超大规模时空数据的分布式存储与应用
Posted 爱是与世界平行
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超大规模时空数据的分布式存储与应用相关的知识,希望对你有一定的参考价值。
超大规模时空数据的分布式存储与应用
来源微信公众号:浪尖聊大数据
**导读:**据国际数据公司(IDC)统计,全球每18个月新增数据量为有史以来数据总和。预计到2025年,全球数据总量将达175ZB,其中 80%的数据与空间位置相关,时空数据规模增加非常迅速。
与此同时,时空数据剧增给传统GIS带来了很大挑战。传统GIS常用的数据管理、空间分析、地图可视化等方法上都存在一些不足之处,其性能也无法满足愈发增加的时空数据量的要求。此外,传统GIS也基本无法管理流式空间大数据。
因此,为了更好应对时空数据量剧增所带来的难题,我们需要一种新型的数据存储方法,能够针对超大规模的时空数据,提供存量、流式数据管理的能力,同时保证上层空间数据分析、地图可视化等应用性能,并以简单易用的方式提供时空数据给GIS从业人员使用。本文将和大家分享下超图对于超大规模时空数据的分布式存储与应用方案。主要内容包括:① 面向时空数据的存储与应用;② 面向分布式计算的存储与应用;③ 面向地图渲染的存储与应用;④ 分布式地理处理建模。
01 面向时空数据的存储与应用
1. 时空数据的发展历程
首先介绍时空数据发展历程。
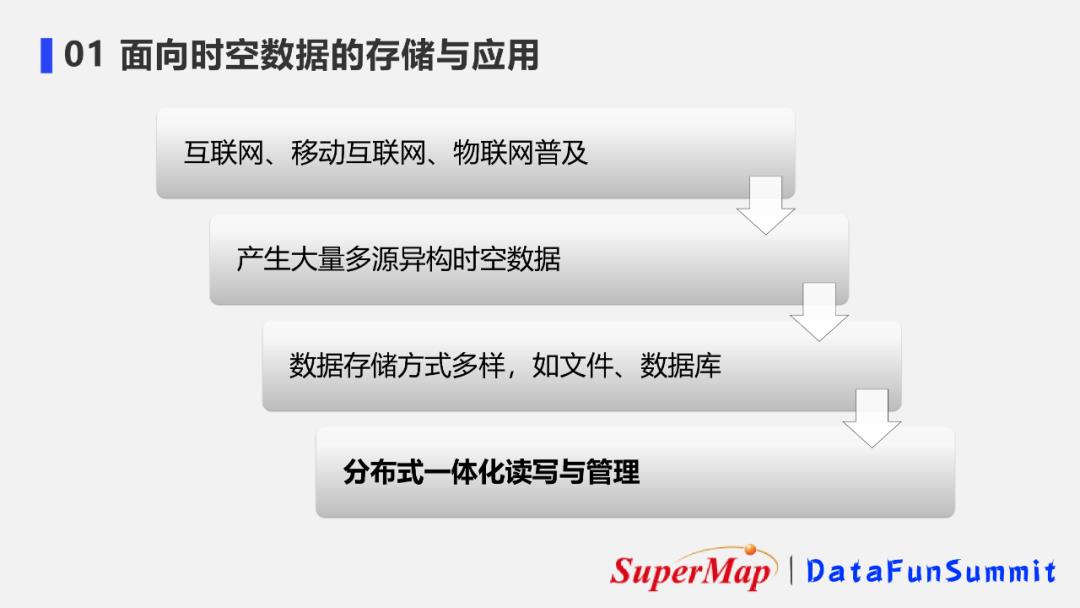
我们知道超大规模的时空数据因飞速发展的互联网、移动互联网、物联网普及而产生。这些数据往往具有多源异构的特性,因其结构不同,特性也不同,往往还以不同的数据存储类型存储,如文件型、数据库等形式。
因此对于这样的时空大数据,需要一种一体化的分布式访问方式将它们统一接入到GIS平台中,方便后续的分析和应用。
2. 常见的异构时空数据类型

常见异构时空数据包括但不限于以下几种:
- 以点、线、面数据为代表的矢量数据,通常采用字段属性或几何属性的方式存储;
- 栅格数据,通常以像素形式,较规律的网格化形式进行存储。
