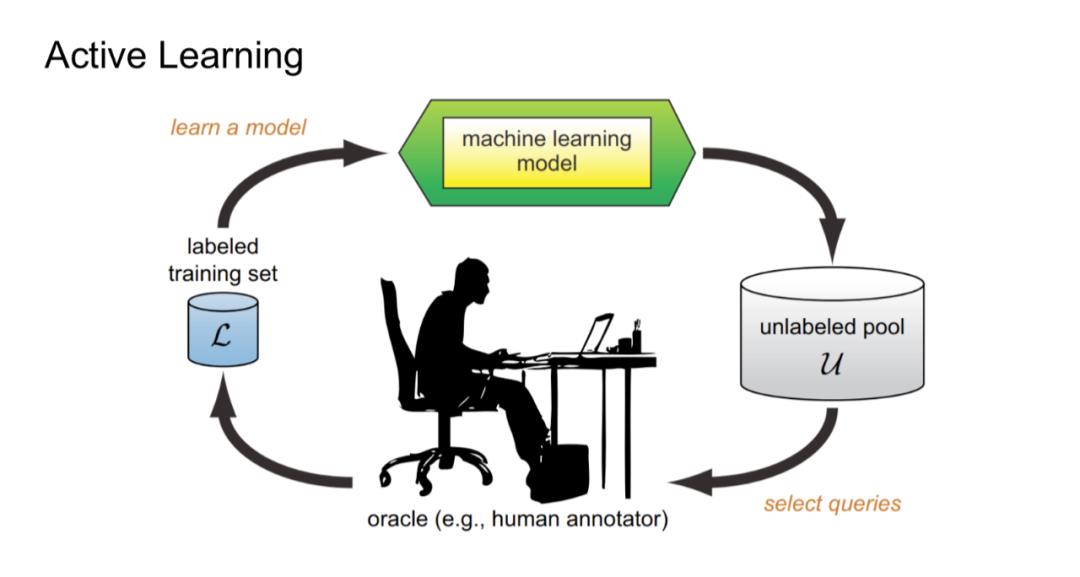 这是一种我们较为推崇的方法,主动学习的核心理念是,模型自己去挑选下一批要学习的数据,这样做的好处是可以实现模型和数据的同步迭代,即模型在不断训练的同时,也从全量数据中挑选出了一批最为“有用”的数据。很多人没有接触过这一学习范式,可以举个生活中的例子:这就像一个爱提问题的学生,他完全清楚自己学的不好的地方在哪里,主动向老师请求这些方面的指导,按照自己的需求去学习。
这是一种我们较为推崇的方法,主动学习的核心理念是,模型自己去挑选下一批要学习的数据,这样做的好处是可以实现模型和数据的同步迭代,即模型在不断训练的同时,也从全量数据中挑选出了一批最为“有用”的数据。很多人没有接触过这一学习范式,可以举个生活中的例子:这就像一个爱提问题的学生,他完全清楚自己学的不好的地方在哪里,主动向老师请求这些方面的指导,按照自己的需求去学习。
使用主动学习,就可以分阶段地去标注训练数据,而不是一次性地投入大量人力财力成本去大规模标注。事实上,很多情况下不需要去使用到全部的标注数据,就可以得到和全量数据同样的效果。比如core-set这种采样一部分代表性样本,作为全部数据集的替代的方法,或是条件数据概括,从大型数据集中提取和给定查询集相关,能够代表全量数据集的子集。
4.总结
AI研究是一个一体多面的工作,如果我们想要实实在在地推进AI项目的落地,做出真正有用的东西,那一定要关注数据方面的研究。尽管我们常说现在是“大数据时代”,但是在工业实际场景和一些交叉领域中,高质量的带标签数据依然是稀缺的,如何能够利用好这些数据,将成为AI系统能否赋能各行各业的重要因素。而Data-Centric的研究,也可能是连接起来学术界、工业界的一个重要桥梁。
本文整理自浙江大学的赵俊博课题组和纽约大学的博士生谭济民带来的线上分享,阅读原文有完整分享视频。
作者
赵俊博,浙江大学百人计划研究员、博士生导师。
谭济民,纽约大学博士生,主攻生物医药与人工智能交叉前沿研究。
杨嘉南,浙江大学计算机博士生,人工智能方向。
整理
段秋阳,浙江大学计算机硕士。

点【阅读原文】观看完整视频
以上是关于浙大赵俊博:重新审视模型 vs 数据这个问题!的主要内容,如果未能解决你的问题,请参考以下文章