PANet:基于金字塔注意力网络的图像超分辨率重建(Pytorch实现)
Posted __Elwin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PANet:基于金字塔注意力网络的图像超分辨率重建(Pytorch实现)相关的知识,希望对你有一定的参考价值。
PANet:基于金字塔注意力网络的图像超分辨率重建
[!] 为了提高代码的可读性,本文模型的具体实现与原文具有一定区别,因此会造成性能上的差异
文章目录
1.相关资料
2.简介
- PANet(Pyramid Attention with Simple Network Backbones)是一种基于图像恢复金字塔注意力模块的图像修复模型,它能够从多尺度特征金字塔种提取到长距离与短距离的特征关系。
- 受降采样能够有效减少压缩伪影等图像噪声的启发,作者所提出的金字塔利用不同采样倍数的特征图来相互传递注意力信号,以更灵活的方式来借用不同特征尺寸之间的“干净”信息。
- 作者只在一个简单的前馈链接网络中加入了一个金字塔注意力模块,就在绝大多数图像修复任务中达到了SOTA。(这样看来模块确实牛逼)
3.模型结构
直接上图
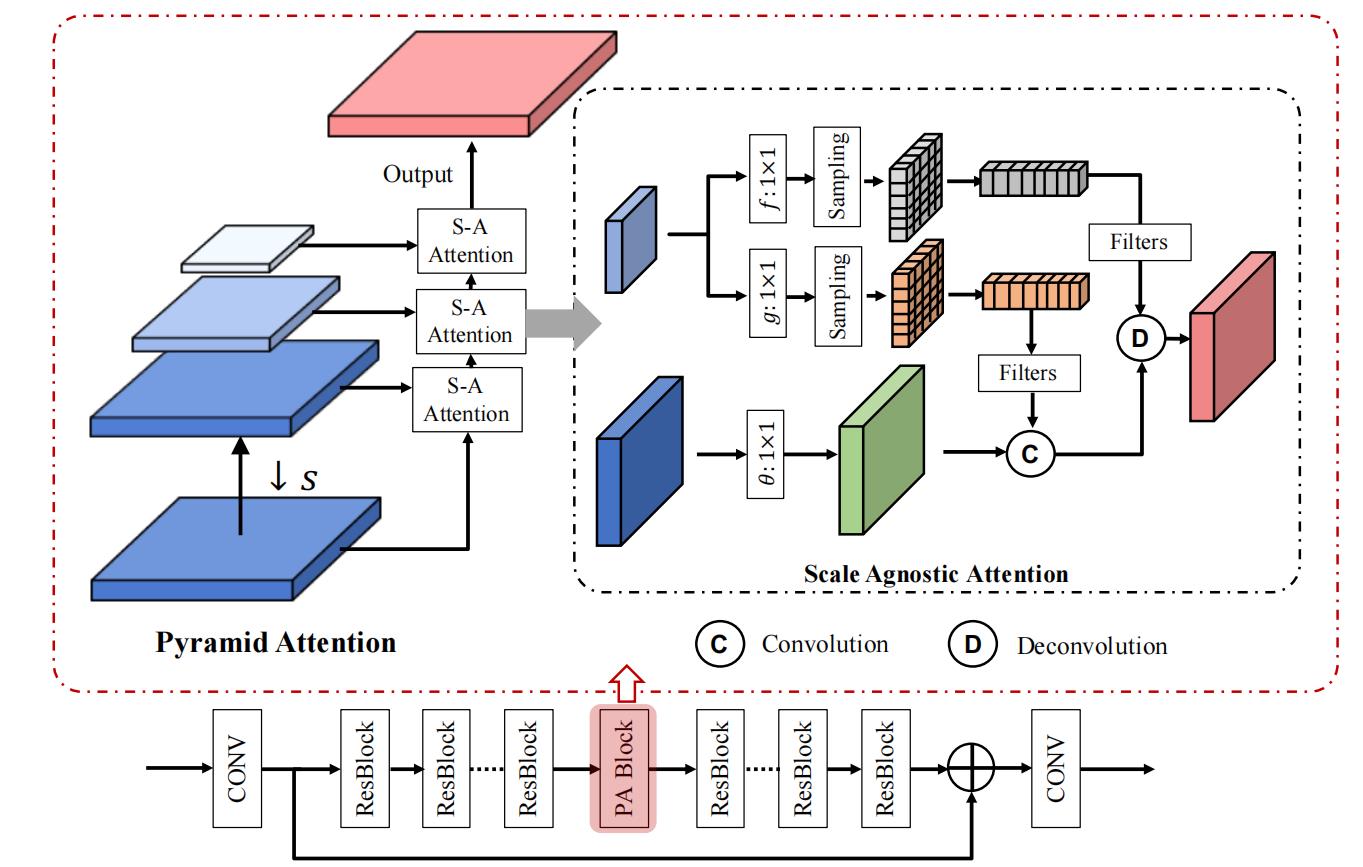
- 图上面部分就是传说中的金字塔注意力模块,图下面部分就是PANet的结构(这个结构和SRResNet怪像的,可以参考我的相关文章:SRResNet和SRGAN)
- 金字塔注意力模块的结构分为两个部分:金字塔采样环节和S-A Attention。金字塔采样环节就是简单的降采样处理,根据源代码来看,作者使用的是双二次下采样的方法。
- S-A Attention的结构参考了NLP中最经典的注意力机制结构,即构建了Q,K,V三种特征图来捕获图像在不同尺寸中的信息。与其他注意力机制不同的是,S-A Attention将注意力机制中的按元素相乘环节改成将Q和K特征图作为卷积核(即图中浅蓝色特征层出来的两个特征图)来与V特征图进行卷积/反卷积操作。
4.项目实践
在这里我会一步一步教大家做一个能够成功运行的PANet,完整的代码也会很快推出。
4.1 准备工作
-
笔者使用的工作环境如下所示:
系统:Windows 10 CPU:Intel Core i9-10850K GPU:GeForce RTX 3090 -
实现代码所需要准备的库为:
Pytorch OpenCV Numpy Torchvision -
本文使用的是COCO 2017数据集,其中包含了123,403张照片,大家可以根据自己的需要来使用自己的数据集。
4.2 具体实现
为了方便阅读,部分代码已标注中文注释,而且全部放进了一个代码文件中
- 完整版代码支持重新打开代码自动恢复到上次训练的功能,只需要关注笔者即可获得:传送门
4.2.1 导入项目所需库
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader,Dataset,SubsetRandomSampler
import torch.optim as optim
from torchvision import utils as vutils
from torchvision.utils import save_image
import os
import cv2
import random as ra
import numpy as np
import math
4.2.2 构建数据集
class PreprocessDataset(Dataset):
def __init__(self,path,size = 96):
super().__init__()
self.size = size #高清图像的尺寸,这里默认为96x96
self.allImgs = list()
for root,dirs,files in os.walk(path):
self.allImgs = [os.path.join(root,file) for file in files] #获取图像的地址
def __len__(self):
return len(self.allImgs)
def __getitem__(self,index):
img = self.allImgs[index]
img = cv2.imread(img)
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
height,width,_ = img.shape
xStart = ra.randint(0,width-self.size-1)
yStart = ra.randint(0,height-self.size-1)
img = img[yStart:self.size + yStart,xStart:self.size + xStart,:] #随机裁剪图像
if ra.random() > 0.5:
img = cv2.flip(img,1) #有50%几率反转图像
hr = torch.tensor(np.transpose(img,(2,0,1)))/255.0