它们是都具有很大差异的数据结构,因此在数据量变得庞大的时候,为保证这些数据的分析、管理性能,我们需要根据其不同特性,存放在不同的分布式数据库中。
3. 各具特色的分布式数据存储

常见的分布式数据库有以下几种:
- 分布式关系型数据库,具有较完整的SQL查询能力,因此适合查询大量的矢量数据。
- MongoDB是一种键值数据库,比较适合大规模的栅格切片。
- ES数据库适合存放大规模的点数据。
- 以HDFS为代表的分布式文件系统,适合存储CVS等格式的文件型数据。
- 以HBase为代表的非关系型数据库,有非常高的查询性能,适合存储需要查询显示的海量空间大数据。
4. 分布式一体化时空数据访问
① 优势1-通用数据读写API
对以上几种数据存储方式,超图提供了一套通用的数据读写接口,能够对这些多源数据进行读取和访问,包括:HDFS时空文件引擎接口;分布式对象存储引擎接口;关系型空间数据库引擎接口;NoSQL数据库引擎接口。
② 优势2-参数标识数据源类型
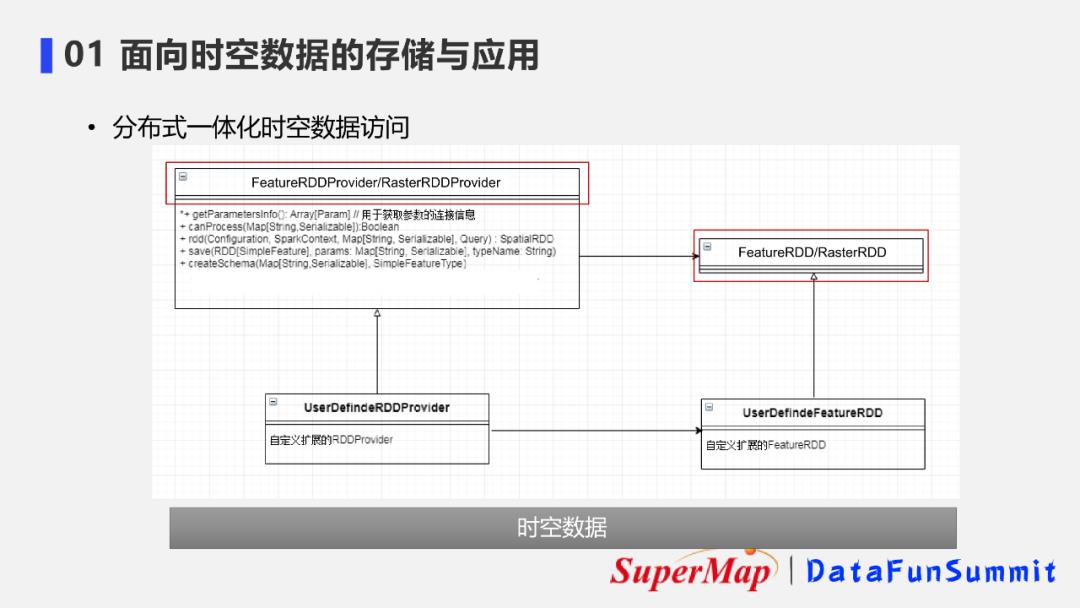
使用时只需以参数的方式,即Parameter,输入传入的数据源连接信息,就能标识出不同的数据源类型。这样做的好处是能确保在应用层调用统一的数据访问接口,从而提升代码的复用性。
③ 优势3-按需查询多源数据
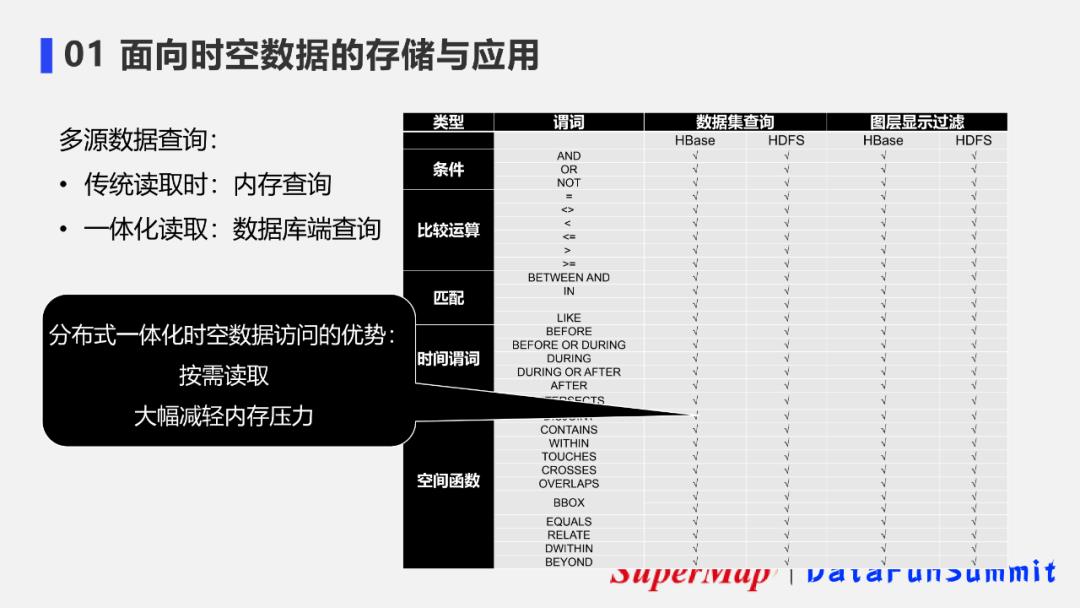
此外另一个优势是,如在传统的方法中,对不同数据源进行差异化访问时,在需要数据统一查询时,往往需要先将多源数据读取到内存中再进行查询。典型如sparkSQL的能力,这样在数据量较大时很容易造成内存溢出的危险。但如果使用一体化的读取方式,就能在读取的同时设置查询条件。像在刚才的函数中,输入query参数,就可以在数据库端直接进行查询,实现数据的按需读取,从而大幅减轻内存压力。
02 面向空间计算的存储与应用
1. 空间数据索引
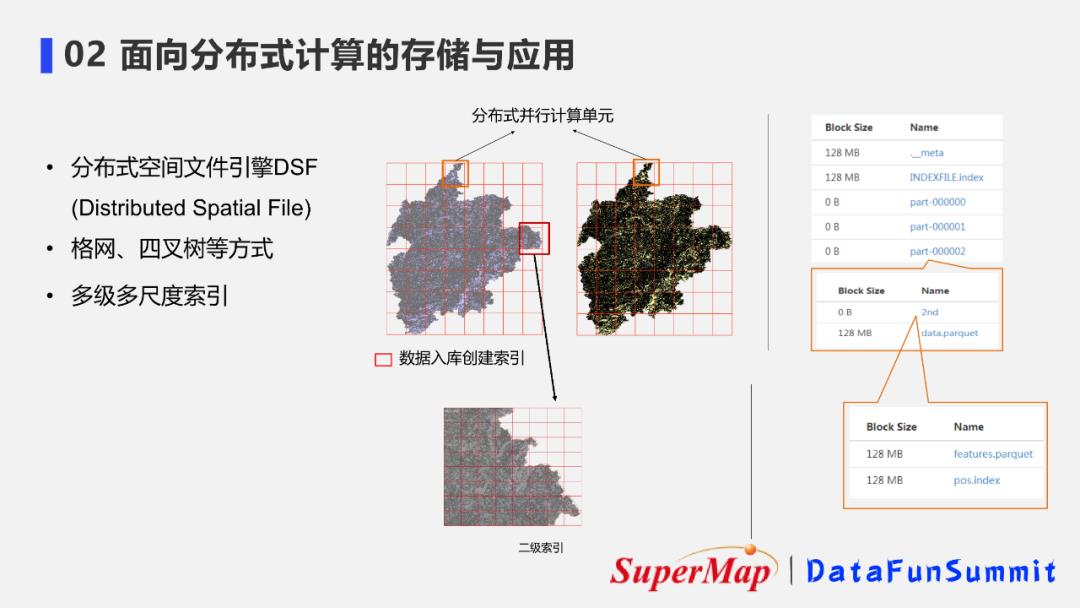
