一个性能问题的分析和妥协过程
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个性能问题的分析和妥协过程相关的知识,希望对你有一定的参考价值。
前几天一个朋友在做一个项目的性能项目,提到了 TPS 在 120 的候,Oracle RAC 两台机器达到 70 %的 CPU 使用率。在我看了数据之后。大体有如下的判断:
- 应用服务器本身在当前的场景下没有出现明显的性能瓶颈。
- JVM 回收也很健康。
- 网络通信也很正常。
- 压力工具端也没有问题。
- 数据库中有些问题。
来看看几个数据:

上图看到 DB Time 很高。DB Time 是前台 session 调用 DB 消耗时间的总和。
下面再看几个数据:
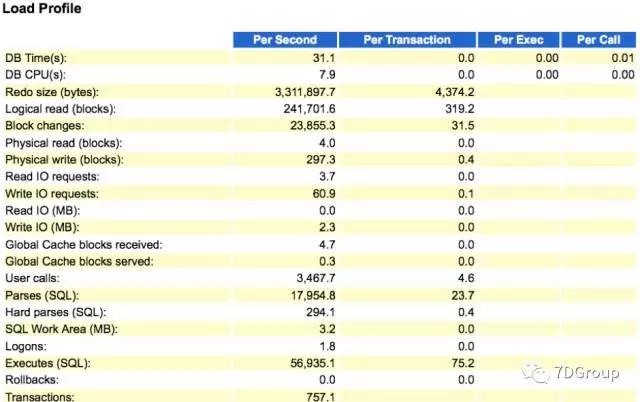

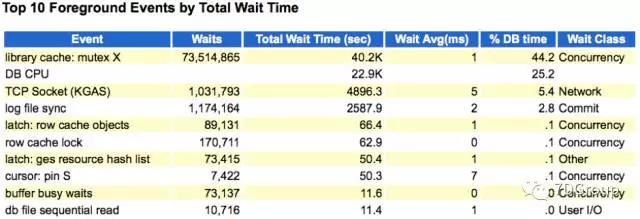
从面的图中可以看到系统硬解析很高。同时在前台的 TOP 10 的耗时的事件中也看到了libararycache:mutex X比较高。这个值和硬解析也是有关系的。所以考虑到的第一个严重的性能问题就是硬解析。
当然下面还有一个TCP Socke t(KGAS)的事件也是比较大的,这个事情后面再说。
所以我跟那个朋友说,你这个系统硬解析太高,导致现在CPU使用率高。要先解决这个TOP1的问题。
在我觉得我交差了之后,过了一个星期。那个朋友又来找我了,说硬解析的问题没解决。但是修改了一个业务逻辑,让一个SQL不执行了。之前这个 SQL 也是执行的挺多的次数,导致了数据库有锁存在。现在不执行了。TPS上了200。
我说那硬解析怎么办呢?他们说那就不管了吧。业务要改起来也比较麻烦。
我说你们TOP1的问题没有解决,现在这个问题怎么发现的呢。他说是根据业务的执行步骤耗时来看的。于是我说把新的AWR报告给我看一眼。于是看到了如下信息:
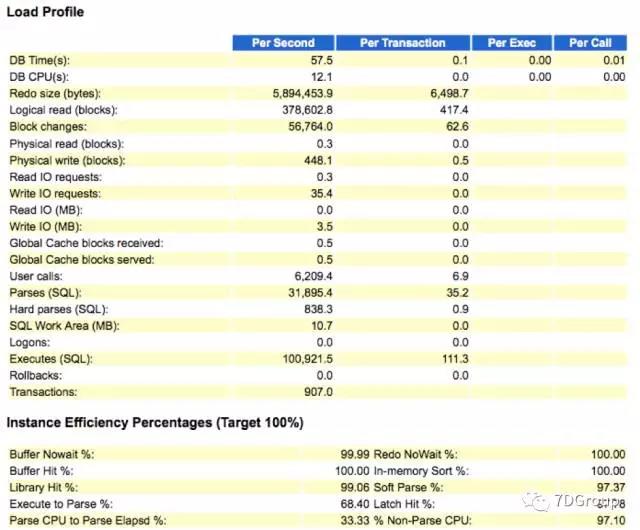
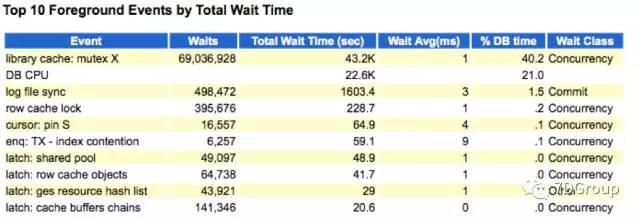
我们可以看到这个图中的 TCP Socket(KGAS) 事件没有了。那这个事件是什么意思呢?
其实它是一个网络事件,和数据库本身的性能并无太大关系。但是他们解决 SQ L的业务逻辑的时候这个等待事件也消失了,可见网络的传输少了很多。
为了证实自己的判断。我还和 Oracle 大牛罗老师咨询了下。避免自己的知识还是不够完整导致判断的偏差。
罗老师很认真的给我了一些回复:

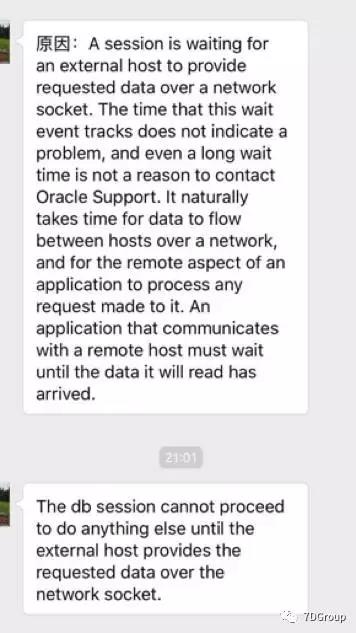
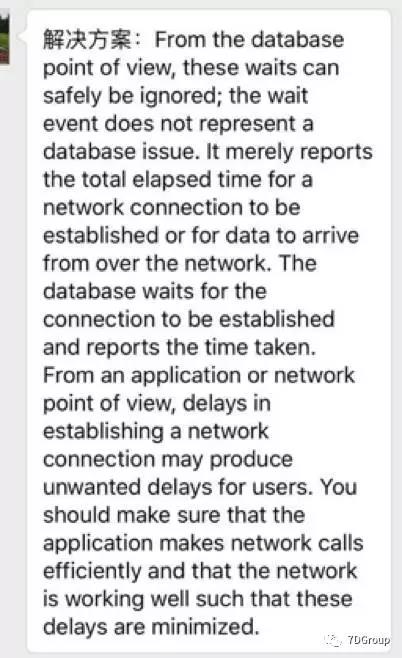
看了之后也就是说,这个其他和数据库没关系。就是网络的问题。看来是这个应用逻辑的修改减少了网络的传输量。
再对比硬解析,可以看到,第二次的结果中硬解析更多了。达到了 800 多。而现在这个应用因为TPS可以达到业务的要求,现在也就这样放着了。并且另一个原因是修改起来成本太高。所以系统在这样带着性能问题运行下去,也就只能默默接受了。
想想国内的项目中有多少是性能问题对领导政绩任务的时间和修改成本妥协了。这个问题修改起来复杂吗?从技术上来说,并不复杂。但是性能是个综合考虑的事情。
做性能分析的人要做到的就是问题到底在哪里?要怎么修改?但是具体要不要改,那就要看各利益方的权衡了。
以上是关于一个性能问题的分析和妥协过程的主要内容,如果未能解决你的问题,请参考以下文章