hr = (hr - 0.5)/0.5 #像素标准化
lr = F.max_pool2d(hr,2) #使用最大池化来获得下采样图片
return hr,lr
-
构建完数据集类后,我们可以很方便地构建对应的Dataloader。在这里我只构建了训练集,并没有构建测试集。
path = '你的数据集文件路径' dataset = PreprocessDataset(path,size = 96) trainData = DataLoader(dataset,batch_size = 32,num_workers = 4,shuffle = True)
4.2.3 构建网络模型
# 特征金字塔部分
- 这里直接改进了原作者的金字塔注意力模块代码,因此代码风格会与其他部分有一定差异。
def extract_image_patches(images, ksizes, strides, rates, padding='same'): """ Extract patches from images and put them in the C output dimension. :param padding: :param images: [batch, channels, in_rows, in_cols]. A 4-D Tensor with shape :param ksizes: [ksize_rows, ksize_cols]. The size of the sliding window for each dimension of images :param strides: [stride_rows, stride_cols] :param rates: [dilation_rows, dilation_cols] :return: A Tensor """ assert len(images.size()) == 4 assert padding in ['same', 'valid'] batch_size, channel, height, width = images.size() if padding == 'same': images = same_padding(images, ksizes, strides, rates) elif padding == 'valid': pass else: raise NotImplementedError('Unsupported padding type: {}.\\ Only "same" or "valid" are supported.'.format(padding)) unfold = torch.nn.Unfold(kernel_size=ksizes, dilation=rates, padding=0, stride=strides) patches = unfold(images) return patches # [N, C*k*k, L], L is the total number of such blocks def reduce_sum(x, axis=None, keepdim=False): if not axis: axis = range(len(x.shape)) for i in sorted(axis, reverse=True): x = torch.sum(x, dim=i, keepdim=keepdim) return x def same_padding(images, ksizes, strides, rates): assert len(images.size()) == 4 batch_size, channel, rows, cols = images.size() out_rows = (rows + strides[0] - 1) // strides[0] out_cols = (cols + strides[1] - 1) // strides[1] effective_k_row = (ksizes[0] - 1) * rates[0] + 1 effective_k_col = (ksizes[1] - 1) * rates[1] + 1 padding_rows = max(0, (out_rows-1)*strides[0]+effective_k_row-rows) padding_cols = max(0, (out_cols-1)*strides[1]+effective_k_col-cols) # Pad the input padding_top = int(padding_rows / 2.) padding_left = int(padding_cols / 2.) padding_bottom = padding_rows - padding_top padding_right = padding_cols - padding_left paddings = (padding_left, padding_right, padding_top, padding_bottom) images = torch.nn.ZeroPad2d(paddings)(images) return images def default_conv(in_channels, out_channels, kernel_size,stride=1, bias=True): return nn.Conv2d( in_channels, out_channels, kernel_size, padding=(kernel_size//2),stride=stride, bias=bias) class BasicBlock(nn.Sequential): def __init__( self, conv, in_channels, out_channels, kernel_size, stride=1, bias=True, bn=False, act=nn.PReLU()): m = [conv(in_channels, out_channels, kernel_size, bias=bias)] if bn: m.append(nn.BatchNorm2d(out_channels)) if act is not None: m.append(act) super(BasicBlock, self).__init__(*m) class PyramidAttention(nn.Module): def __init__(self, level=5, res_scale=1, channel=64, reduction=2, ksize=3, stride=1, softmax_scale=10, average=True, conv=default_conv): super(PyramidAttention, self).__init__() self.ksize = ksize self.stride = stride self.res_scale = res_scale self.softmax_scale = softmax_scale self.scale = [1-i/10 for i in range(level)] self.average = average escape_NaN = torch.FloatTensor([1e-4]) self.register_buffer('escape_NaN', escape_NaN) self.conv_match_L_base = BasicBlock(conv,channel,channel//reduction, 1, bn=False, act=nn.PReLU()) self.conv_match = BasicBlock(conv,channel, channel//reduction, 1, bn=False, act=nn.PReLU()) self.conv_assembly = BasicBlock(conv,channel, channel,1,bn=False, act=nn.PReLU()) def forward(self, input): res = input #theta match_base = self.conv_match_L_base(input) shape_base = list(res.size()) input_groups = torch.split(match_base,1,dim=0) # patch size for matching kernel = self.ksize # raw_w is for reconstruction raw_w = [] # w is for matching w = [] #build feature pyramid for i in range(len(self.scale)): ref = input if self.scale[i]!=1: ref = F.interpolate(input, scale_factor=self.scale[i], mode='bicubic', align_corners=True,recompute_scale_factor=True) #feature transformation function f base = self.conv_assembly(ref) shape_input = base.shape #sampling raw_w_i = extract_image_patches(base, ksizes=[kernel, kernel], strides=[self.stride,self.stride], rates=[1, 1], padding='same') # [N, C*k*k, L] raw_w_i = raw_w_i.view(shape_input[0], shape_input[1], kernel, kernel, -1) raw_w_i = raw_w_i.permute(0, 4, 1, 2, 3) # raw_shape: [N, L, C, k, k] raw_w_i_groups = torch.split(raw_w_i, 1, dim=0) raw_w.append(raw_w_i_groups) #feature transformation function g ref_i = self.conv_match(ref) shape_ref = ref_i.shape #sampling w_i = extract_image_patches(ref_i, ksizes=[self.ksize, self.ksize], strides=[self.stride, self.stride], rates=[1, 1], padding='same') w_i = w_i.view(shape_ref[0], shape_ref[1], self.ksize, self.ksize, -1) w_i = w_i.permute(0, 4, 1, 2, 3) # w shape: [N, L, C, k, k] w_i_groups = torch.split(w_i, 1, dim=0) w.append(w_i_groups) y = [] for idx, xi in enumerate(input_groups): #group in a filter wi = torch.cat([w[i][idx][0] for i in range(len(self.scale))],dim=0) # [L, C, k, k] #normalize max_wi = torch.max(torch.sqrt(reduce_sum(torch.pow(wi, 2), axis=[1, 2, 3], keepdim=True)), self.escape_NaN) wi_normed = wi/ max_wi #matching xi = same_padding(xi, [self.ksize, self.ksize], [1, 1], [1, 1]) # xi: 1*c*H*W yi = F.conv2d(xi, wi_normed, stride=1) # [1, L, H, W] L = shape_ref[2]*shape_ref[3] yi = yi.view(1,wi.shape[0], shape_base[2], shape_base[3]) # (B=1, C=32*32, H=32, W=32) # softmax matching score yi = F.softmax(yi*self.softmax_scale, dim=1) if self.average == False: yi = (yi == yi.max(dim=1,keepdim=True)[0]).float() # deconv for patch pasting raw_wi = torch.cat([raw_w[i][idx][0] for i in range(len(self.scale))],dim=0) yi = F.conv_transpose2d(yi, raw_wi, stride=self.stride,padding=1)/4. y.append(yi) y = torch.cat(y, dim=0)+res*self.res_scale # back to the mini-batch return y
# 模型部分
-
PANet使用的是SRResNet的骨干
class ResBlock(nn.Module): def __init__(self,inChannals): super().__init__() self.model = nn.Sequential( nn.Conv2d(inChannals,inChannals,kernel_size = 1,bias = False), nn.BatchNorm2d(inChannals), nn.ReLU(inplace = True), nn.Conv2d(inChannals,inChannals,kernel_size = 3,stride = 1, padding = 1,bias = False,padding_mode = 'reflect'), nn.BatchNorm2d(inChannals) ) def forward(self,input): return F.relu(input + self.model(input),inplace = True) class Sequential(nn.Sequential): def __init__(self,inChannals,blockNum = 8): seq = [ResBlock(inChannals) for _ in range(blockNum)] seq.insert(int(blockNum/2),PyramidAttention(channel=inChannals, level=4)) super().__init__(*seq) class Model(nn.Module): def __init__(self,channals = 64,blockNum = 6