我们知道在磁盘上查询数据时,为避免每查询一个数据就要扫描整个磁盘,我们必须在磁盘上建立索引来提高数据查询的效率。传统数据库中,往往建立字段索引对特定键值进行快速访问,但地理空间数据具有更高维度,传统的字段索引并不能满足空间数据的索引要求,因此需要一种空间索引来满足空间数据的查询要求。
超图推出了一种分布式空间文件引擎,也叫做DSF。这种数据存储方式可以对地理空间数据进行空间索引。通过格网、四叉树等空间索引方式实现对空间单元的划分。划分后的空间单元还可以进行多级多尺度的索引,如对每一个空间单元进一步构建二级索引,以提升精细数据的查询效率。
2. 基于DSF的分布式计算步骤
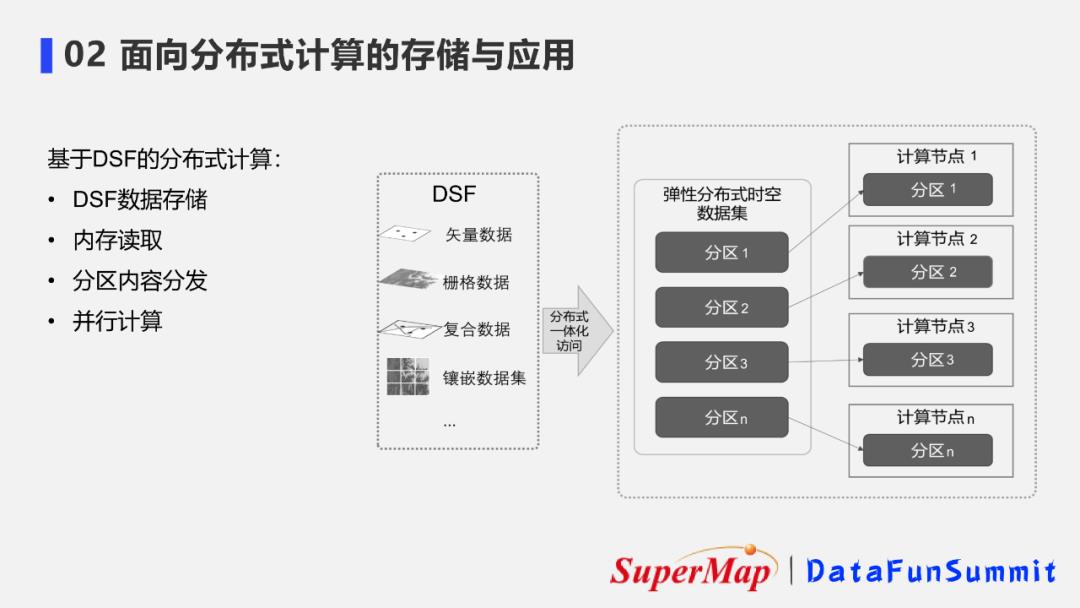
基于DSF时空数据存储方式,在计算时首先会通过一体化数据访问接口,将数据读取为弹性分布式时空数据集,读取到内存中,然后再将各个分区发到分布式计算集群各个计算节点实现并行计算,从而大幅提升计算性能。
3. 分布式空间文件引擎的应用范围
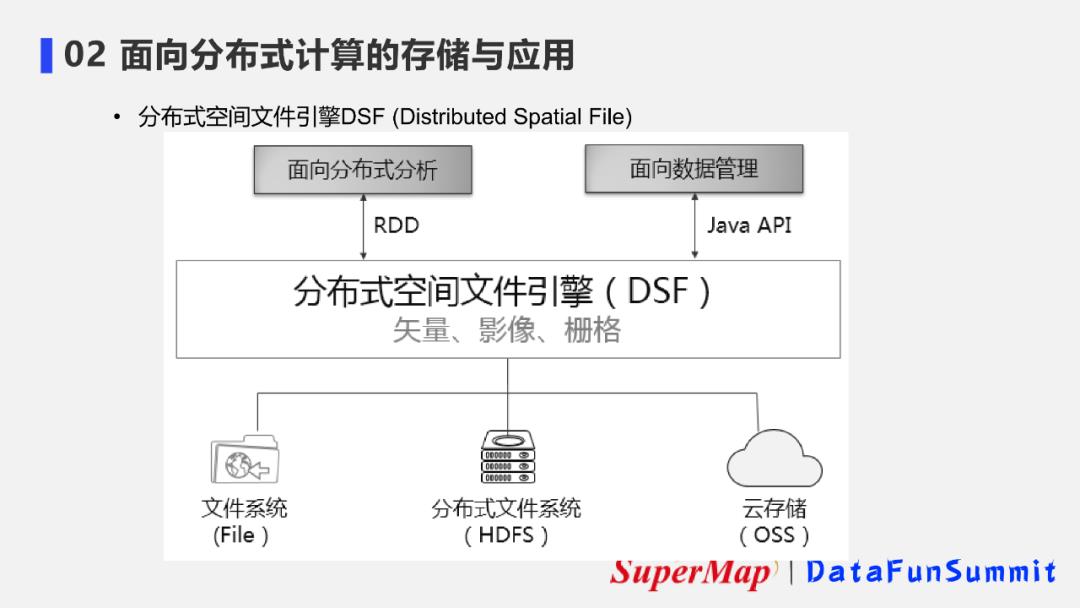
目前,DSF能够完全支持分布式与文件式数据管理方式,也能支持云存储,能够承载矢量、栅格等不同数据类型,以统一的数据结构向上层提供分布式分析与分布式数据管理能力。
4. 基于DSF的应用案例1-农经数据建库
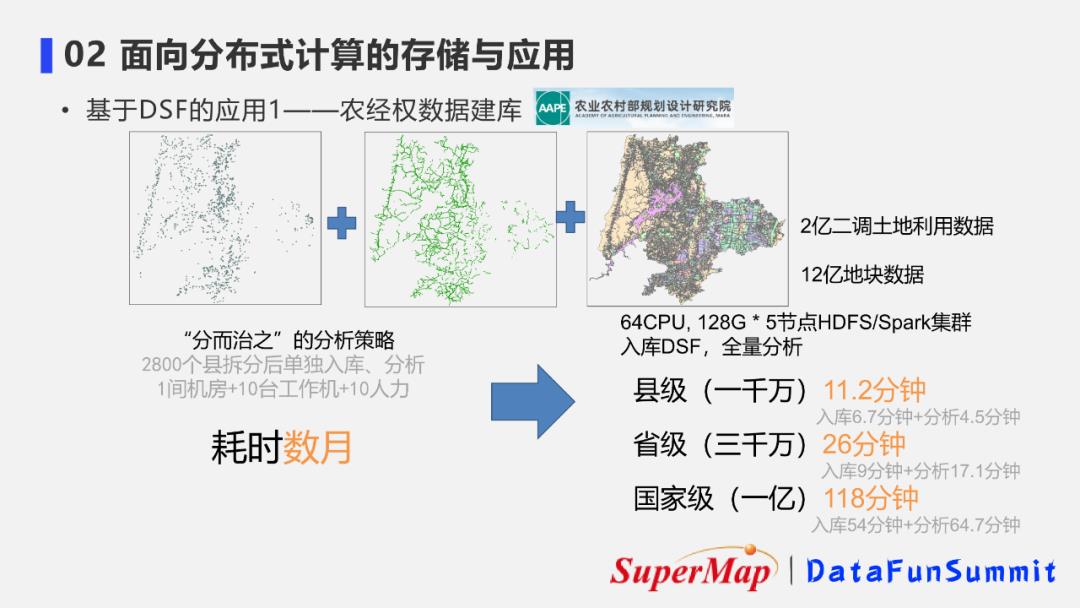
DSF的应用之一是与农业农村部规划设计研究院一起完成的农经权数据建库。
它们具有非常大量且数据结构复杂的土地利用数据和地块期权数据,包括点线面数据和复合矢量数据。
传统方法是采用“分而治之”的策略来数据入库和分析的,也就是说要对全国2800个县拆分后单独入库、分析。这样的工作流程耗费的计算资源、人力、时间都非常庞大。
但尝试使用分布式的DSF和分布式计算后发现,各个级别的数据入库和计算性能都大大提升:
- 县级的千万级别的数据可以在10min左右完成入库和叠加分析;
- 省级三千万级别的数据可以在30min左右完成入库和分析;
- 国家级亿级别的数据可以在2h左右完成入库和分析。
5. 基于DSF的应用案例2-四川省土地确权业务
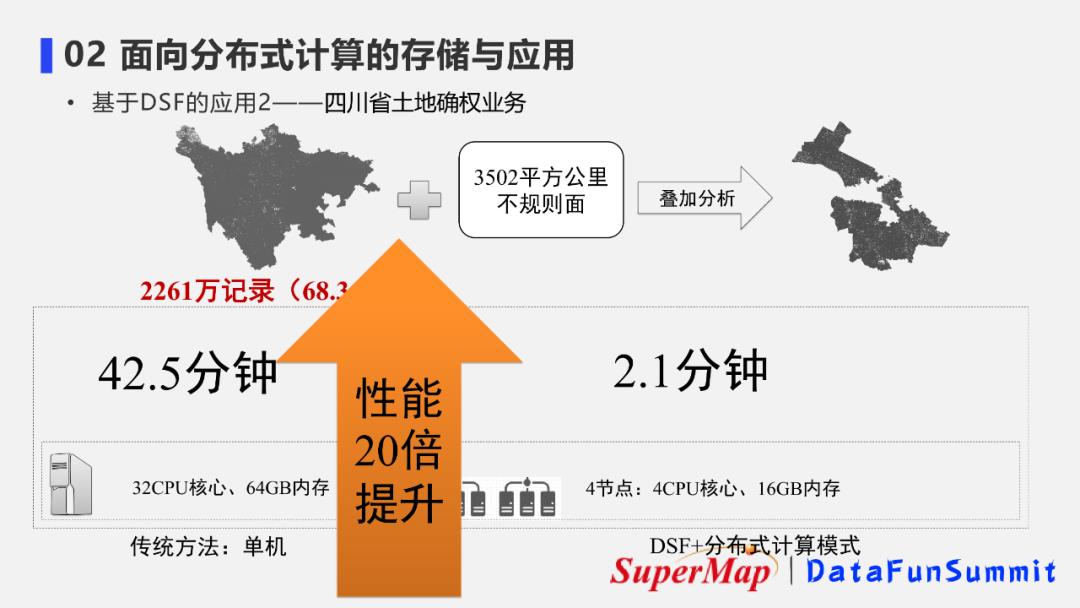
四川省基础地理信息中心土地确权业务分析需要对四川省全省2000多万条记录进行叠加面的分析。
传统工作方式是采用高性能单机服务器来完成,虽然机器性能非常好,但完成一次叠加分析也需要40多分钟。
尝试使用一个4节点的分布式集群去进行DSF存储和分布式计算之后发现,虽然每一台服务器的使用资源并不高,但是耗时降低至2min左右,因此性能会有20倍的提升。
6. 基于DSF的应用案例3-全球耕地面积统计
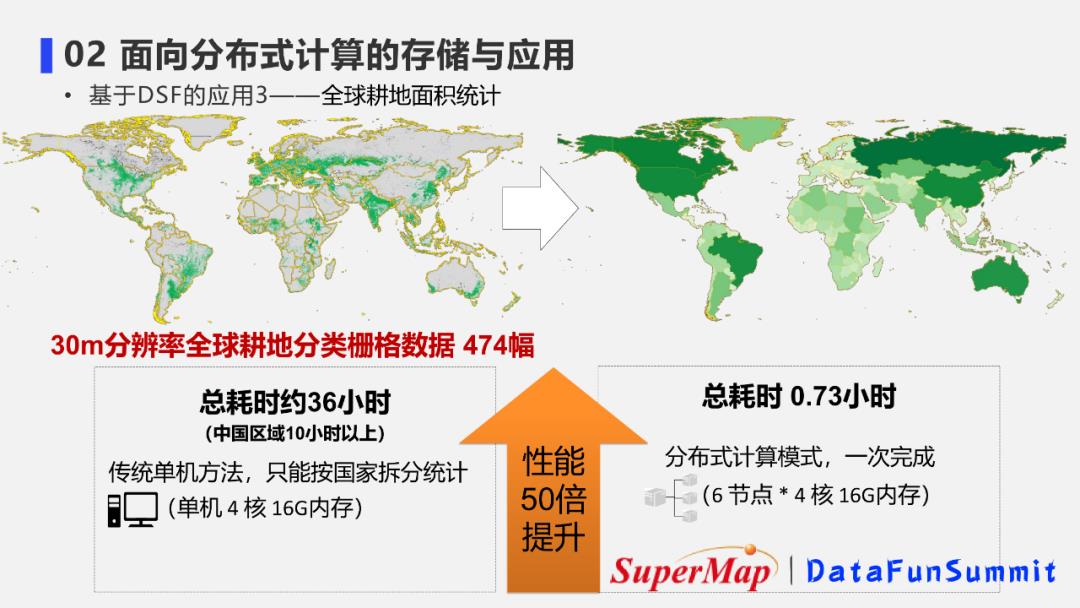
DSF的第三个应用是农业规划设计研究院的一个研究型项目:全球耕地面积各地区统计。
采用30m分辨率的耕地分类栅格数据,数据超过400幅。
如果采用传统单机方法,按国家拆分后计算,那么面积比较大的国家,比如中国区域,就需要计算10小时以上。
因此这使用传统方法并没有完成对全球的计算。
但当尝试使用一个6节点的分布式计算集群,并使用DSF的存储方式进行栅格存储,进行耕地面积统计时,发现一次全球计算只需40min就可以完成。性能提升了50倍,得到了用户的极大肯定。
03 面向地图渲染的存储与应用
以上讨论了超大规模时空数据针对空间分析可以有那些优化,接下来看看GIS行业中另一个需求,即地图可视化,能进行哪些分布式方面的改造。
1. 地图服务的要求
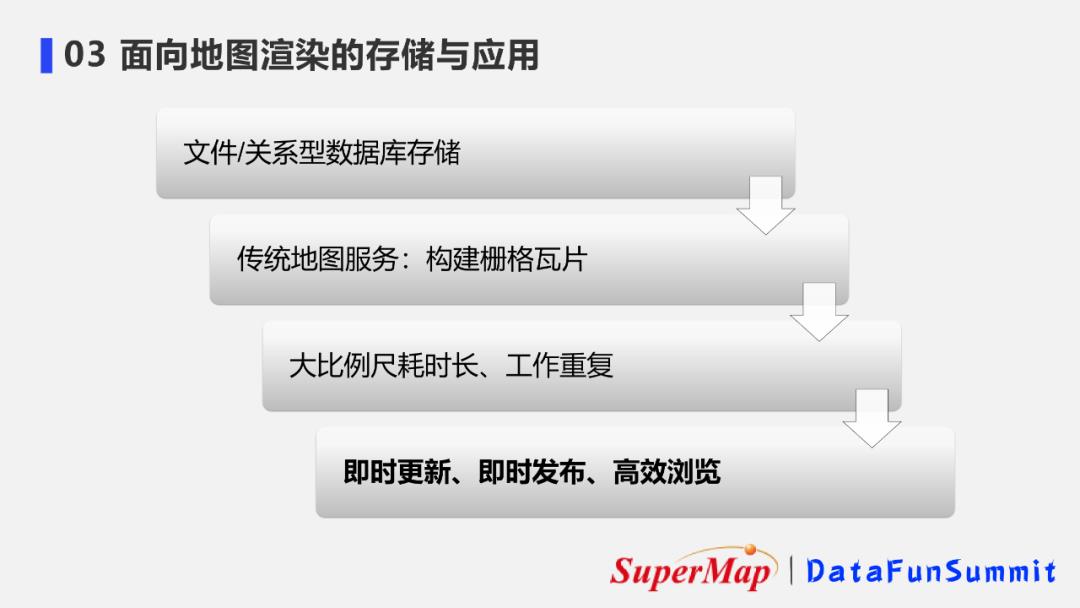
传统的时空数据大多以文件或关系型数据库来进行存储。
对于这些数据,我们进行地图发布的时候,通常采用构建栅格瓦片的形式来进行。
但栅格瓦片有一些弊端,如在数据量非常大时,大比例尺的栅格瓦片构建耗时非常长,地图的分格一旦发生改变,栅格瓦片就要重复构建,因此这个工作是一个重复性的工作。
因此对于大数据量的时空数据来说,我们就需要一个新型的分布式技术来实现地图的即时更新、即时发布、高效浏览的需求。
2. 超图-高性能分布式动态渲染技术体系
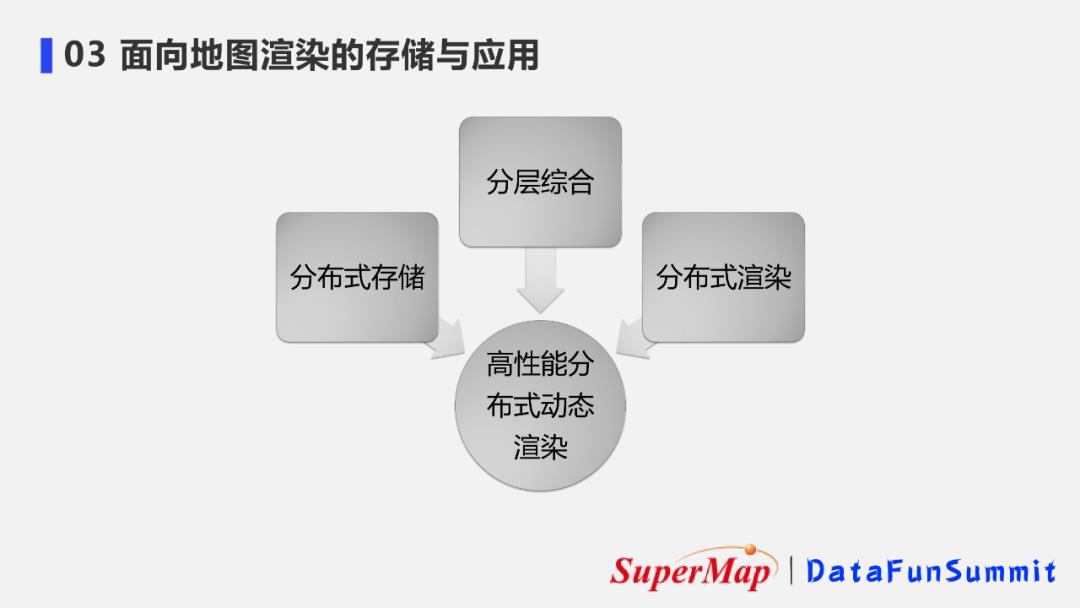
超图整合了分布式存储、分层综合和分布式渲染等技术打造成了高性能分布式动态渲染的技术体系。
3. 动态渲染技术体系-矢量分层综合技术
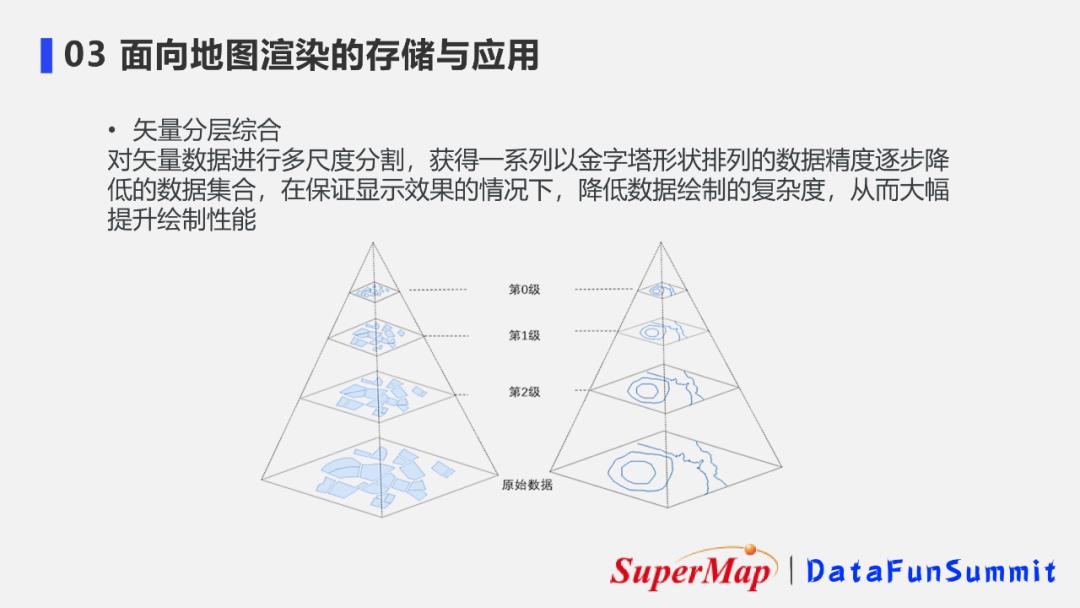
分布式矢量分层综合,其本质上是一种地图综合的技术。
在数据存储过程中,对数据建立多个级别的数据集合,使得在地图显示时,只需拉取相应级别的数据进行显示。
这种存储机制的好处在于对小比例尺级别的层数据可以单独进行数据简化来降低地理数据的复杂程度,从而在地图绘制过程中大幅提升小比例尺下的地图绘制性能。
4. 动态渲染技术体系-分布式渲染技术
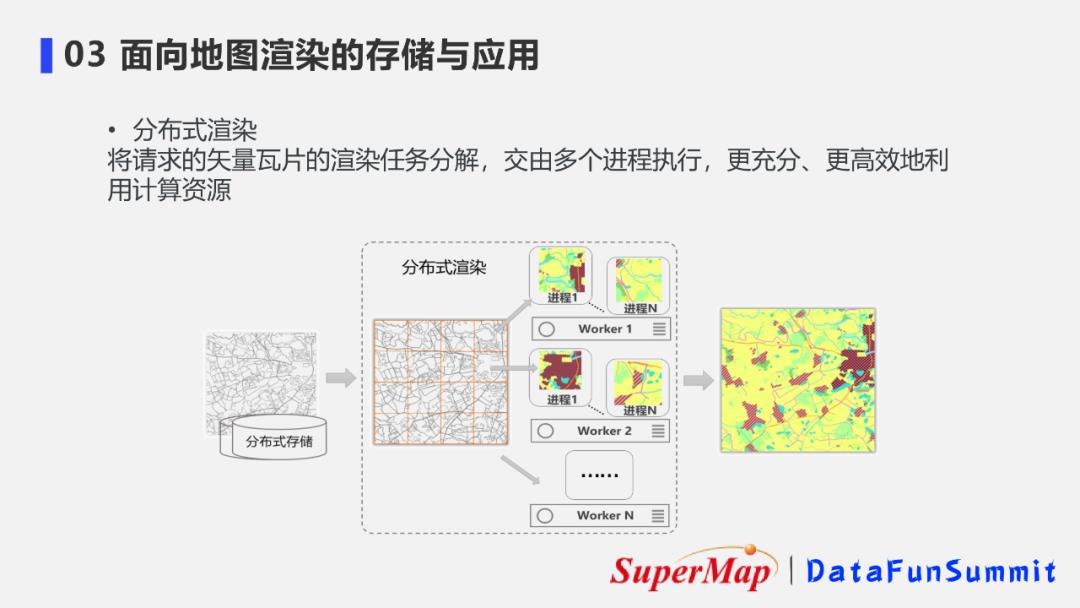
分布式渲染指将客户端请求的矢量瓦片任务分解,交给多个节点、多个进程同步执行,从而提升渲染的并行程度。
利用多个节点的共同工作来完成地图服务各个部分内容的渲染,最终在客户端展现完整的渲染内容,从而大幅减少地图服务的响应时间。
5. 分布式动态渲染应用案例1
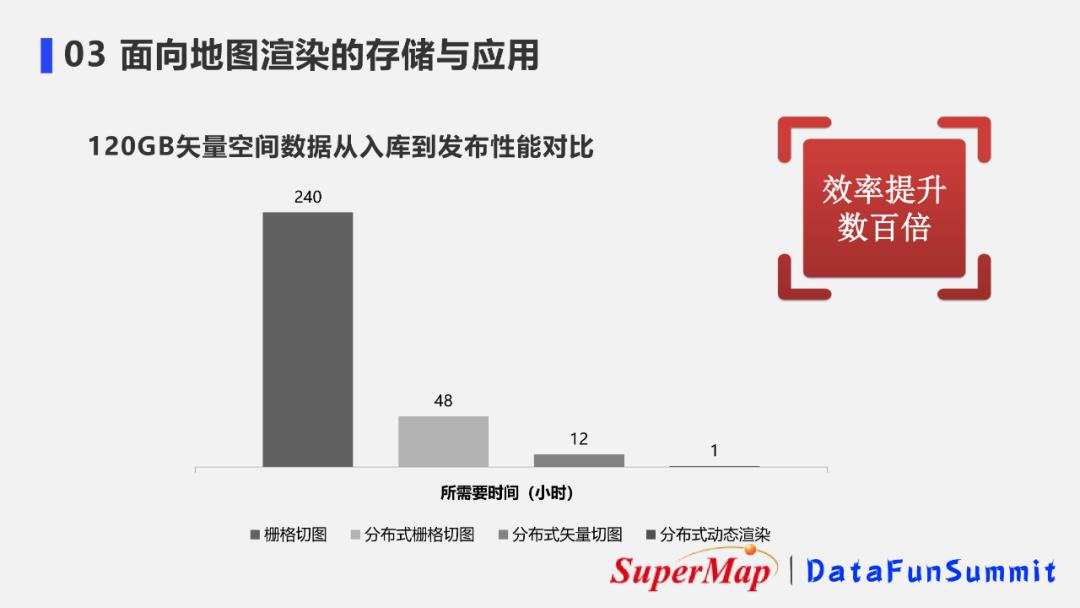
如图所示,这是一个120GB矢量空间数据地图发布性能对比,可以看到传统方法中,仅做个栅格切图就需要240h完成。
而分布式栅格切图和分布式矢量切图能够很大程度上降低叠加的耗时。
我们的动态渲染过程因为省略了切图这一步骤,可以进一步提升矢量数据地图服务发布效率,相较于栅格切图,其效率可提升数百倍。
6. 分布式动态渲染应用案例2
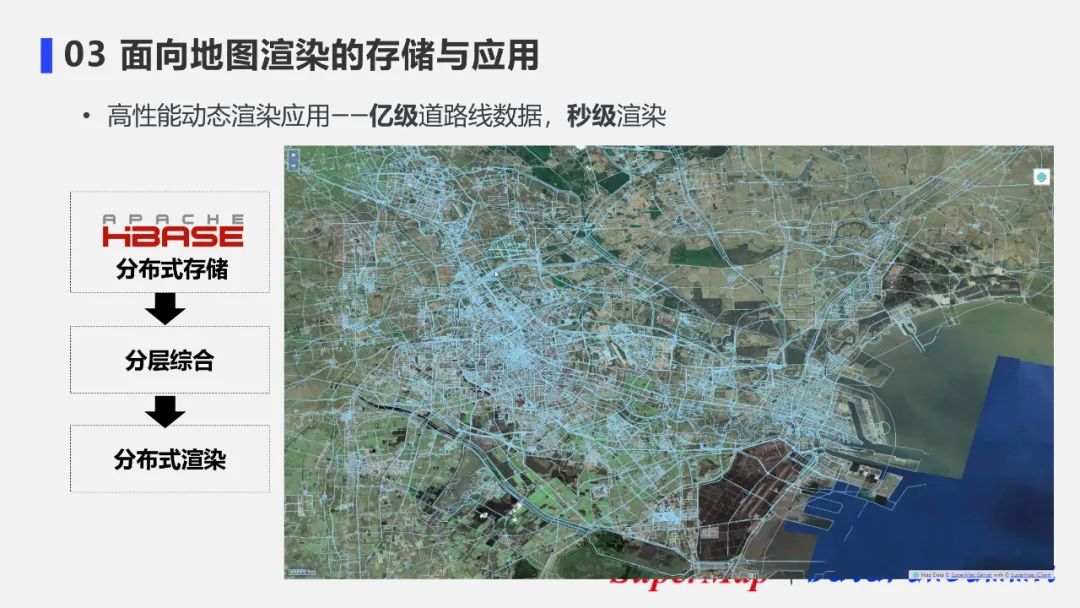
高性能动态渲染应用案例——亿级道路线数据的秒级渲染:
案例中展示的是采用10节点的HBASE集群,进行分层综合的构建和分布式的渲染,最后达到的全球道路线数据的渲染效果图。
叠加上卫星地图后,渲染效果也是非常好的。
7. 基于分布式存储的即时分析渲染
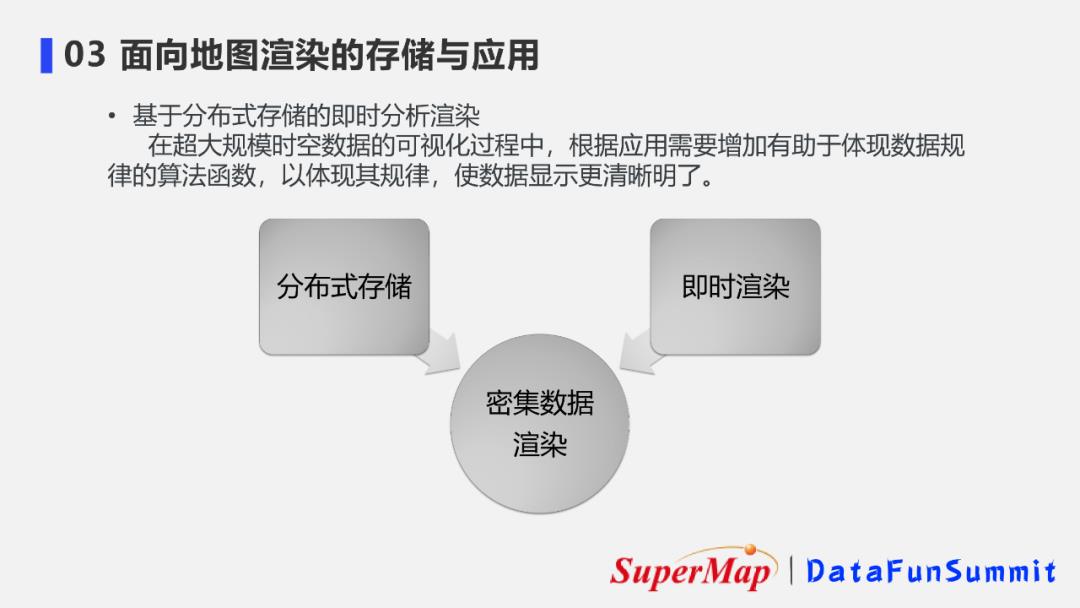
上面介绍了采用分布式技术将数据直接显示的应用案例,但当数据量达到一定规模后,若还是像前面案例中符号化展示所有数据,地图上就会显示的非常密集,无法看到数据的规律。
因此对于大规模密集数据来说,更好的可视化办法是增加一种能体现数据规律的算法函数,让我们在观察数据的过程中获取更多的信息,看的更加清晰明白。
8. 流数据即时渲染应用案例1-直接符号化显示
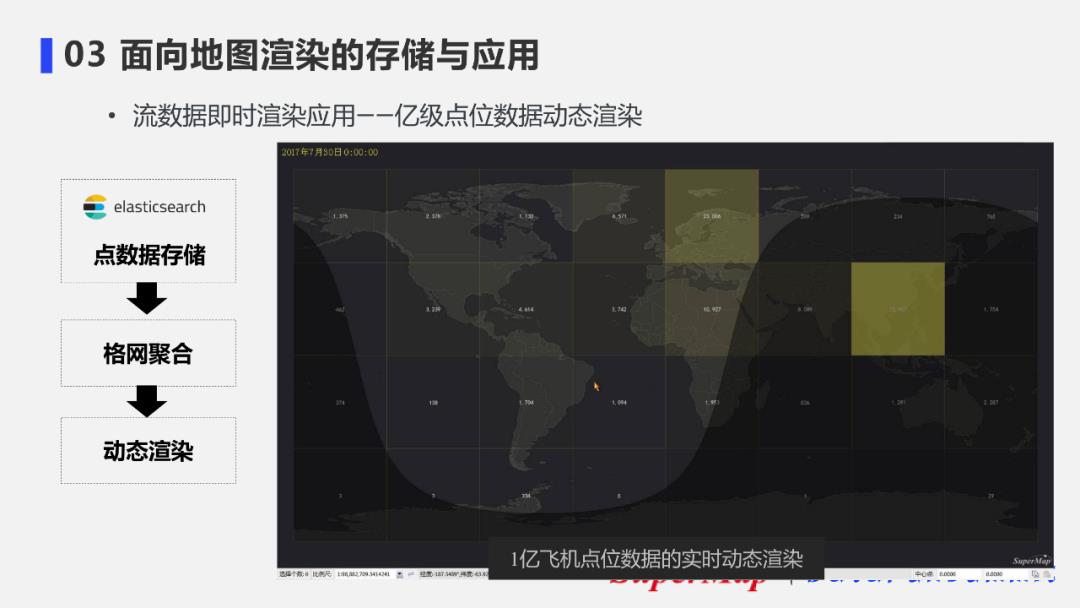
案例:存储在es数据库中的一个一亿飞机点位的实时渲染效果图。
如图所示,如采用直接符号化显示进行渲染,渲染结果将非常复杂,看不到数据规律,但如果通过格网聚合的效果进行动态渲染,就可以很轻松看到整体分布情况。
9. 流数据即时渲染应用案例1-密度分析计算显示
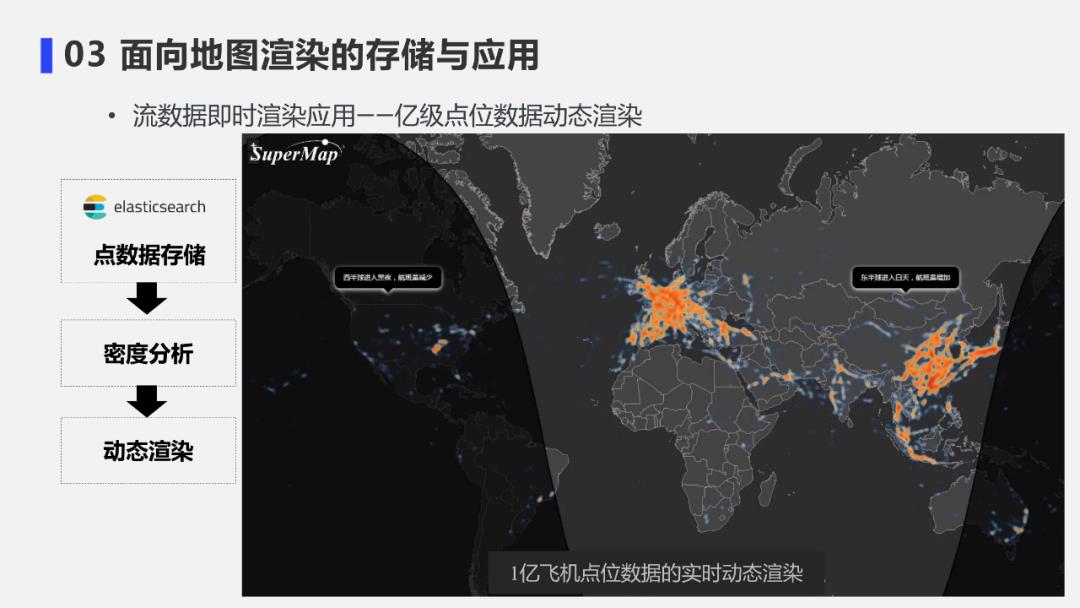
上图是对刚才的亿级的点位数据的另一渲染效果。
如采用密度分析进行即时计算,可以清楚看到点位数据分布和动态流动情况。
10. 流数据即时渲染应用案例2
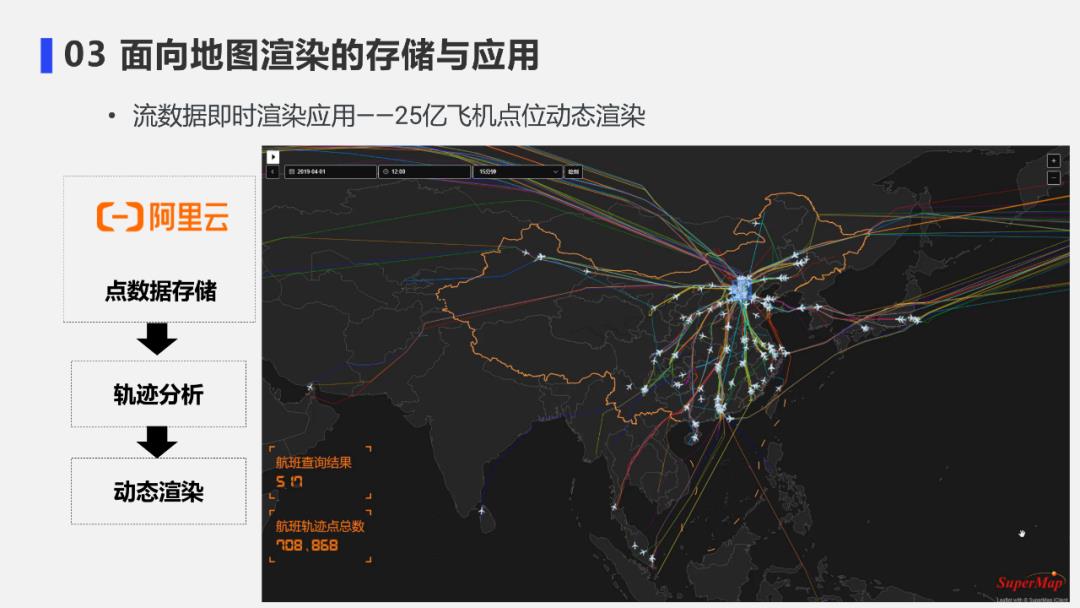
上图是与阿里云polarDB合作的飞机点位渲染效果图。
采用了轨迹分析的即时渲染,25亿个飞机点位叠加上轨迹分析结果后能够很清晰的看到各个飞机的行驶轨迹和实时位置。
04 分布式地理处理建模
对于刚才提到的分布式GIS技术,超图提供了分布式地理处理建模模块,可以让大家很方便的使用这些技术。
1. 地理处理建模产品架构
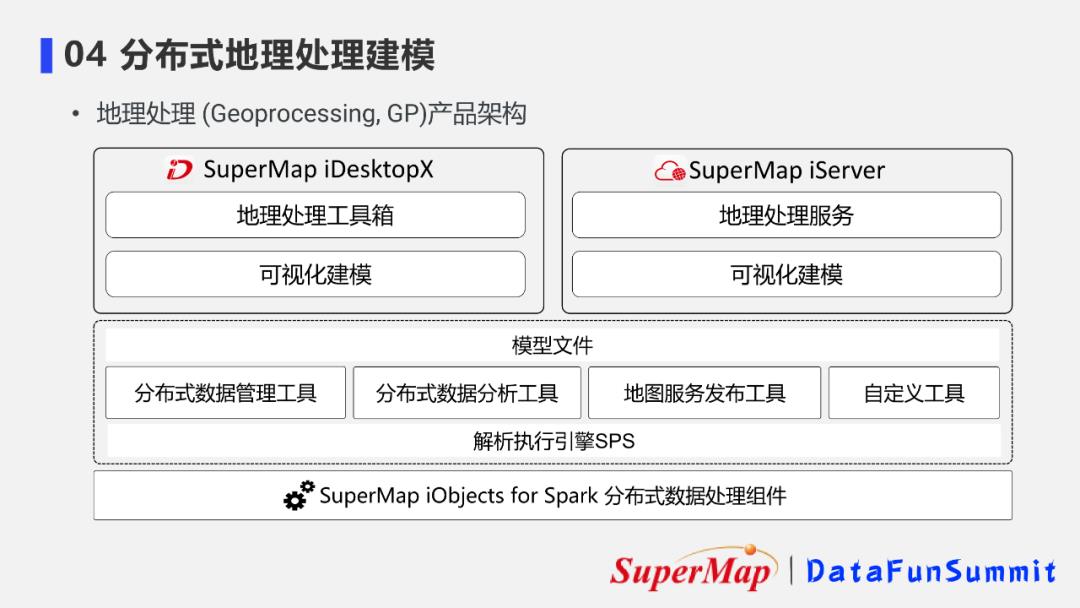
如图,这是一个地理处理的产品架构图:
- 底层通过组件产品提供分布式能力;
- 上层我们将API封装成图形化的工具,推出了一套地理处理模块。这个模块目前可以在桌面端产品和服务器端产品使用。
2. 地理处理建模界面
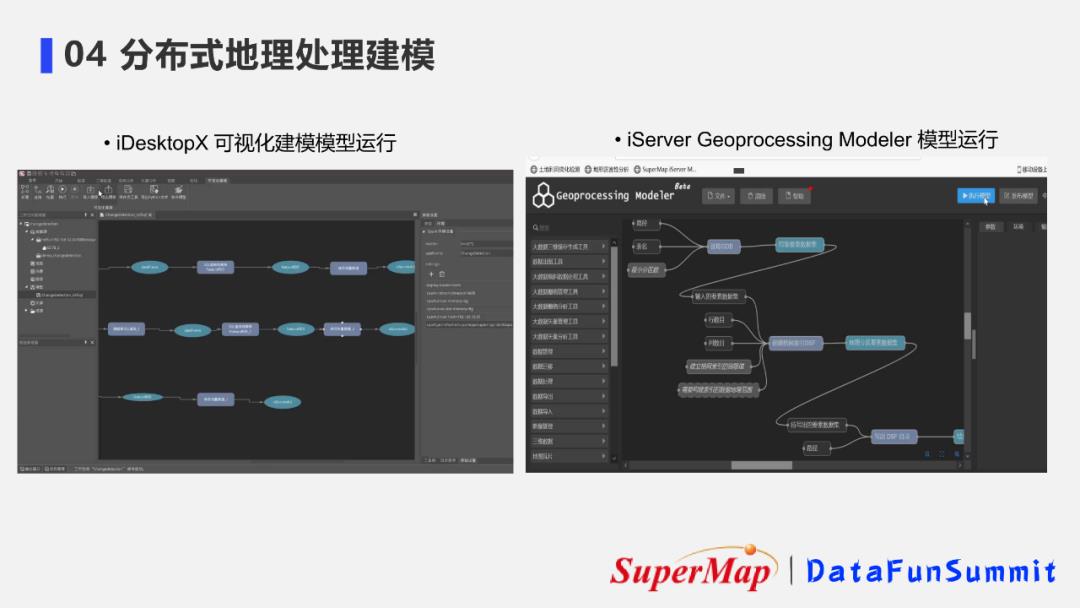
如图,这是在两个端产品上的使用界面情况。
利用图形化工作界面,进行工具编排,可以实现对空间数据的管理和分析,以及服务的发布。
超图的分布式地理处理建模特点在于:工具基于分布式架构实现,能够对接使用分布式存储的数据库和分布式计算集群。这样可以真正将传统GIS可视化建模与分布式技术达到深度融合,让GIS从业人员更加轻松享受到分布式技术带来的功能和性能上的提升。
3. 分布式地理处理建模工具介绍
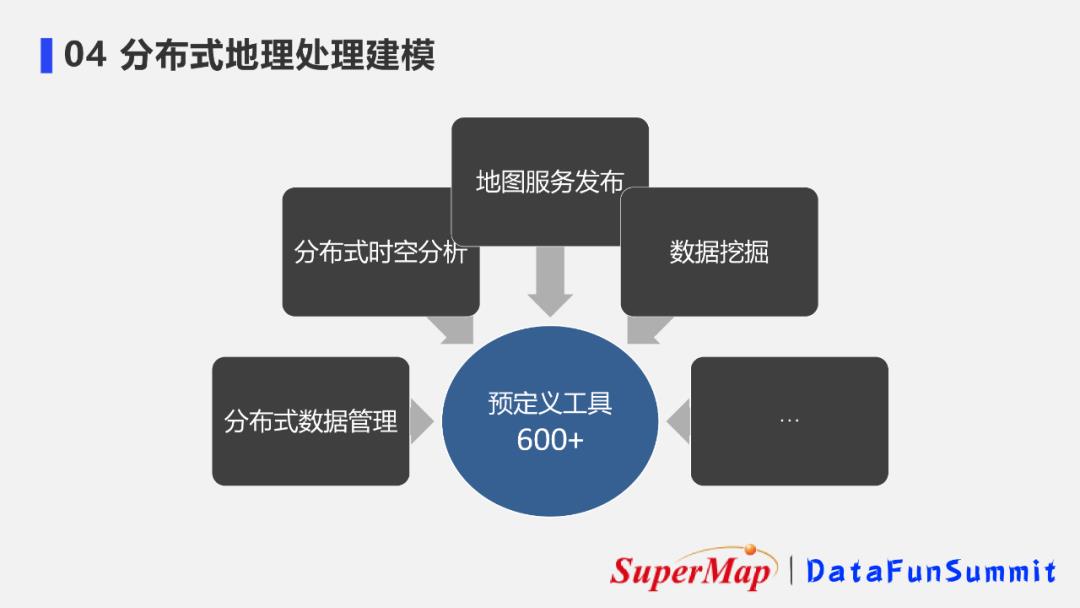
分布式地理处理建模目前提供了600多种预定义工具:
- 分布式数据管理、分布式时空分析等分布式工具
- 地图服务分布、数据挖掘等传统空间分析工具。
4. 分布式地理处理建模应用案例-批量导入1:25万基础地理数据
① 基础地理数据获取
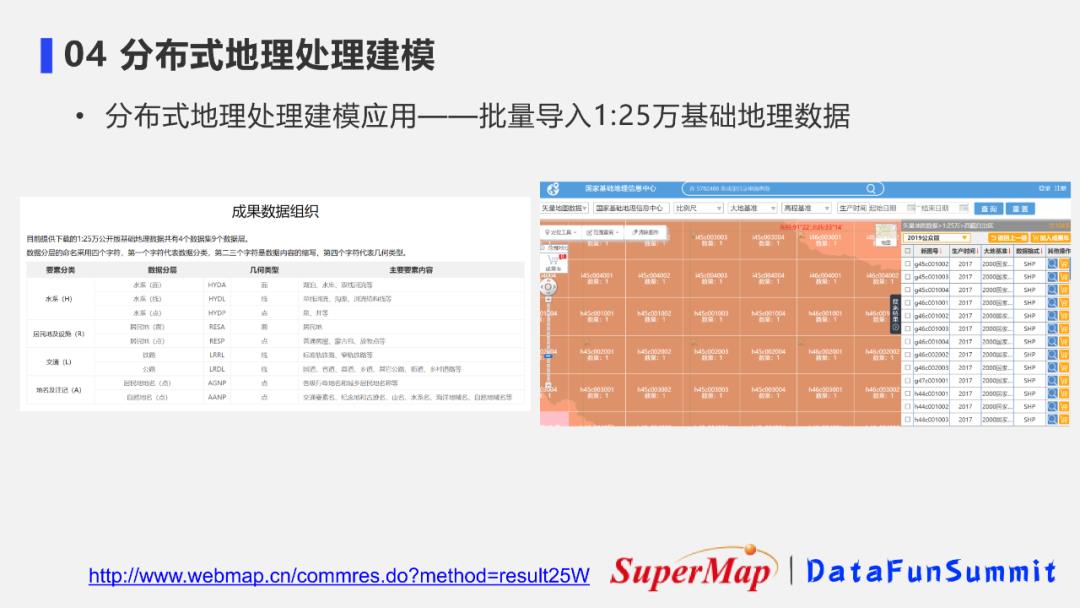

基础地理信息数据可以从国家基础地理信息中心获取。数据组织非常复杂,含600多个shp数据,存储非常零散。我们该如何将这些数据分幅导入到数据库中,来进行比较好的显示?
② 批量数据导入流程模型
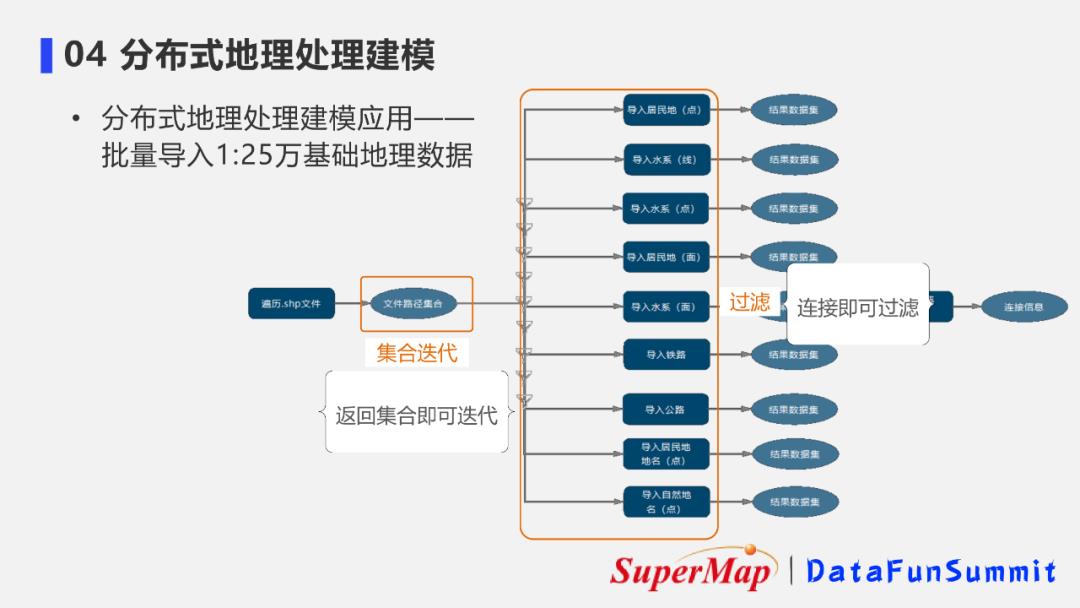
可以借助超图的分布式地理处理建模模块,构建批量数据导入的流程模型:
- 首先,迭代遍历多个数据的存储文件夹;
- 通过过滤的工具来获取各个图幅需要的对应的数据名称和数据集;
- 最终通过一个迭代的模型,可以实现刚才非常零散的、大规模的数据量的批量入库的工作。
③ 批量数据导入效果展示
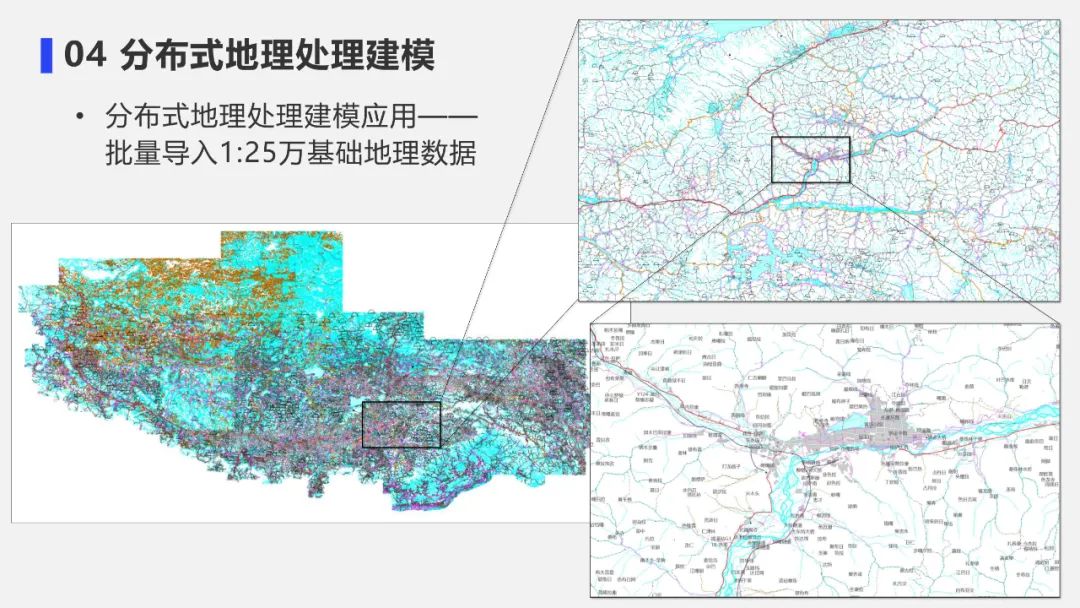
如图,这是西藏地区基础地理数据的导入效果图,可以看到图幅非常多,最终的图层得到了很好的组织管理。
5. 分布式地理处理建模应用案例2-耕地质量分析
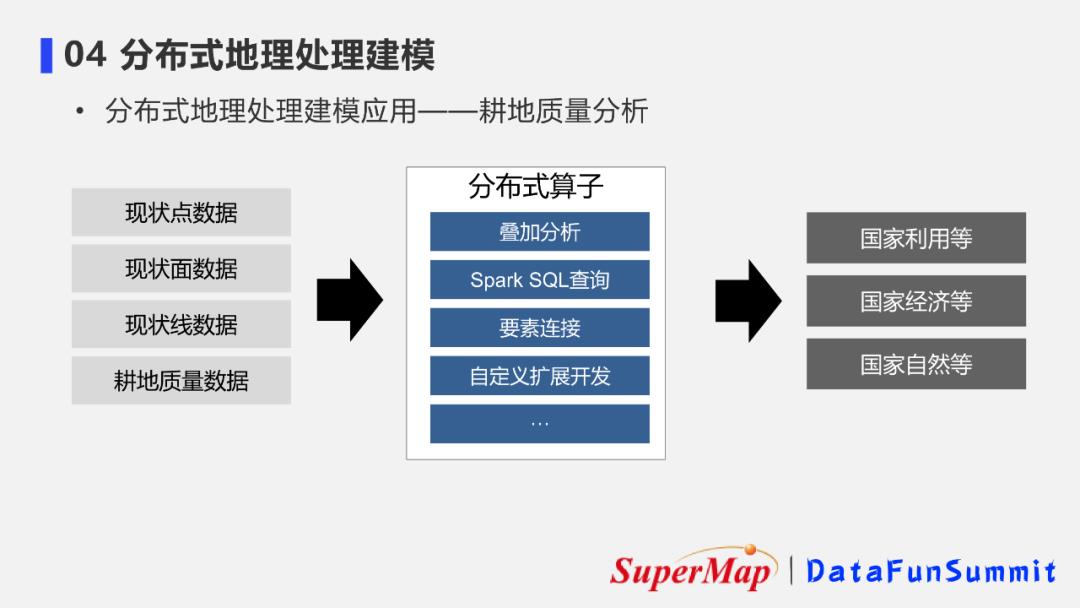
另一个分布式地理处理建模的应用案例:贵州省大数据分析平台上的耕地质量分析业务。
该业务需要使用多个空间分析的算子共同结合才能算出耕地的质量等级。
① 地理处理建模服务器端搭建耕地质量分析模型
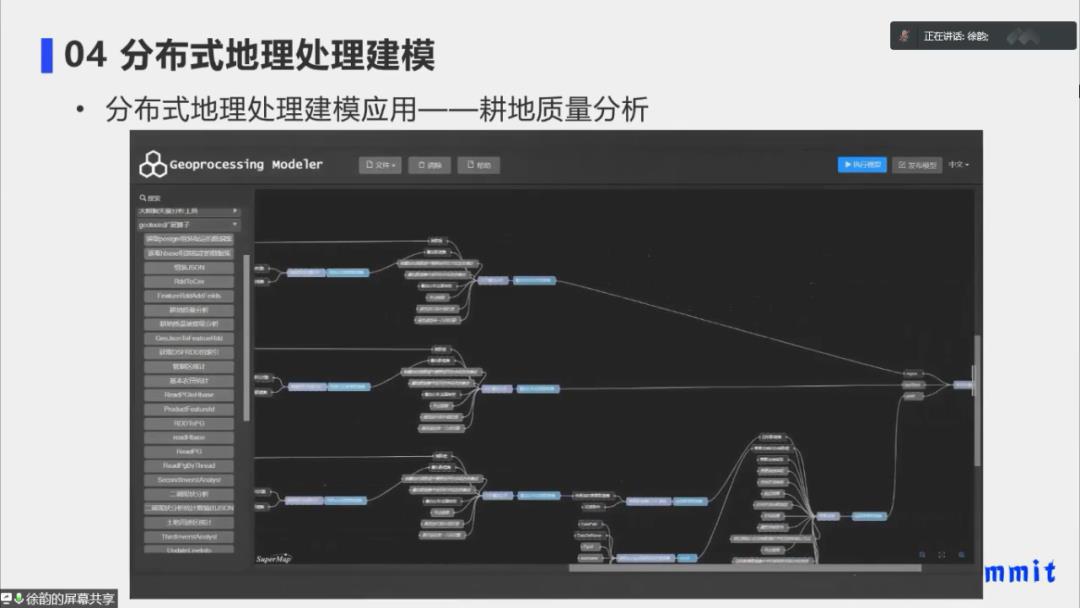
我们可以在服务器端的地理处理建模界面搭建我们需要的耕地质量模型,这是当时使用到的耕地质量模型。
② 搭建模型用于耕地质量分析
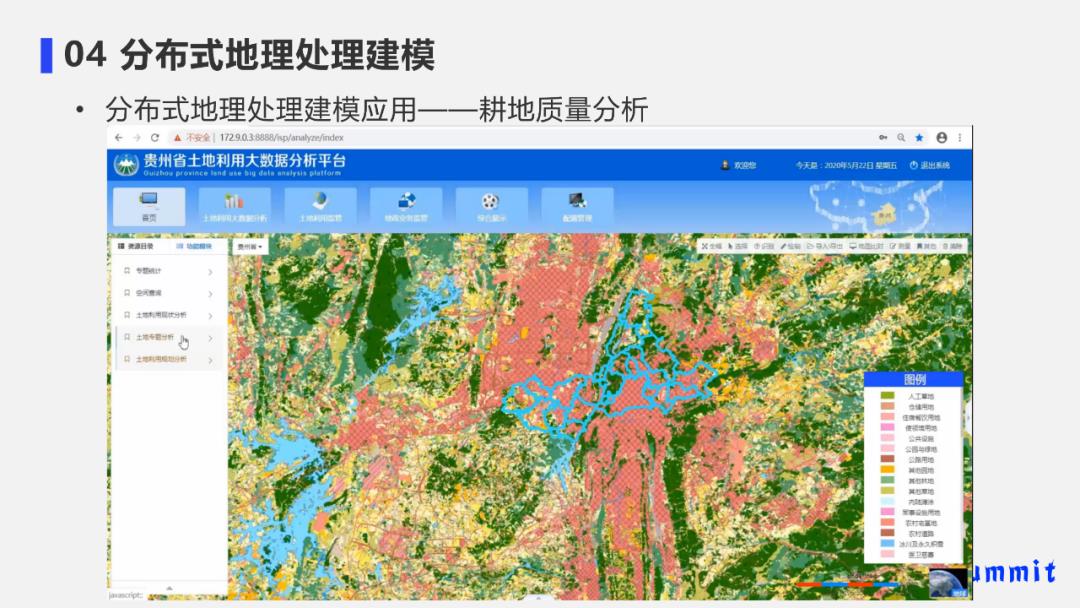
在前端的主页利用大数据分析平台中的耕地质量分析算法,点击运行后,后台就会调用前面提到的复杂模型。
该模型后台已经构建完成,前端人员可以直接使用进行分析,从而得到耕地质量等级。
05 总结
1. 解决“两难两慢”难题
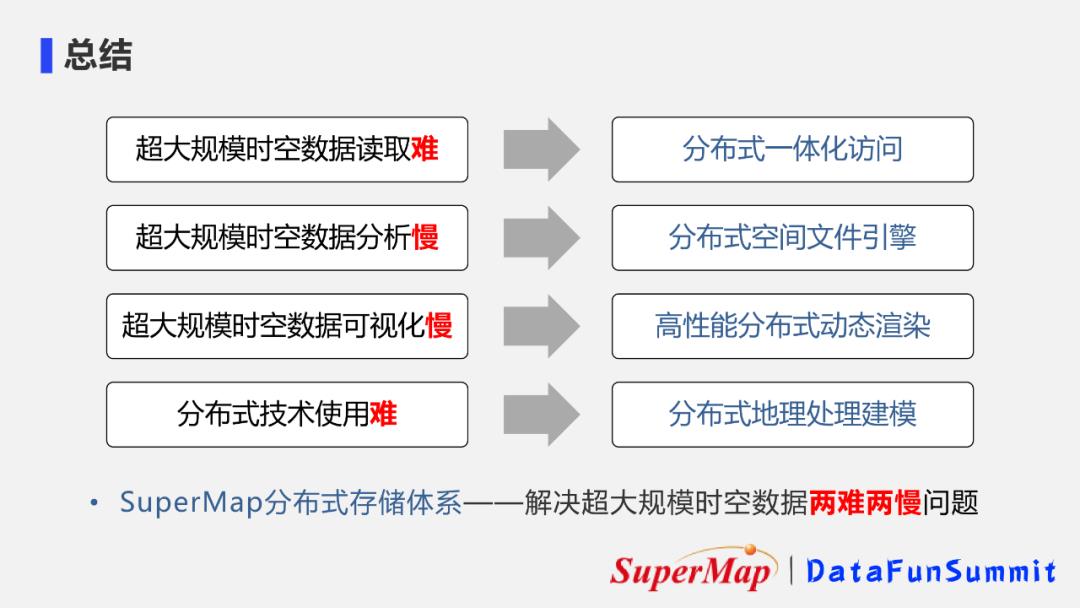
超图的分布式存储能够解决超大规模时空数据的几个难题:读取难;分析慢;可视化慢;分布式技术使用难。
通过分布式一体化访问、分布式空间文件引擎、高性能分布式动态渲染和分布式地理数据建模技术,能够解决超大规模时空数据“两难两慢”的问题。
2. 行业评价

超图的分布式存储技术得到了多位院士专家的评价:整体国际先进部分国际领先的科技水平。
除此之外,我们还得到了2020年地理信息科技进步的特等奖,排名第一的好成绩。
3. 行业贡献


最后,我们还撰写了《大数据地理信息系统:原理、技术与应用》教材,促进了我国大数据地理信息产业发展,也为储备人才培养提供了前沿资料。如果大家感兴趣,也欢迎大家去订阅教材或与我们联系。
https://www.supermap.com/zh-cn/a/product/10i-tec-2-2020.html
超图大数据产品的网页连接如上,欢迎大家前去下载超图的产品,如果有问题可以与我们的技术人员继续沟通~
06 提问环节
Q:地理信息的抽象层面是什么?
A:我理解的是我们需要如何去进行地理信息的表达。在GIS行业中,以点线面符号化的形式去表达。GIS就是对空间实体的抽象表达,整个GIS数据模型都是对地理信息的抽象化的表达方式。
Q:Spark上做空间数据分析是自然的系统还是基于genalspark等开源系统改造的?对spatialjion有哪些特殊优化呢?
A:超图的分布式计算是基于spark框架自研的计算体系。空间连接算法逻辑是已经固定的,在GIS行业中该如何去计算是已经固定的,但我们的API大家感兴趣的话,可以去我们的产品当中去查看。空间连接有不同的连接方式,也有非常高的连接性能,也有一些具体的应用案例,大家都可以在我们的产品文档中获得。
Q:可以抽象为点线面的数据都可以用地理信息系统记录?
A:对的,地理信息系统就是去完成点线面数据的管理、分析、可视化的技术。
以上是关于超大规模时空数据的分布式存储与应用的主要内容,如果未能解决你的问题,请参考以下文章